

Connect any LLM to any MCP server!

mcp-use is the open source way to connect any LLM to any MCP server and build custom agents that have tool access, without using closed source or application clients.
Build 100% local MCP clients.
GitHub repo → (don’t forget to star)
[Hands-on] Corrective RAG Agentic Workflow
Corrective RAG (CRAG) is a common technique to improve RAG systems. It introduces a self-assessment step of the retrieved documents, which helps in retaining the relevance of generated responses.
Here’s an overview of how it works:
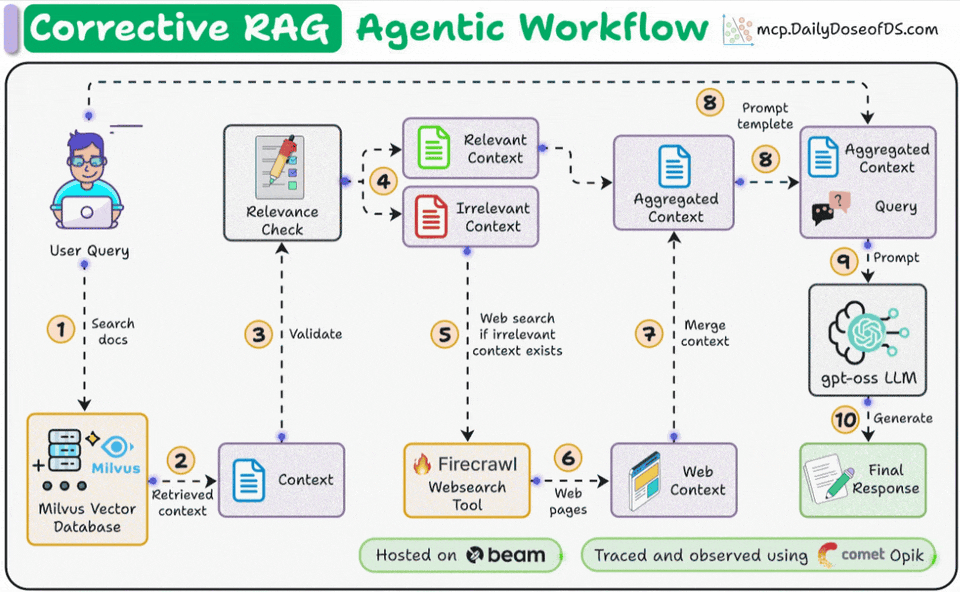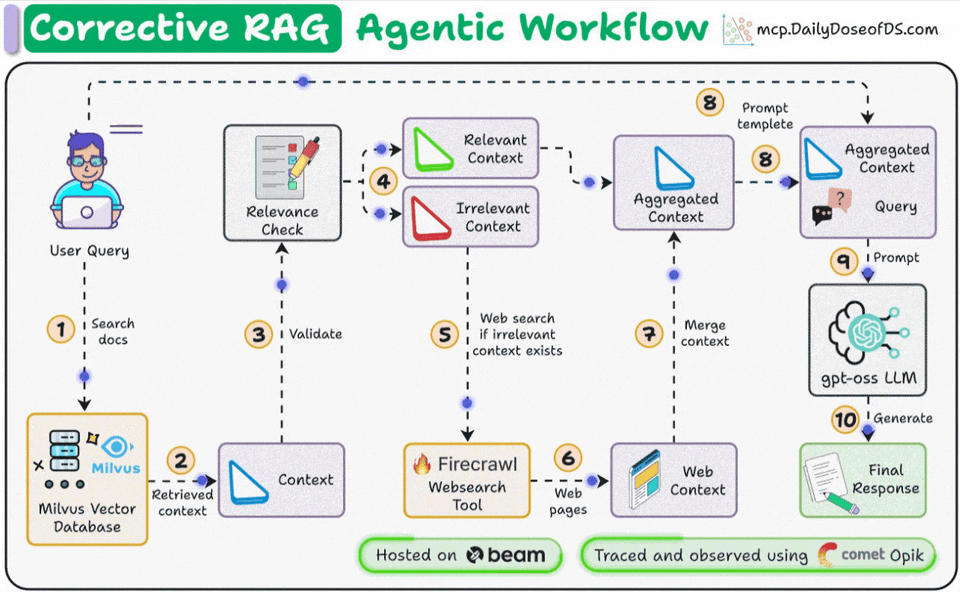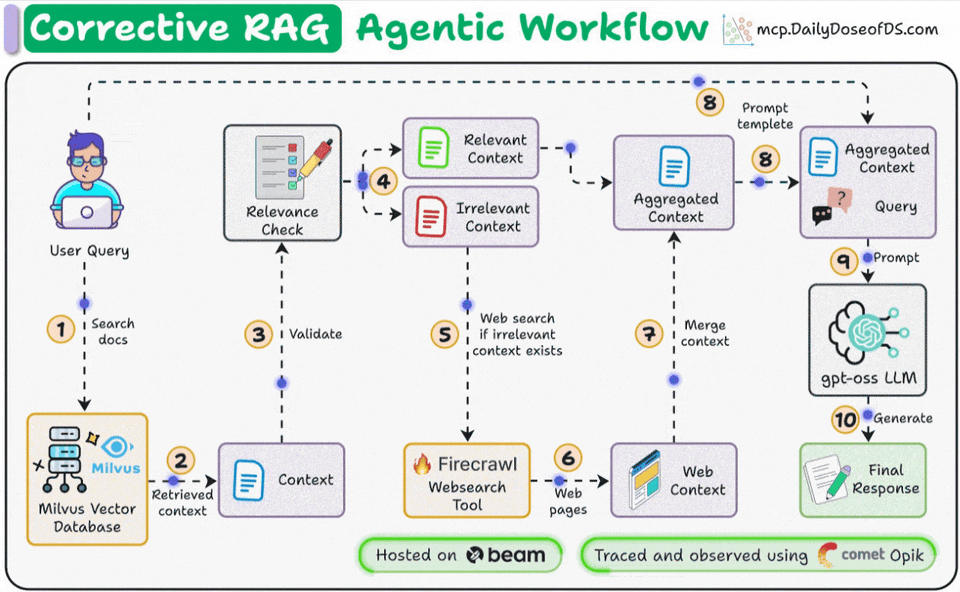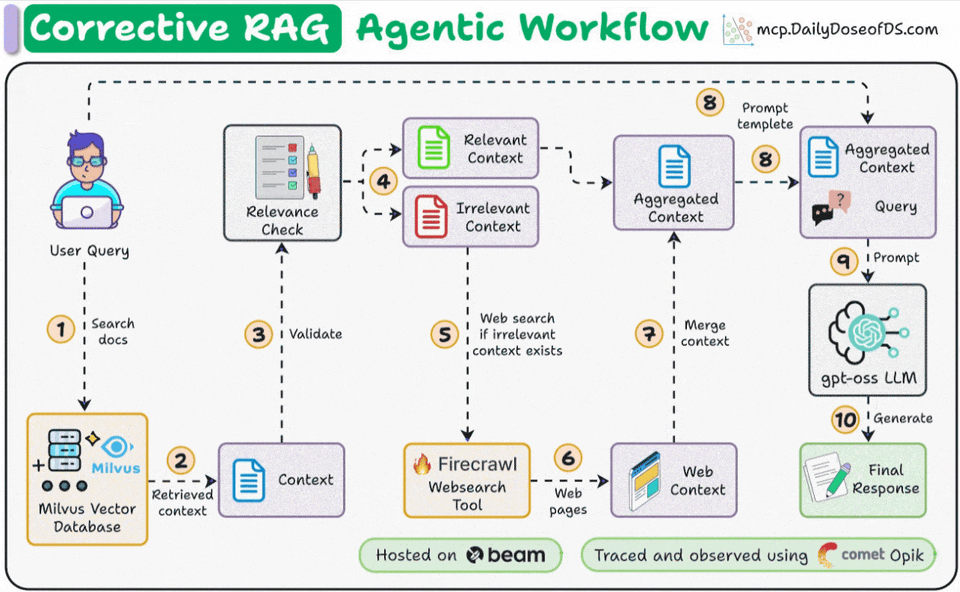
First, search the docs with user query.
Evaluate if the retrieved context is relevant using LLM.
Only keep the relevant context.
Do web search if needed.
Aggregate the context & generate response.
The video at the top shows how it works!
Here’s our tech stack for this demo:
Firecrawl for deep web search
Milvus to self-host vectorDB.
Beam for deployment
Cometml’s Opik to trace and monitor
LlamaIndex workflows for orchestration
Setup LLM
We will use gpt-oss as the LLM, locally served using Ollama.

Setup vectorDB
Our primary source of knowledge is the user documents that we index and store in a Milvus vectorDB collection.
This will be the first source that will be invoked to fetch context when the user inputs a query.

Set up web search tool
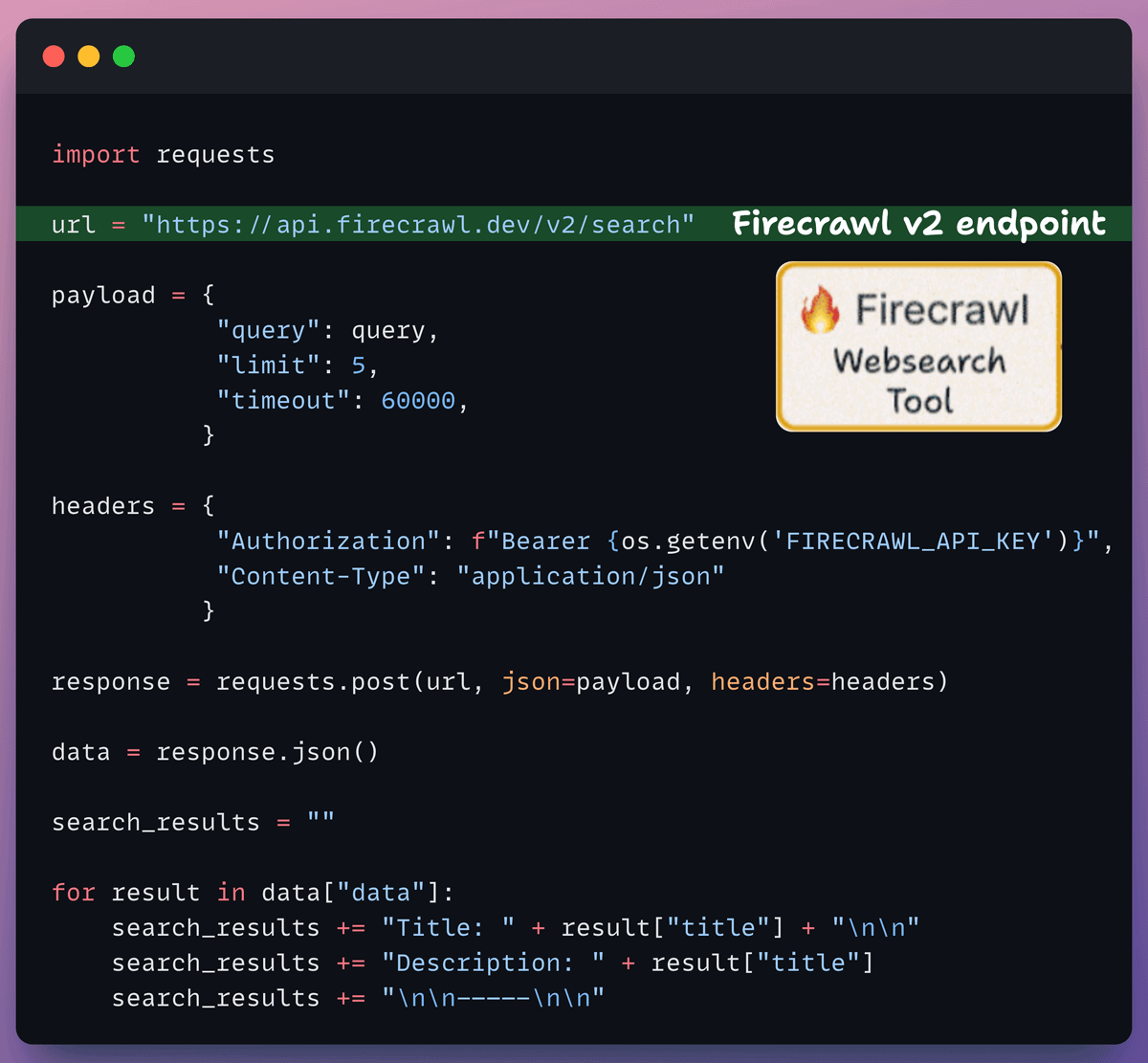
If the context obtained from the vector DB isn't relevant, we resort to web search using Firecrawl.
More specifically, we use the latest v2 endpoint that provides 10x faster scraping, semantic crawling, News & image search, and more.
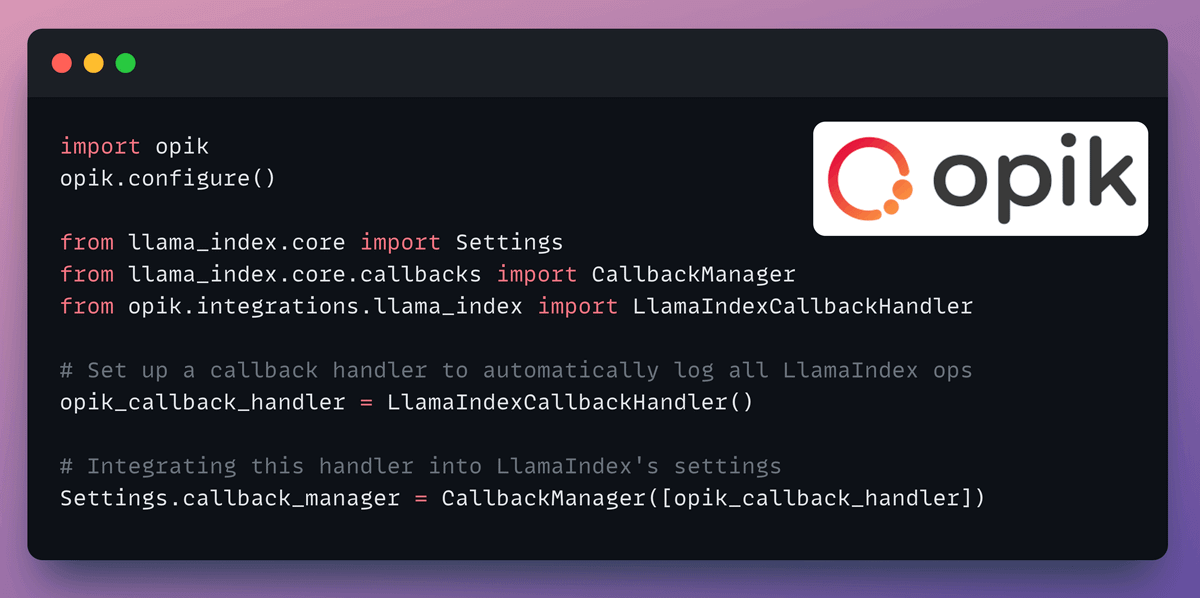
Tracing and Observability
LlamaIndex also offers a seamless integration with CometML’s Opik. You can use this to trace every LLM call, monitor, and evaluate your LLM application.
Create the workflow
Now that we have everything set up, it's time to create the event-driven agentic workflow that orchestrates our application.
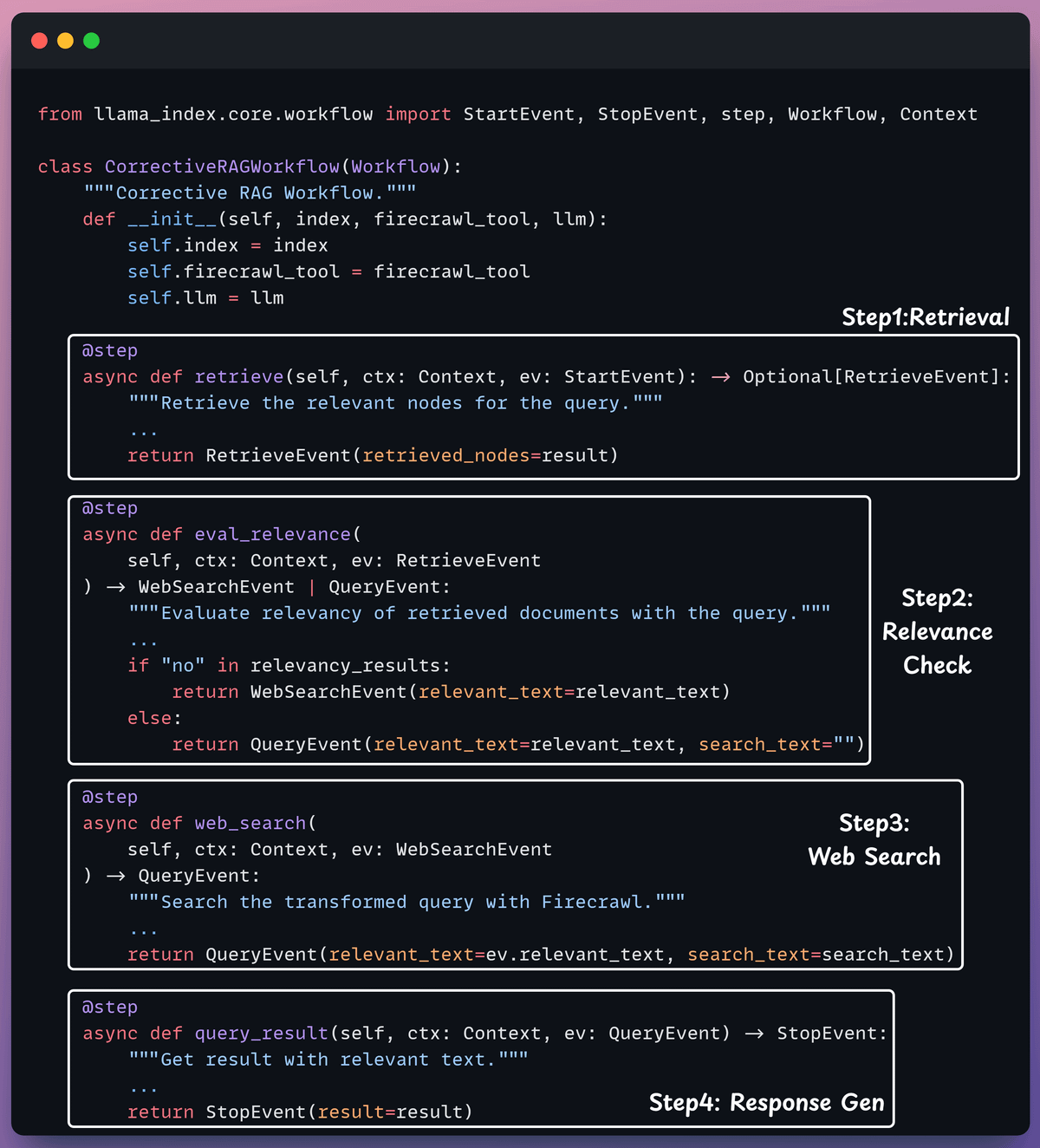
We pass in the LLM, vector index, and web search tool to initialise the workflow.
Kickoff the workflow
Finally, when we have everything ready, we kick off our workflow.
Check this out👇

Deployment with Beam
Beam enables ultra-fast serverless deployment of any AI workflow.
Thus, we wrap our app in a Streamlit interface, specify the Python libraries, and the compute specifications for the container.
Finally, we deploy it in a few lines of code:
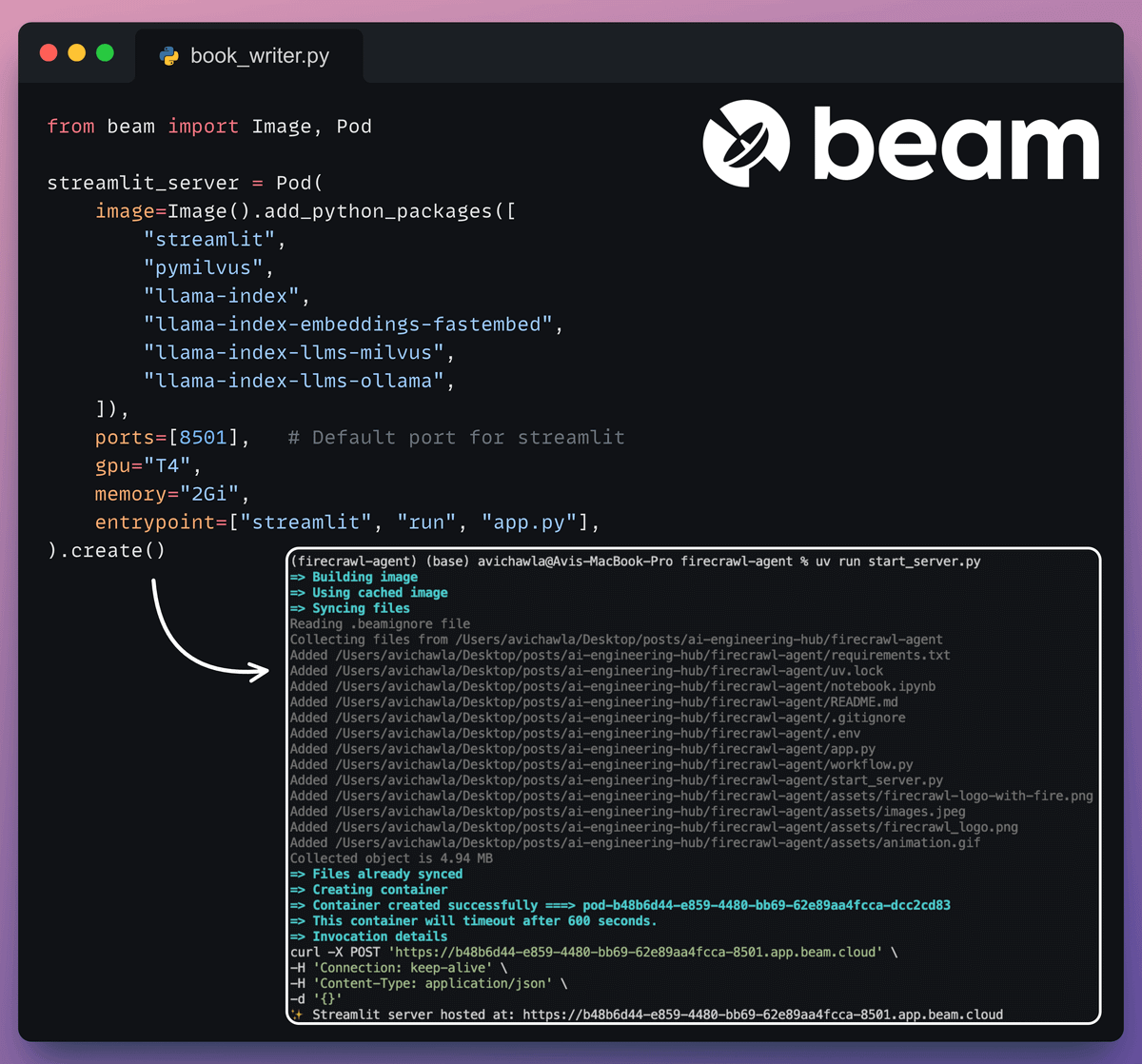
Run the app
Beam launches the container and deploys our streamlit app as an HTTPS server that can be accessed from a web browser.
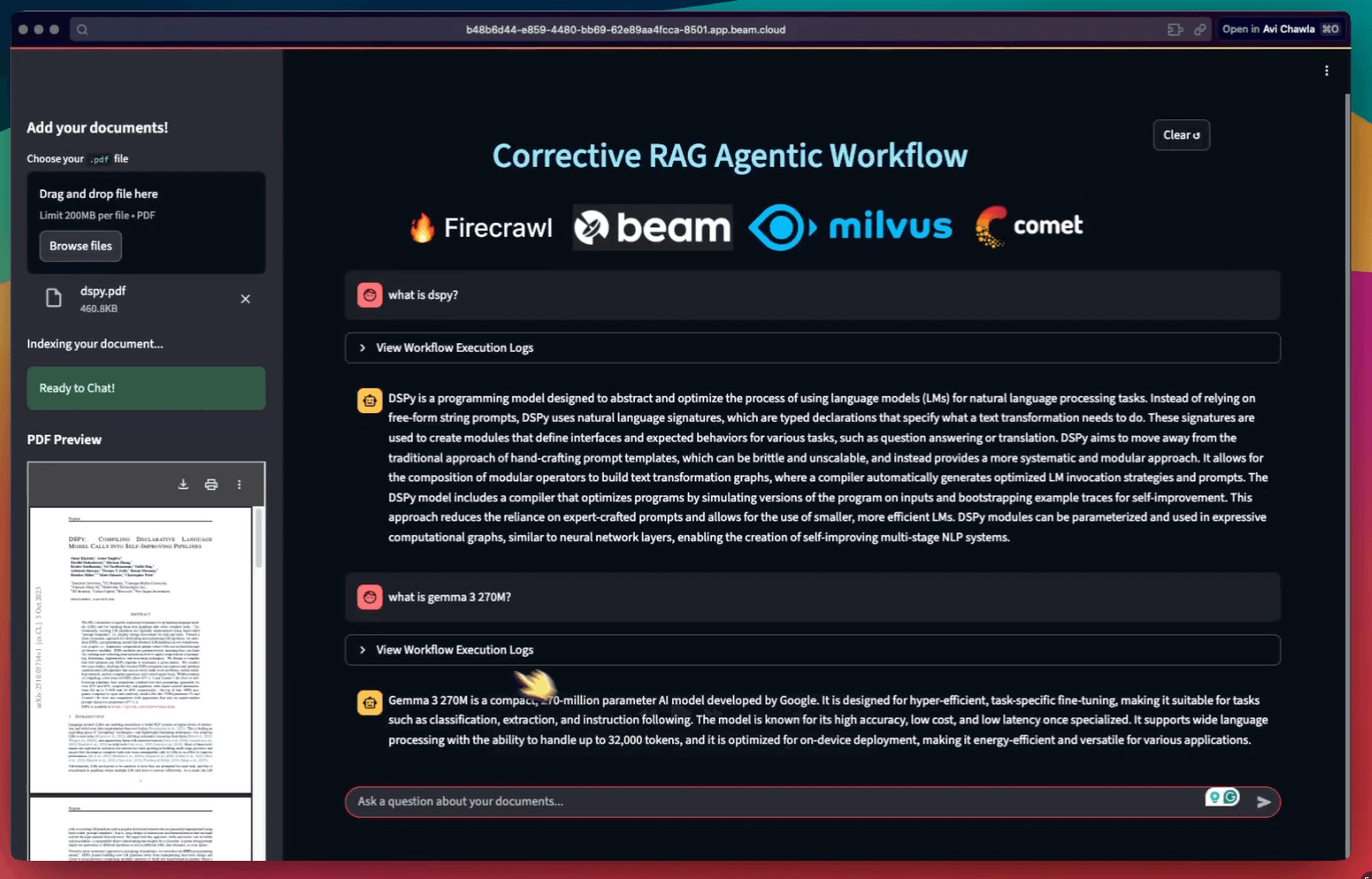
In the video attached at the top, our workflow is able to answer a query that's unrelated to the document. The evaluation step makes this possible. This is shown in the screenshot below:
If you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
The code for this issue is available here →
👉 Over to you: What other RAG demos would you like to see?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
