

In today's newsletter:
Video to Pull Request in minutes with Codegen.
How to test Agents using Agents.
3 techniques to train an LLM using another LLM.
Video to Pull Request in minutes with Codegen
Codegen now lets you shoot a quick video of what you want, and a code agent will see + resolve the issue. Just attach a video in Slack or Linear.
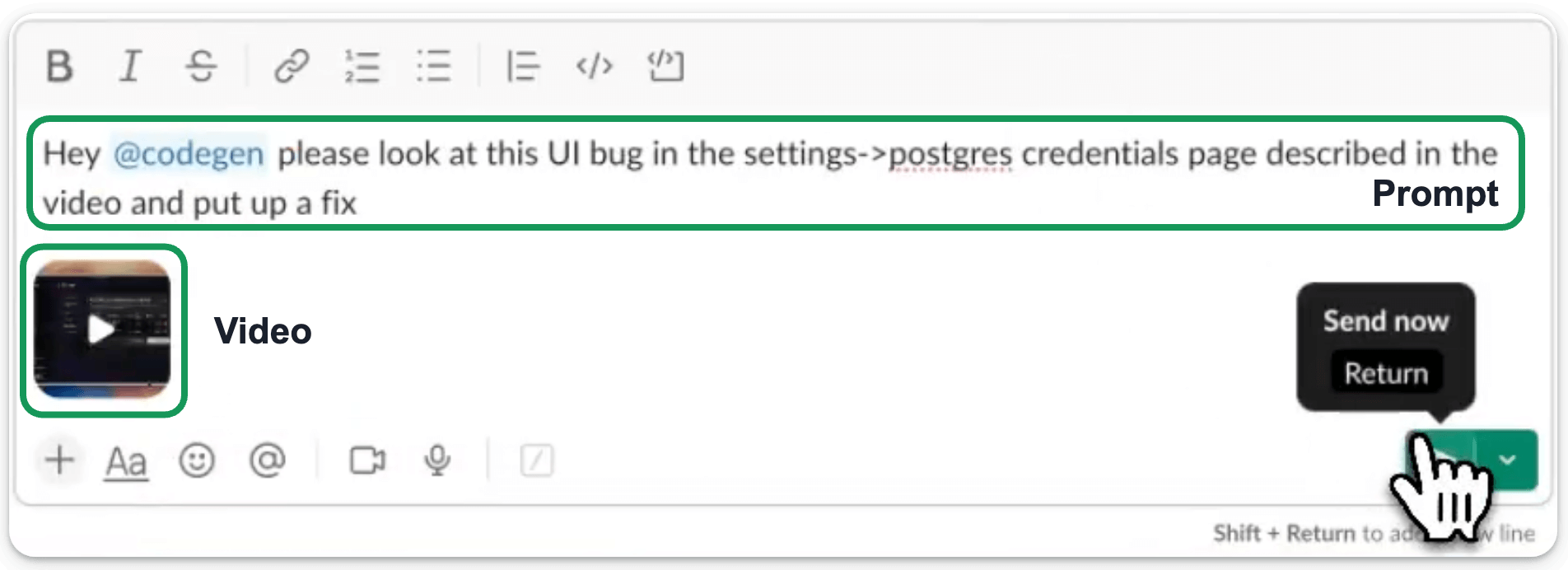
It will use Gemini to extract insights from the video and return with a PR shortly.

You can also invite the Agent to your Zoom/Google meeting, discuss the features/bugs, and offload the work to Codegen.
How to Test Agents Using Agents
Traditional testing relies on fixed inputs and exact outputs. But agents speak in language, and there’s no single “correct” response.
That’s why we test Agents using other Agents by simulating Users and Judges.
Today, let’s understand Agent Testing by building a pipeline to test Agents with other Agents using Scenario.
Our open-source tech stack:
CrewAI for Agent orchestration.
LangWatch Scenario to build the eval pipeline.
PyTest as the test runner.
Here's what the process looks like:
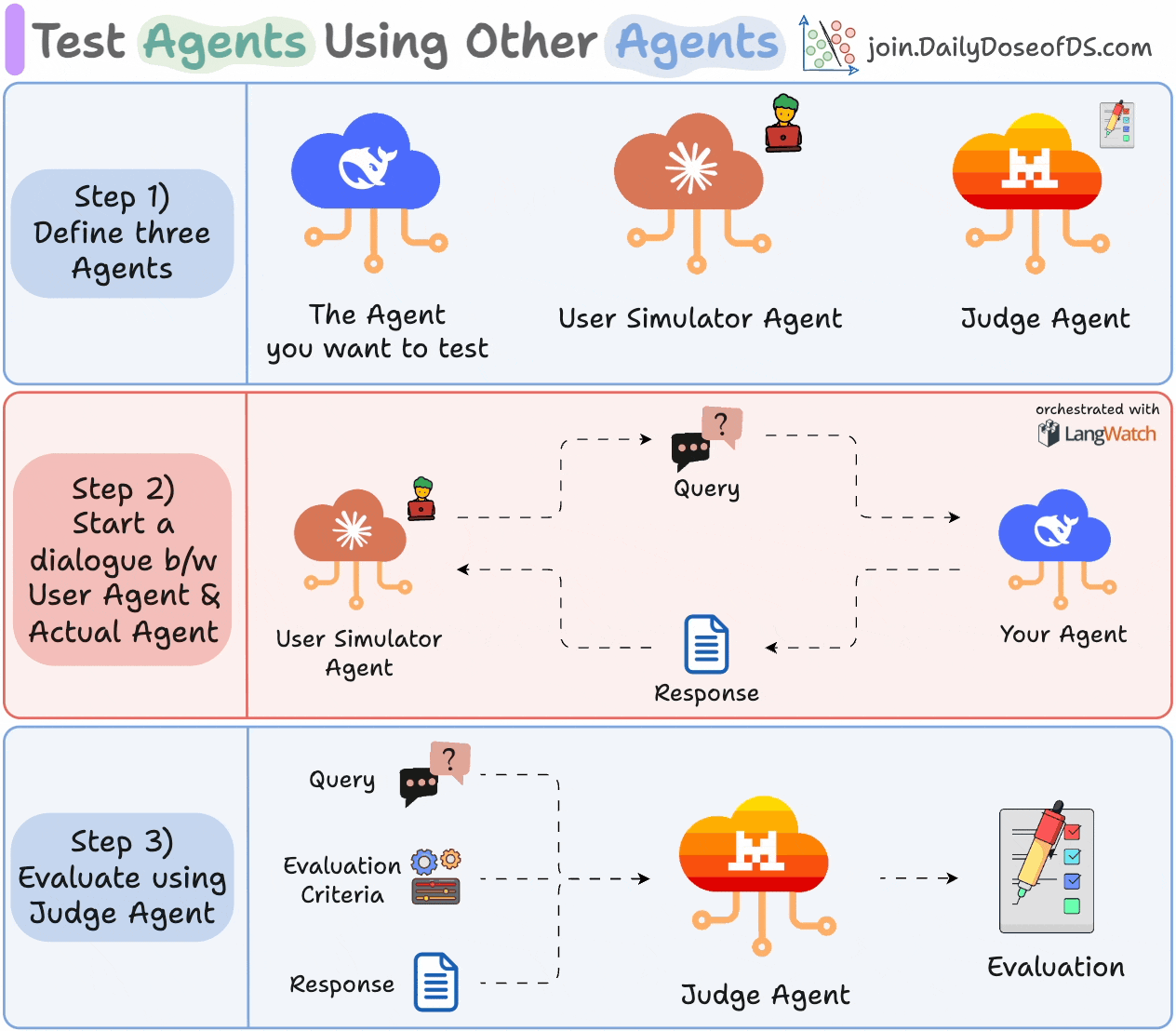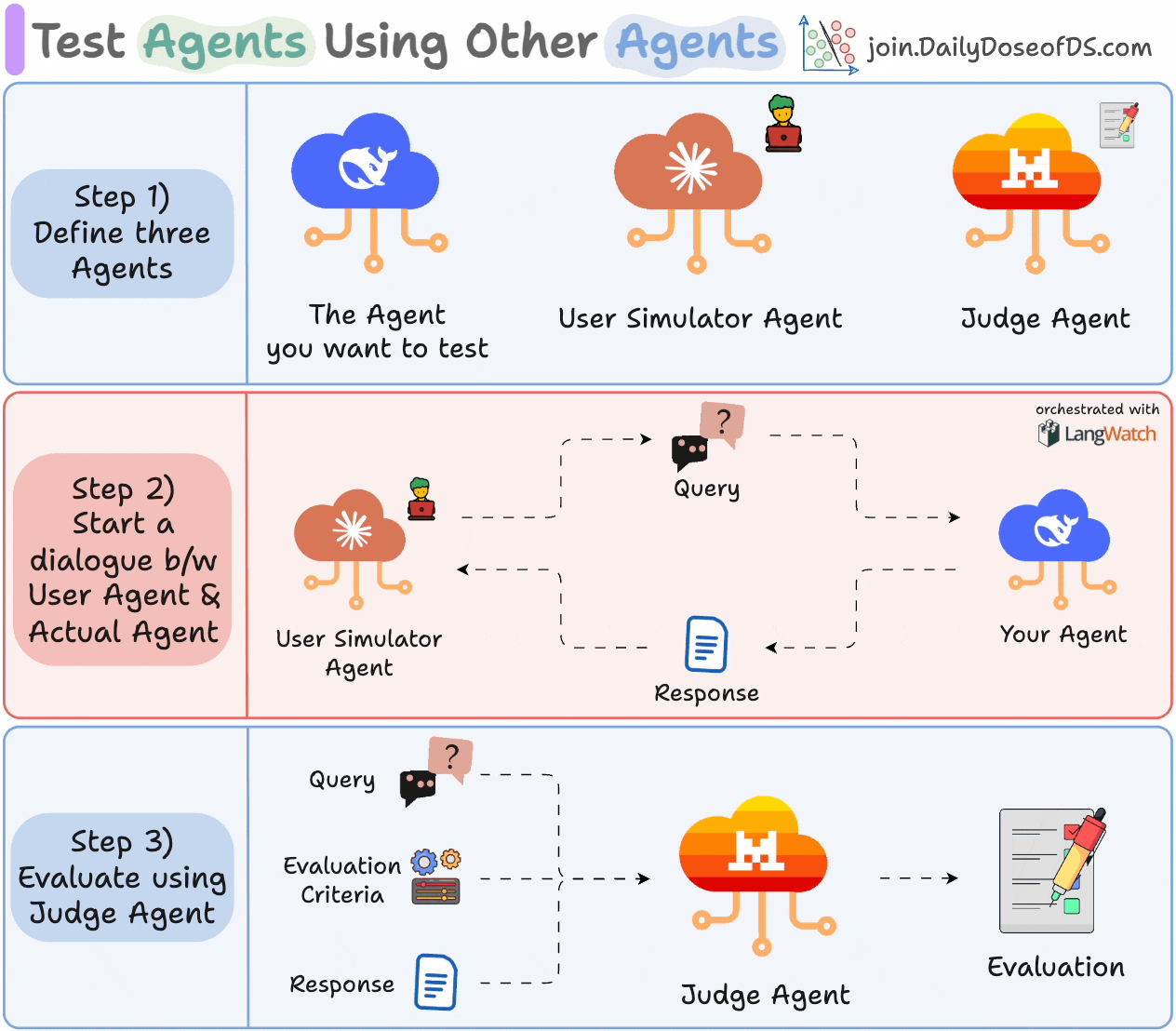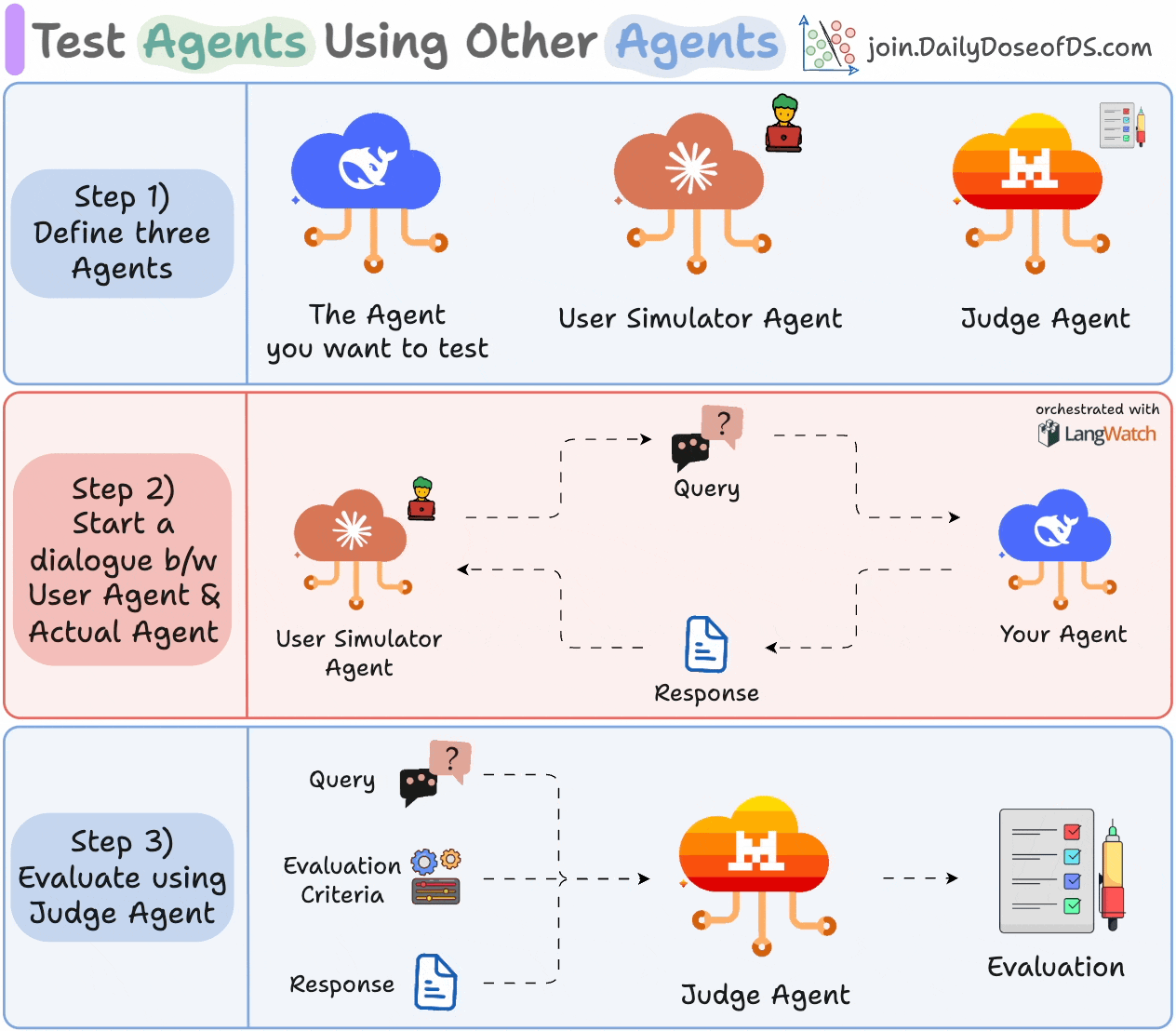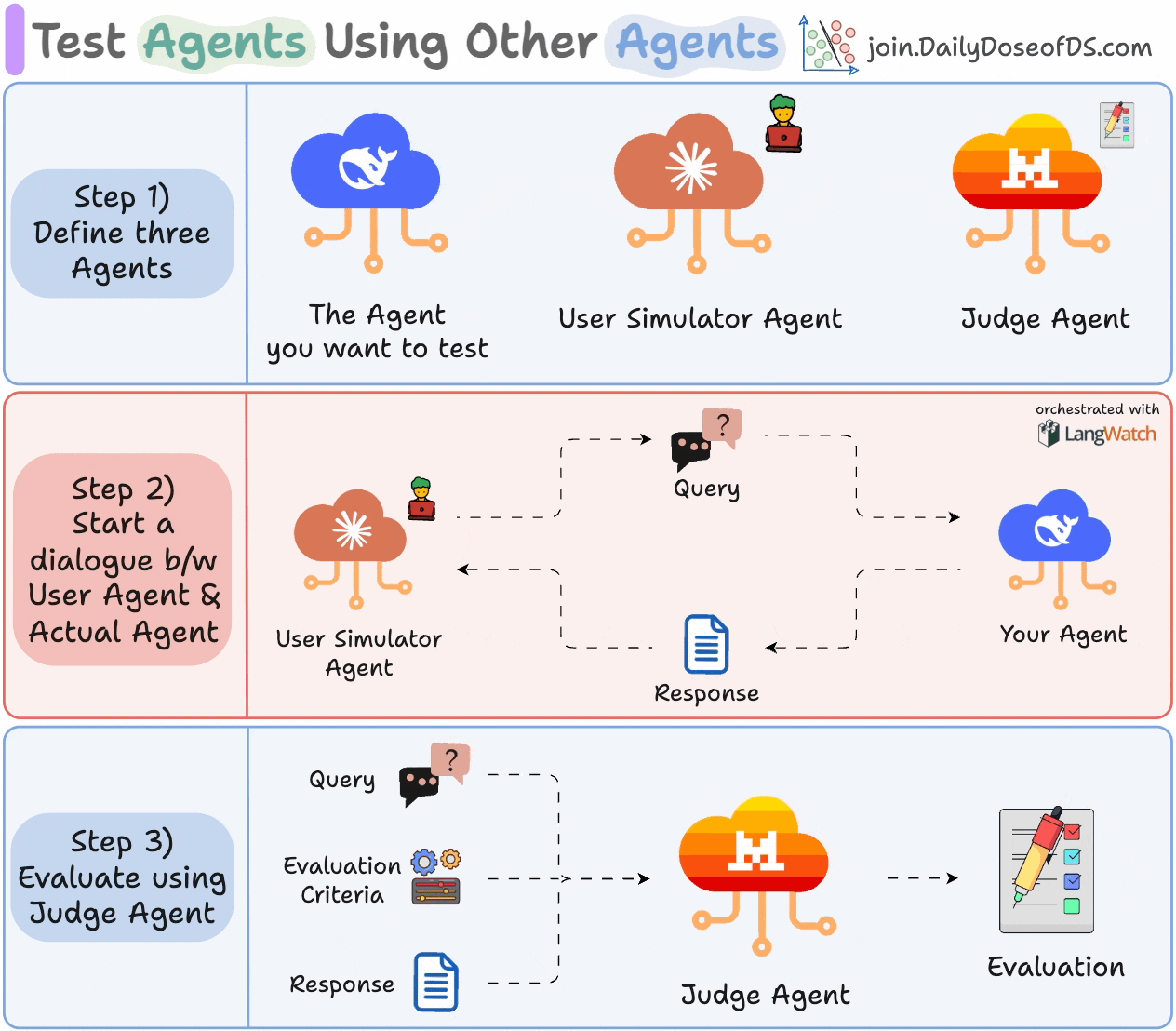
1) Define three Agents:
The Agent you want to test.
A User Simulator Agent that acts like a real user.
A Judge Agent for evaluation.
2) Let your Agent and User Simulator Agent interact with each other.
3) Evaluate the exchange using the Judge Agent based on the specified criteria.
Let’s implement this!
Define Planner Crew
For this demonstration, let’s build a Travel Planner Agent using CrewAI.
It will accept a user query and respond with travel suggestions, a brief itinerary, and an estimated budget.

Configure Crew for testing
In the Scenario library, your Agent class should:

Inherit from the AgentAdapter class.
Define a
call()method that takes the input and returns the output.
Define test
Finally, in our test, we simulate a conversation b/w Travel Agent and User Simulator Agent using the scenario.run method.
After the exchange, a Judge Agent evaluates it using the specified criteria. LangWatch Scenario orchestrates everything!

We specify a name for this test (the
nameparameter).We specify that this test is about (the
descriptionparameter).We specify the agents involved.
Travel Agent: The Agent we want to test.
User Simulator Agent: The Agent that will mimic a real user.
Judge Agent: The Agent that will evaluate the conversation based on the criteria specified in natural language.
Finally, we run the test as follows: uv run pytest -s test_travel_agent.py

As depicted above, the Judge Agent declared it a failed run since it cannot be determined if the location is <4 hrs away, but this was specified in the criteria when we declared the Judge Agent.
Testing revealed a gap, and we can fix this by prompting the Agent to ask for the location if the user did not specify it.
And that’s how you can build pipelines for Agent testing.
The LangWatch Scenario open-source framework orchestrates this process. It is a library-agnostic Agent testing framework based on simulations.
Key features:
Test Agent behavior by simulating users in different scenarios and edge cases.
Evaluate at any point of the conversation using powerful multi-turn control.
Integrate any Agent by implementing just one
call()method.Combine with any LLM eval framework or custom evals.
3 techniques to train an LLM using another LLM
LLMs don't just learn from raw text; they also learn from each other:
Llama 4 Scout and Maverick were trained using Llama 4 Behemoth.
Gemma 2 and 3 were trained using Google's proprietary Gemini.
Distillation helps us do so, and the visual below depicts three popular techniques.
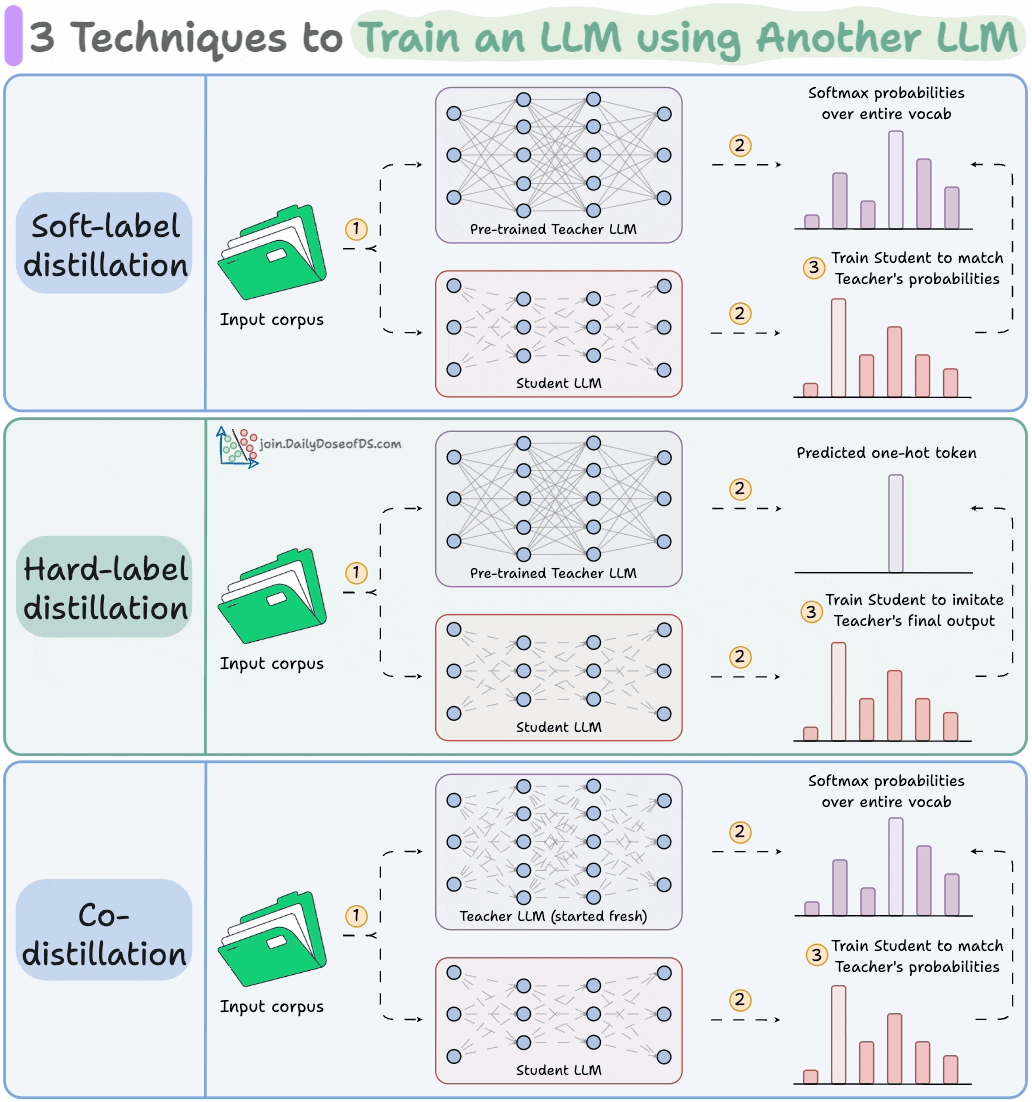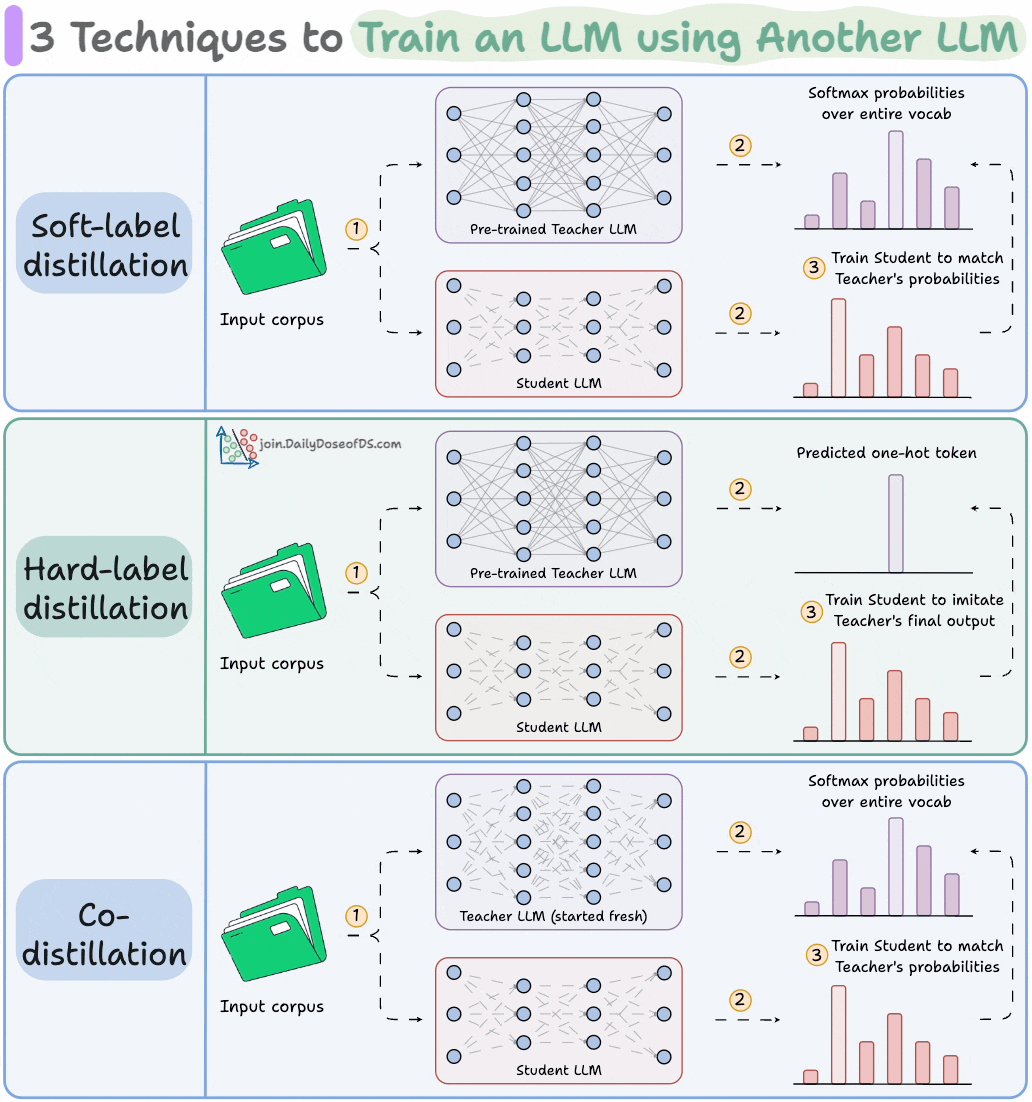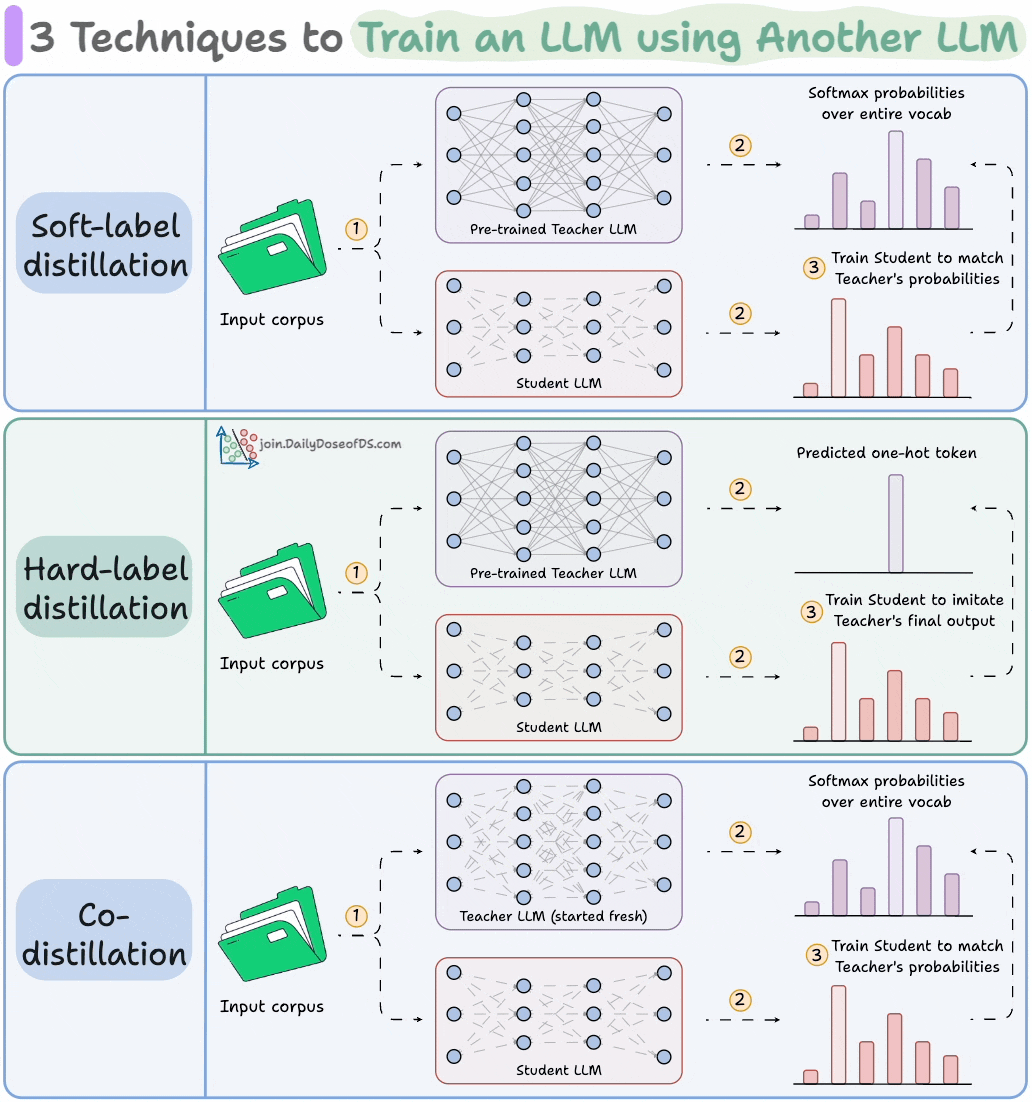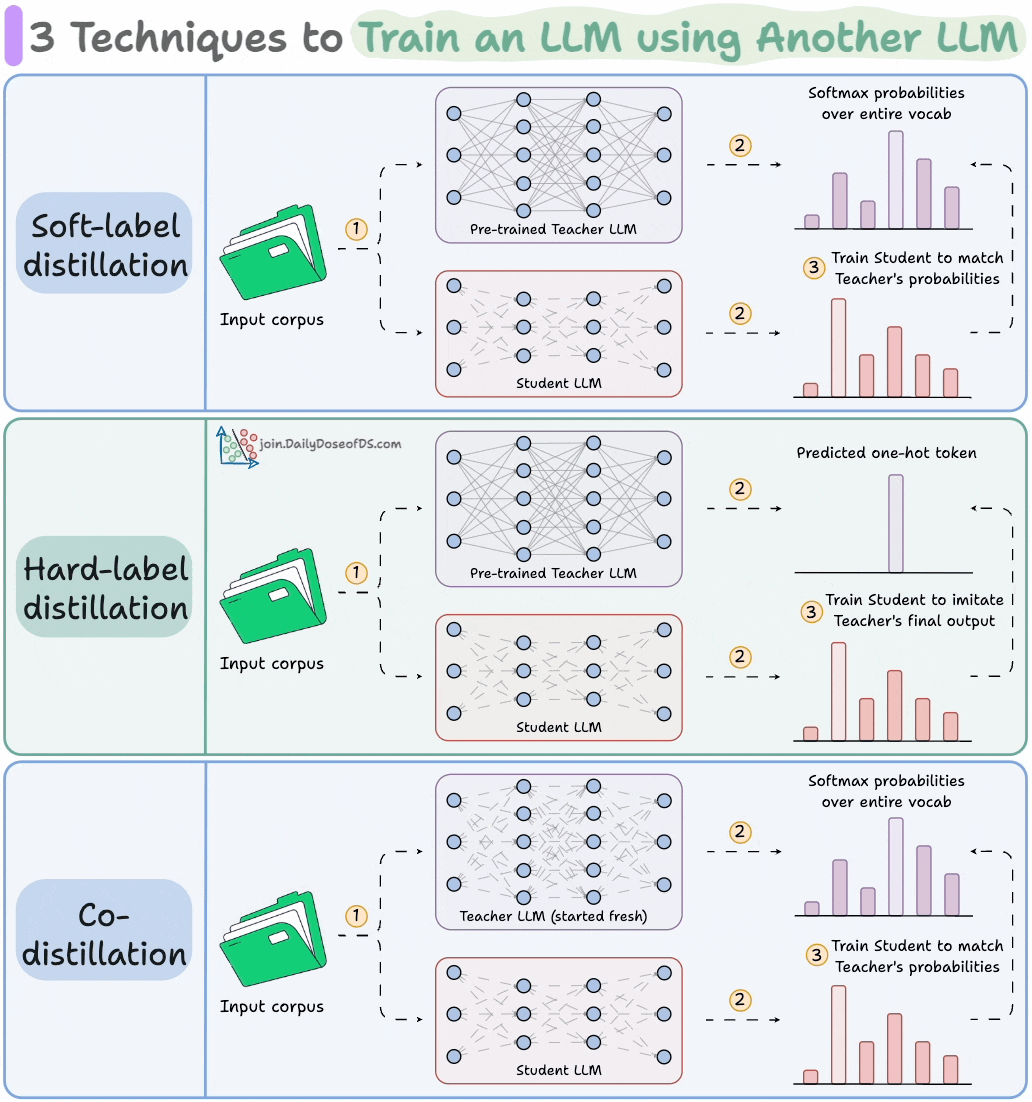
The idea is to transfer "knowledge" from one LLM to another, which has been quite common in traditional deep learning (like we discussed here).
Here are the three commonly used distillation techniques:
1) Soft-label distillation:

Use a fixed pre-trained Teacher LLM to generate softmax probabilities over the entire corpus.
Pass this data through the untrained Student LLM as well to get its softmax probabilities.
Train the Student LLM to match the Teacher's probabilities.
Visibility over the Teacher's probabilities ensures maximum knowledge (or reasoning) transfer.
However, you must have access to the Teacher’s weights to get the output probability distribution.
Even if you have access, there's another problem!
Say your vocab size is 100k tokens and your data corpus is 5 trillion tokens.
Since we generate softmax probabilities of each input token over the entire vocabulary, you would need 500 million GBs of memory to store soft labels under float8 precision.
The second technique attempts to solve this.
2) Hard-label distillation
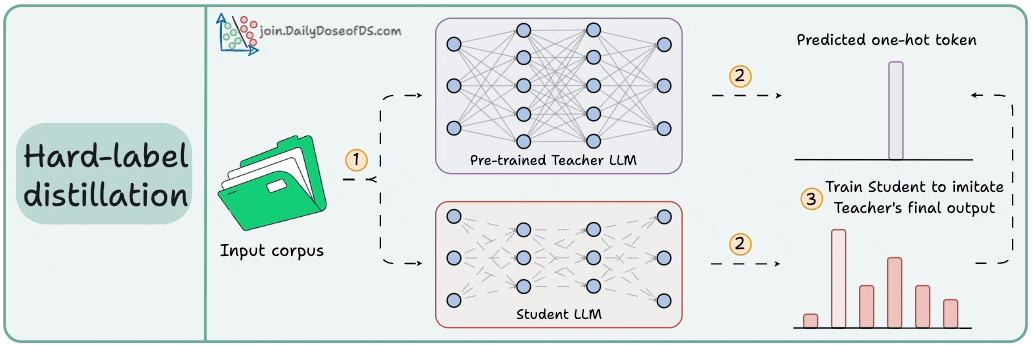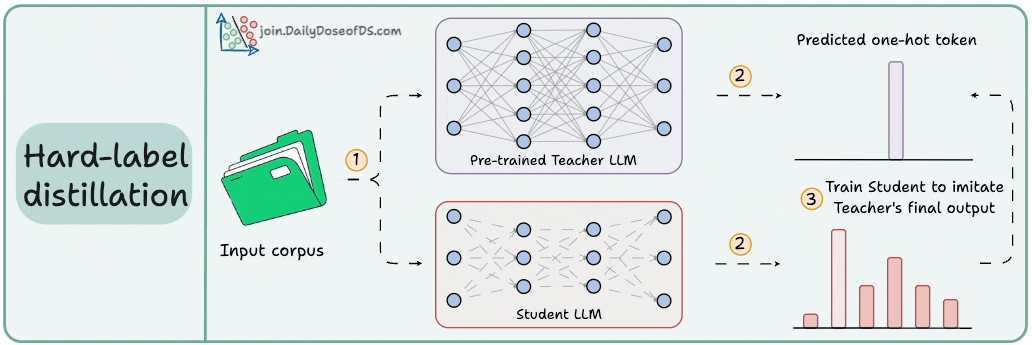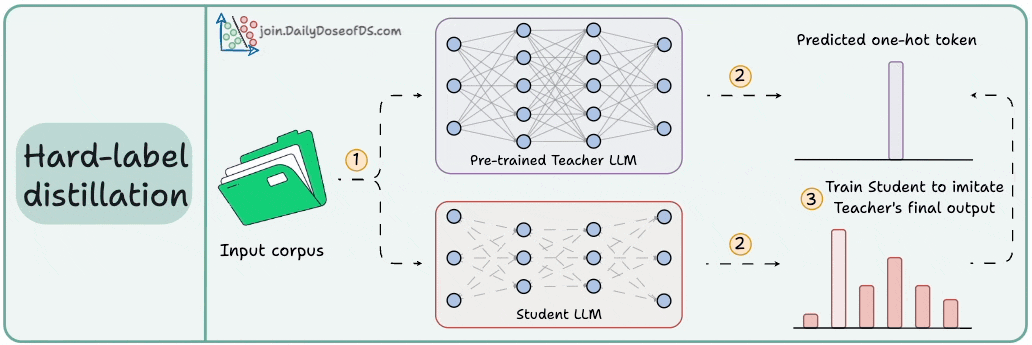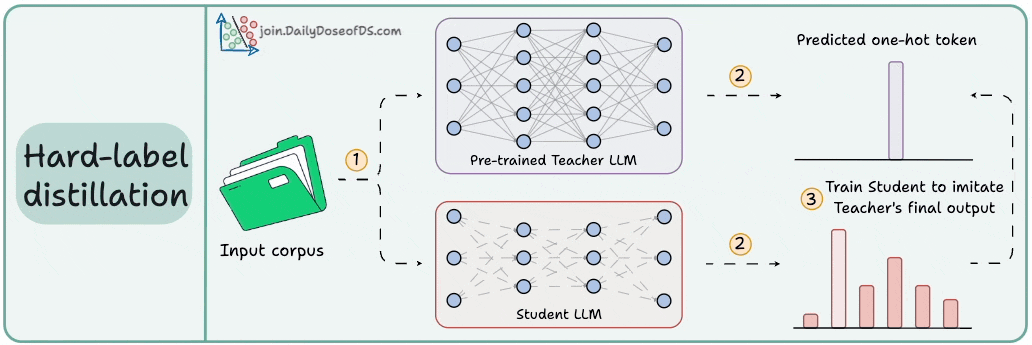
Use a fixed pre-trained Teacher LLM to just get the final one-hot output token.
Use the untrained Student LLM to get the softmax probabilities from the same data.
Train the Student LLM to match the Teacher's probabilities.
DeepSeek did this by distilling DeepSeek-R1 into Qwen and Llama 3.1 models.
3) Co-distillation
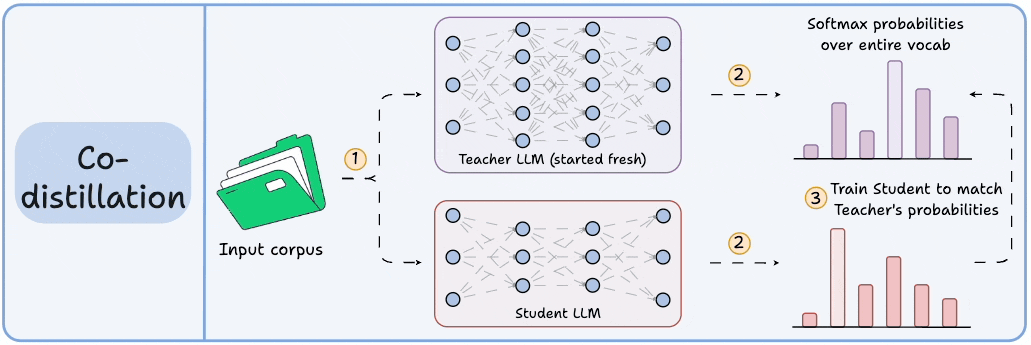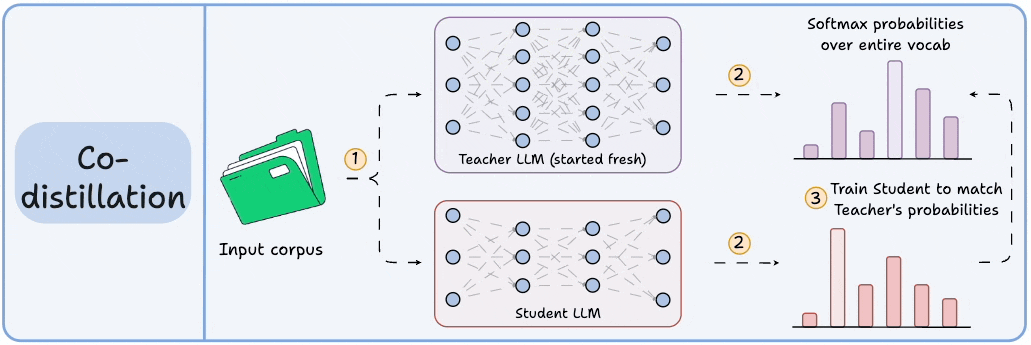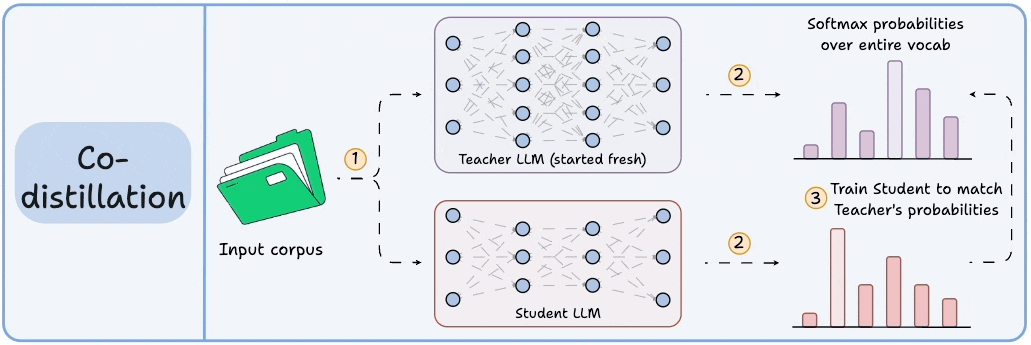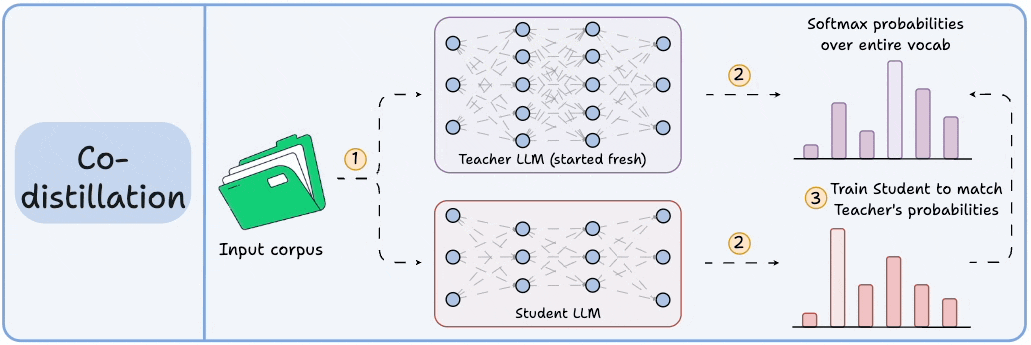
Start with an untrained Teacher LLM and an untrained Student LLM.
Generate softmax probabilities over the current batch from both models.
Train the Teacher LLM as usual on the hard labels.
Train the Student LLM to match its softmax probabilities to those of the Teacher.
Llama 4 did this to train Llama 4 Scout and Maverick from Llama 4 Behemoth.
Of course, during the initial stages, soft labels of the Teacher LLM won't be accurate.
That is why Student LLM is trained using both soft labels + ground-truth hard labels.
👉 Over to you: Which technique do you find the most promising?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
