

Bright Data: Collect Public Web Data in Real-time at Scale

Building AI apps capable of interacting with real-time web data can feel impossible. Here are the challenges:
You must simulate human-like interactions.
You must overcome site blocks and captchas.
You must scrape accurate and clean data at scale.
You must ensure compliance with all legal standards.
Bright Data provides the complete infrastructure to handle data extraction, user simulation, and real-time interactions for your AI apps across the web.
With Bright Data, you can:
Access clean data from any public website with ease.
Simulate user behaviors at scale using advanced browser-based tools.
Enable AI models to retrieve real-time insights with a seamless Search API.
Bright Data is the fastest way to take your AI apps to the next level.
Thanks to Bright Data for partnering today.
100% Local RAG using DeepSeek
DeepSeek AI has released some open-weight reasoning models (like o1).
What's crazy is that it achieves a similar performance as OpenAI o1 but at much lower costs (about 95% cheaper).
For instance, per 1M tokens:
OpenAI o1: $60.00
DeepSeek R1: $2.19 (95% cheaper).
Today, let us show you a RAG app we built with DeepSeek.
The video at the top depicts the final outcome (the code is linked later).
On a side note, we started a beginner-friendly crash course on RAGs recently with implementations, which covers:
Foundations of RAG
RAG evaluation
RAG optimization
Building blocks of Multimodal RAG (CLIP, multimodal prompting, etc.)
Building multimodal RAG systems.
Graph RAG
Improving rerankers in RAG.
Let's build it now.
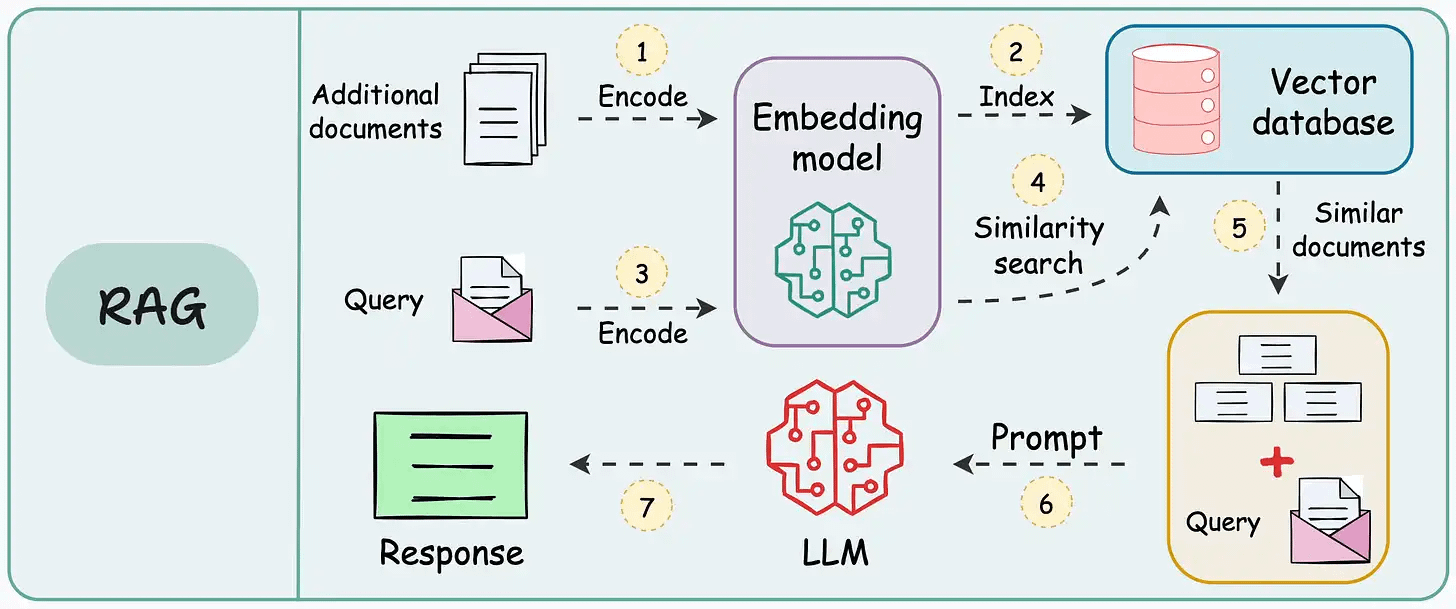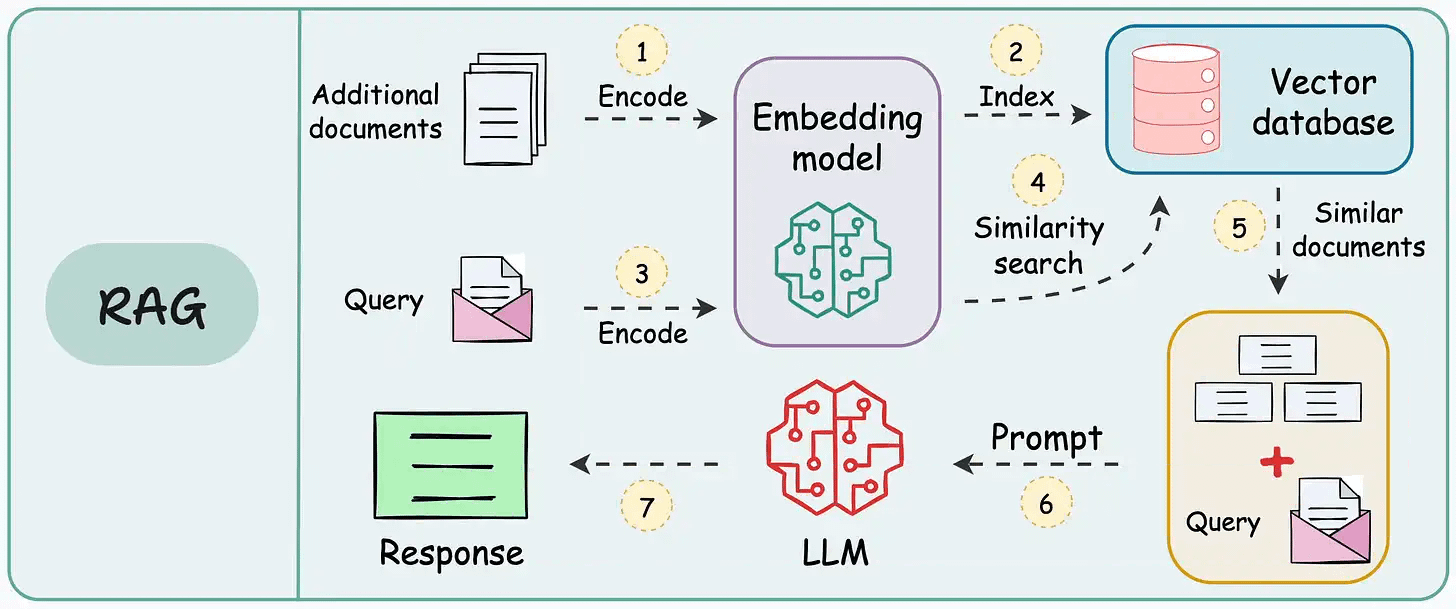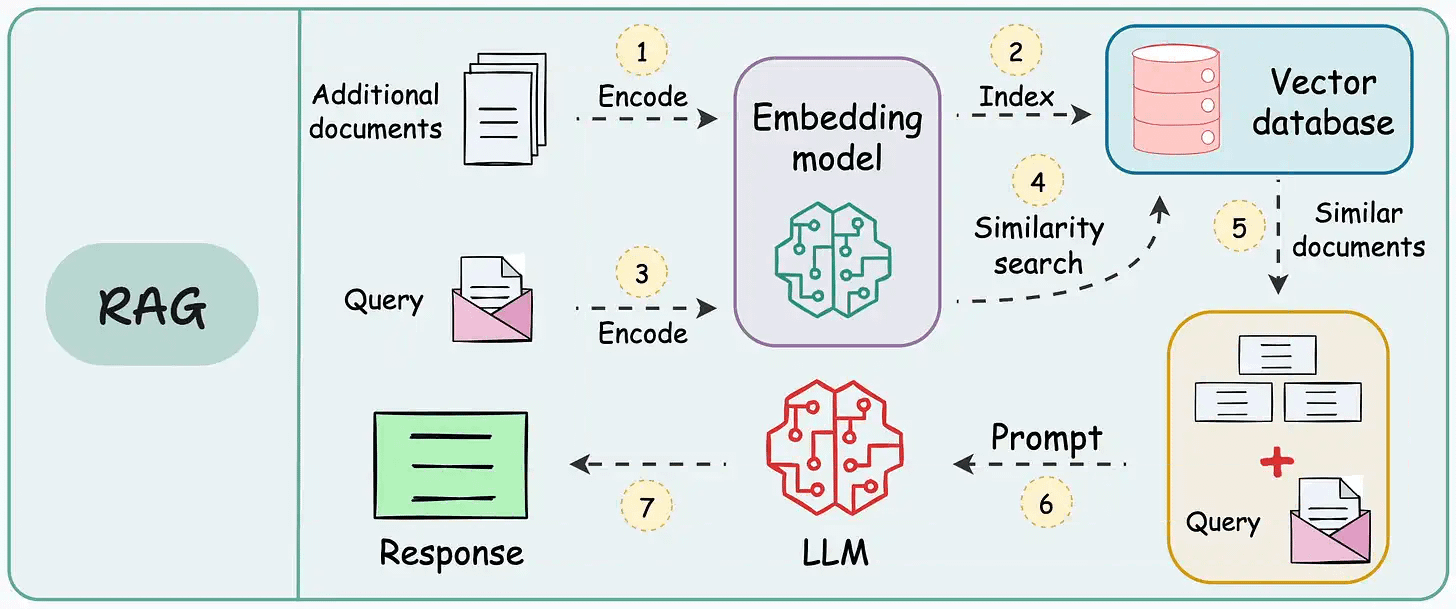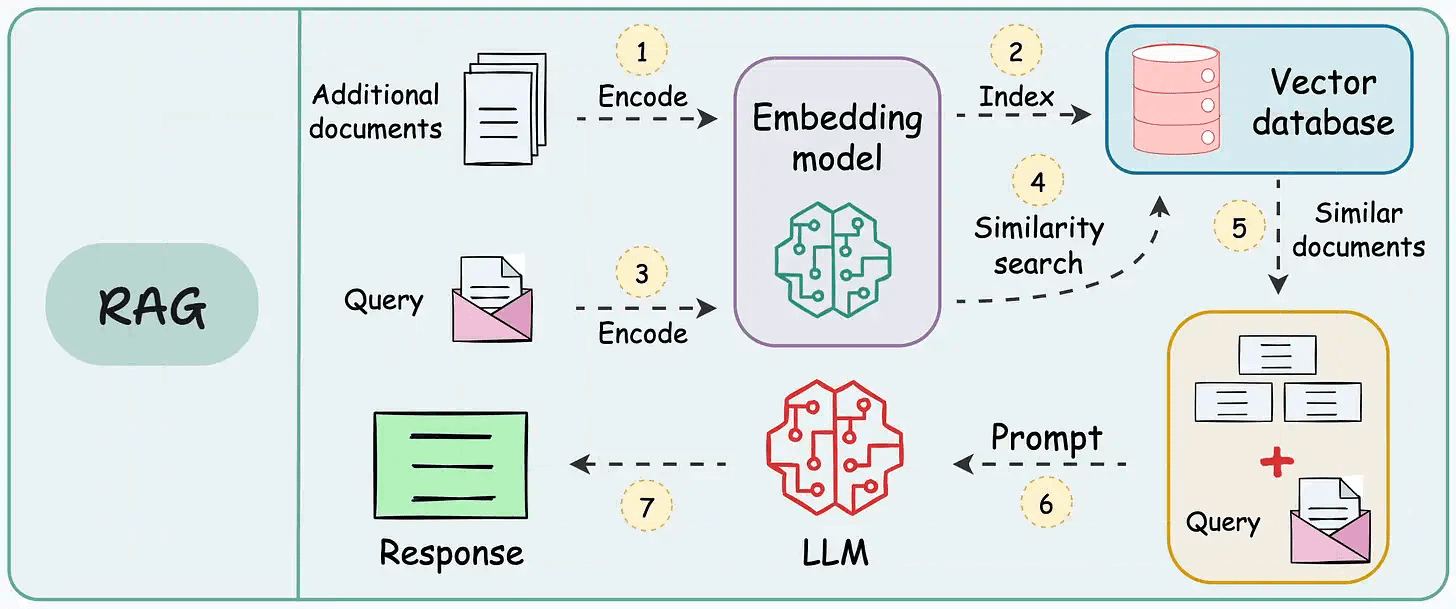
First, we load and parse the external knowledge base, which is a document stored in a directory, using LlamaIndex:

Next, we define an embedding model, which will create embeddings for the document chunks and user queries:

After creating the embeddings, the next task is to index and store them in a vector database. We’ll use a self-hosted Qdrant vector database for this as follows:

Next up, we define a custom prompt template to refine the response from LLM & include the context as well:

Almost done!
Finally, we set up a query engine that accepts a query string and uses it to fetch relevant context.
It then sends the context and the query as a prompt to the LLM to generate a final response.
Below, we set up the DeepSeek-R7 7b using LlamaIndex's integration with Ollama:

Done!
There’s some streamlit part we have shown here, but after building it, we get this clear and neat interface:

Wasn’t that easy and straightforward?
We'll cover more advanced techniques very soon in our RAG crash course, specifically around Agentic RAG, vision RAG, etc.
Here's what we have covered so far in the first seven parts:
In Part 1, we explored the foundational components of RAG systems, the typical RAG workflow, and the tool stack, and also learned the implementation.
In Part 2, we understood how to evaluate RAG systems (with implementation).
In Part 3, we learned techniques to optimize RAG systems and handle millions/billions of vectors (with implementation).
In Part 4, we understood multimodality and covered techniques to build RAG systems on complex docs—ones that have images, tables, and texts (with implementation):
In Part 5, we understood the fundamental building blocks of multimodal RAG systems that will help us improve what we built in Part 4.
In Part 6, we utilized the learnings from Part 5 to build a much more extensive multimodal RAG system.
In Part 7, we built a graph RAG system by utilizing a graph database to store information in entities and relations.
In Part 8, we learned how to improve retrieval and rerankers with ColBERT, to produce much more coherent responses at scale.
In Part 9, we learned how to build vision-driven RAG models with ColPali.
The code to run this app is available in our GitHub repository here: RAG with DeepSeek.
👉 Over to you: What other demos would you like to see with DeepSeek?
Thanks for reading!
