

It is common for RAG systems to produce inaccurate/unhelpful responses.
Today, let’s look at how we can improve this using Cleanlab Codex, which is commonly used in production systems to automatically detect and resolve RAG inaccuracies.
Tech stack:
LlamaIndex for orchestration
Milvus as the self-hosted vectorDB
Cleanlab Codex to validate the response
OpenRouterAI to access the latest Qwen3 C
Here's the workflow:
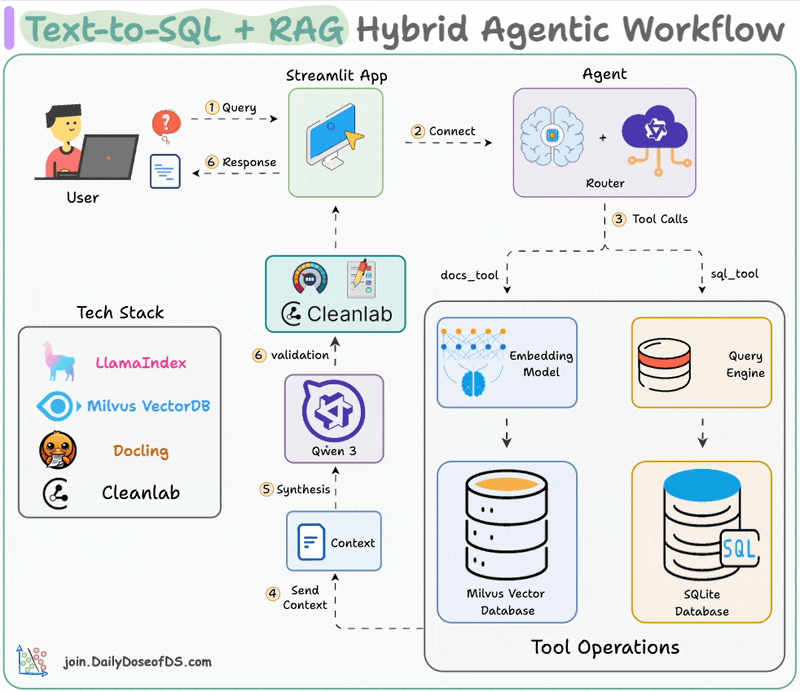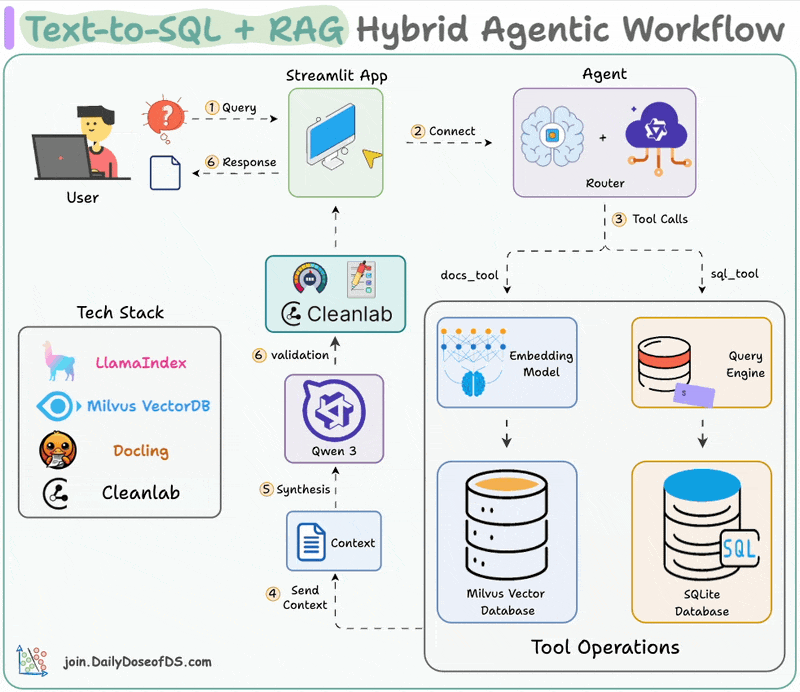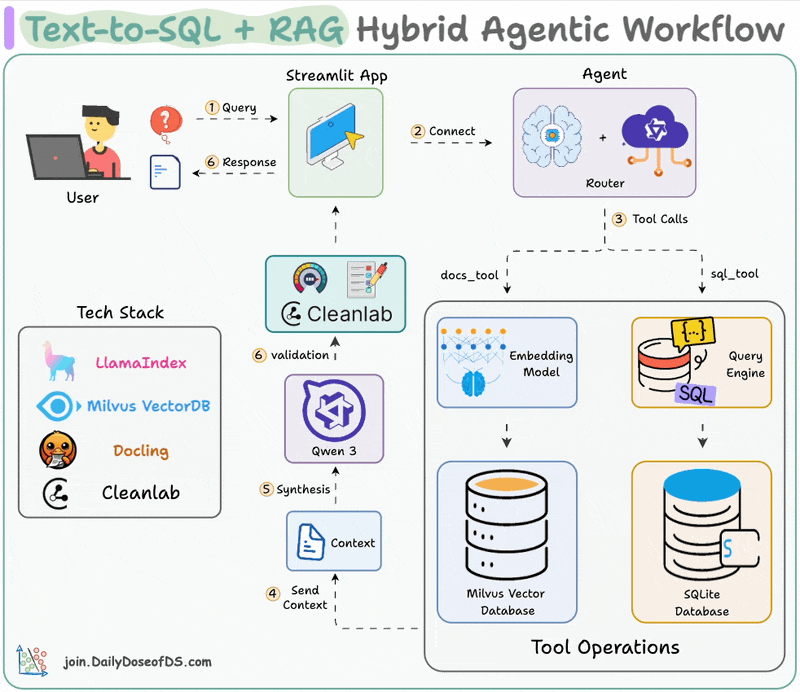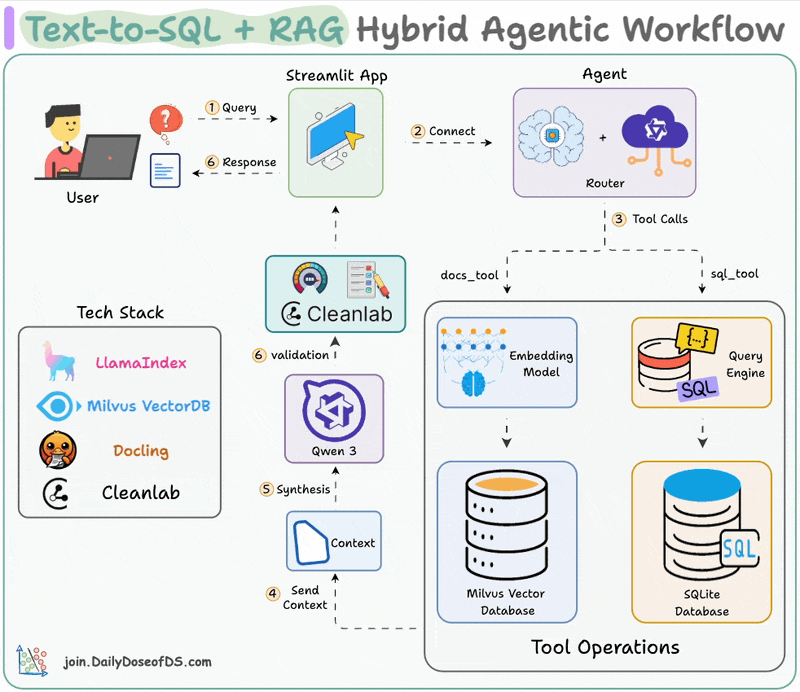
LLM processes the query to select a tool
Converts the query into the right format (text/SQL)
Executes the tool and fetch the output
Generates a response with enriched context
Validates the response using Cleanlab's Codex
Now, let's see the code!
Set up LLM
We'll use the latest Qwen3, served via OpenRouter.
Ensure the LLM supports tool calling for seamless execution.

Set up SQL Query engine
A Natural Language to SQL Engine turns plain queries into SQL commands, enabling easy data interaction.

Set up RAG Query engine
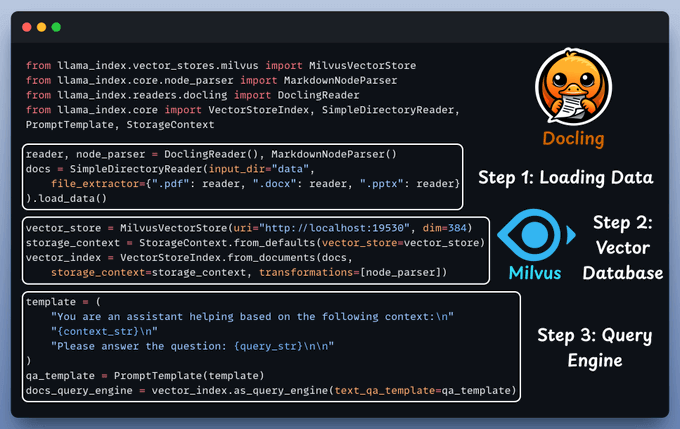
Convert PDF, DOCX, or any document to Markdown for Vector Storage with Docling.
Query Engine fetches context from Milvus, combines it with the query, and sends it to LLM for a response.
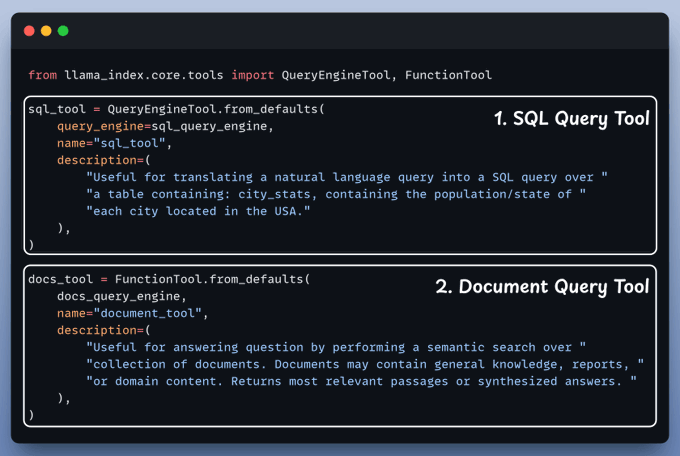
Set up tools
Now, it's time to set up and use both the query engines we defined above as tools. Our Agent will then smartly route the query to it's right tools.
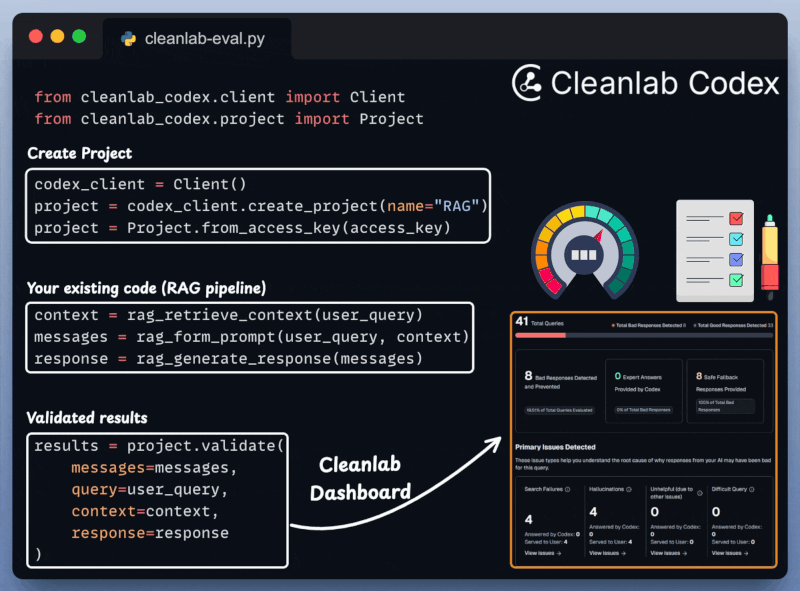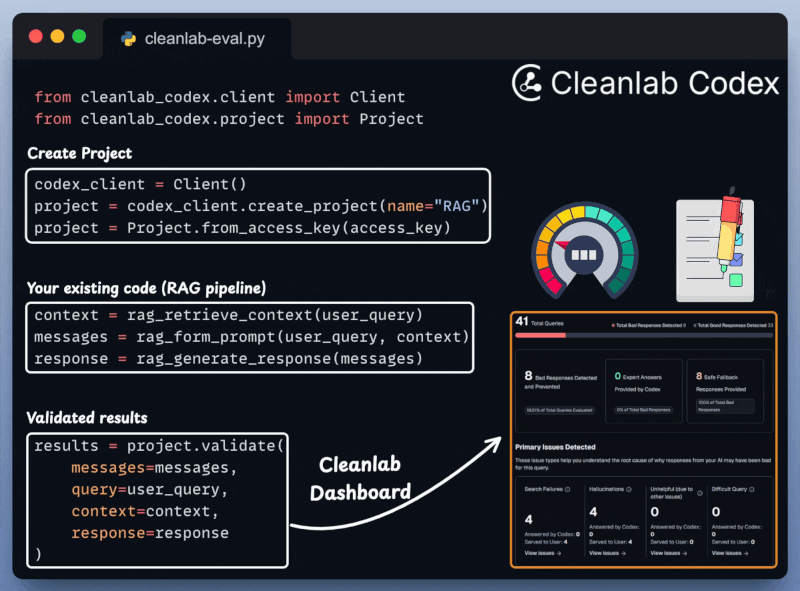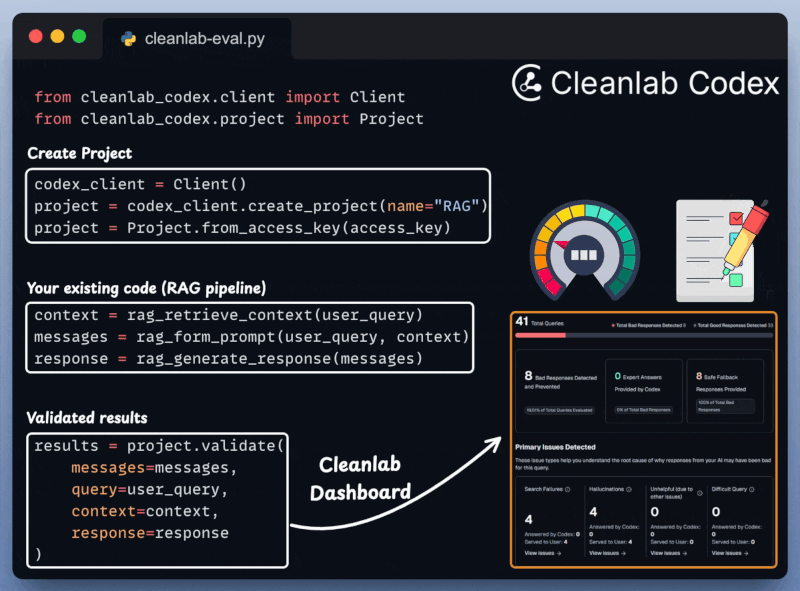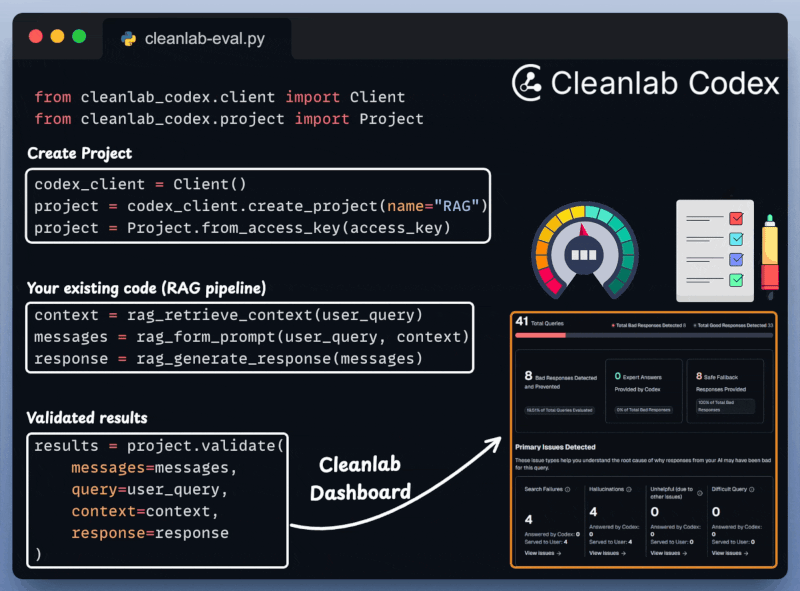
Cleanlab Codex Validation
Next, we integrate Cleanlab Codex to evaluate and monitor the RAG app in just a few lines of code:
Create Agentic workflow
With everything set up, let's create our agentic routing workflow.
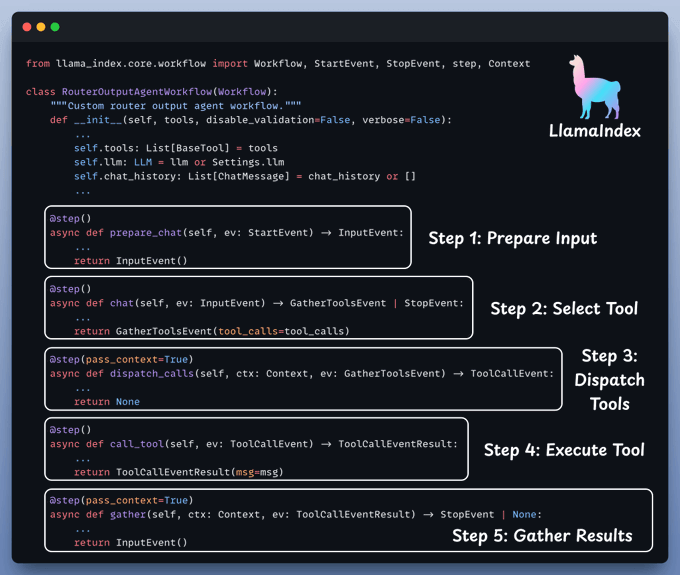
Kick off the workflow
With everything set, it's time to activate our workflow.
We begin by equipping LLM with two tools: Document & Text-to-SQL Query.
After that, we invoke the workflow:
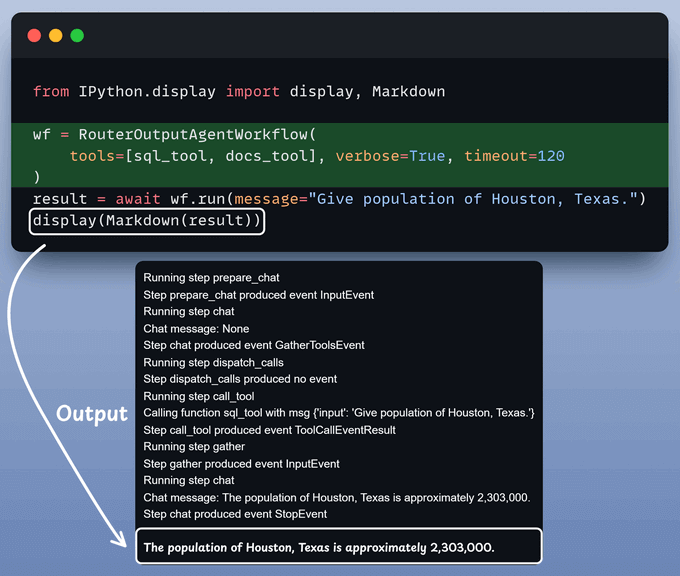
Streamlit UI
To enhance user-friendliness, we present everything within a clean and interactive Streamlit UI.
Upon prompting, notice that the app displays a Trust Score on the generated response.
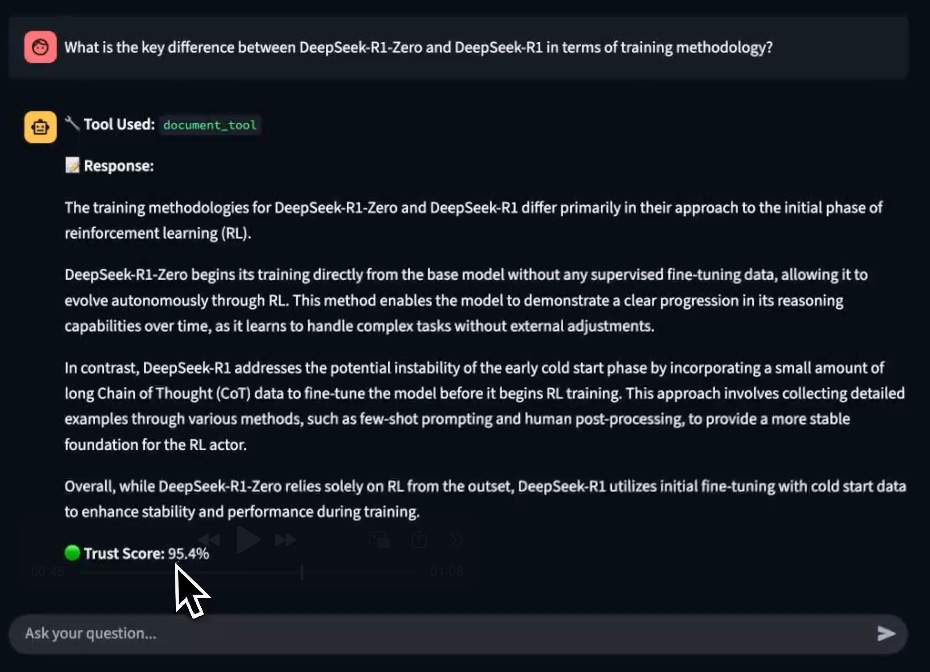
This is incredibly important for RAG/Agentic workflows that are quite susceptible to inaccuracies and hallucinations.
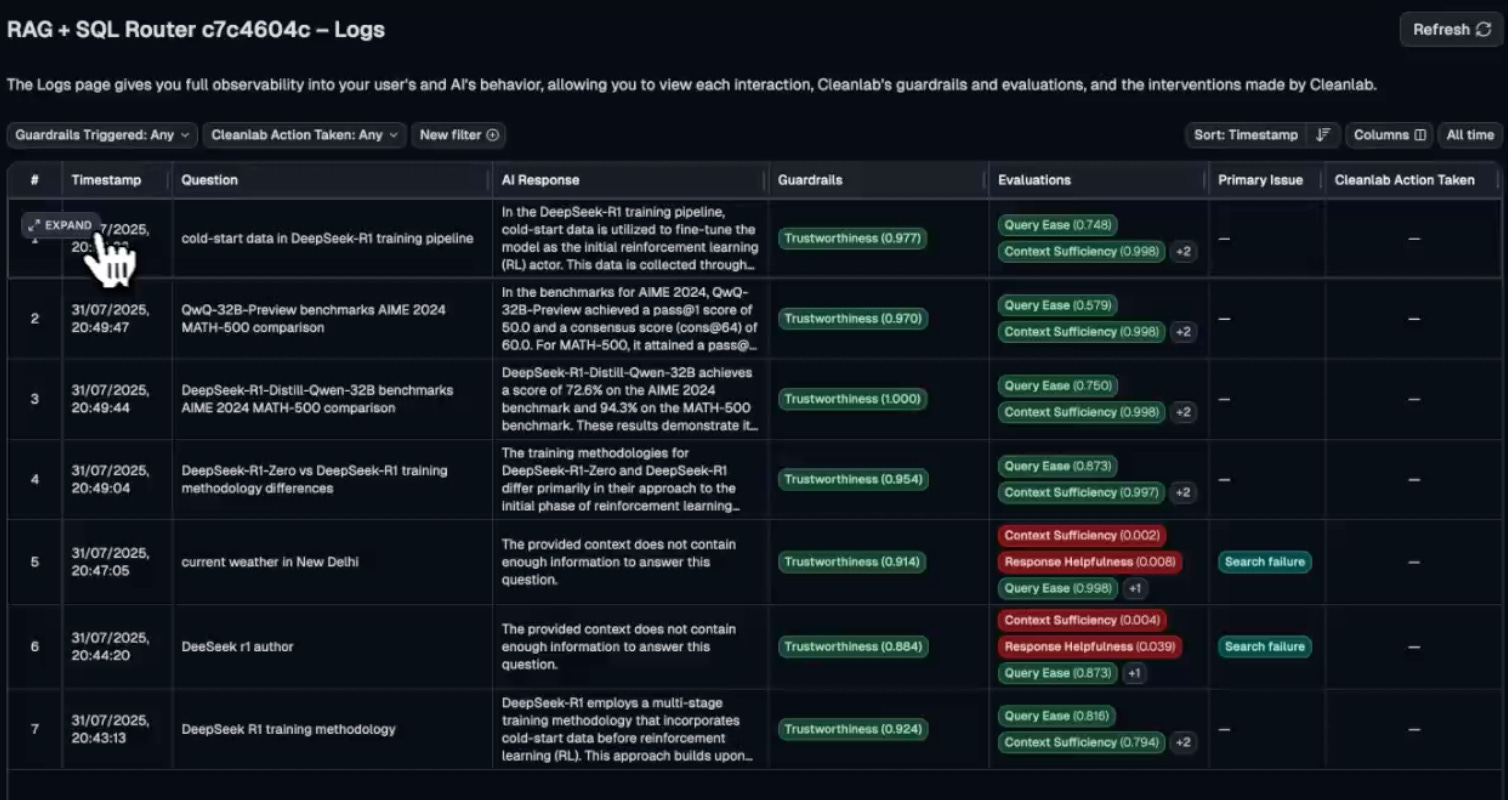
Along with this, we also get specific evaluation metrics along with detailed insights and reasoning for each test run:
Here’s the Codex documentation →
And you can find the code for today’s issue in this GitHub repo →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
