

Build, deploy & scale AI Agents with a single button!

xpander is your plug-and-play Backend for agents that manages memory, tools, multi-user states, events, guardrails, and more.
Works with LlamaIndex, Langchain, CrewAI, Google ADK—you name it.
1-command deploy & autoscaling
Guardrails via Agent-Graph-System
Distributed state & memory baked in
50+ MCP-compatible tools & integrations
Real-time event streaming (Slackbots, Webhooks, A2A)
GitHub repo → (don’t forget to star it)
Audio RAG with 200x cheaper vector DB costs
Recently, we talked about voyage-context-3, a new embedding model that:
cuts vector DB costs by ~200x.
outperforms OpenAI and Cohere models.
Today, let’s use it to do RAG over audio data.
We'll also use:
MongoDB Atlas Vector Search as vector DB
AssemblyAI for transcription
LlamaIndex for orchestration
gpt-oss as the LLM
For context...
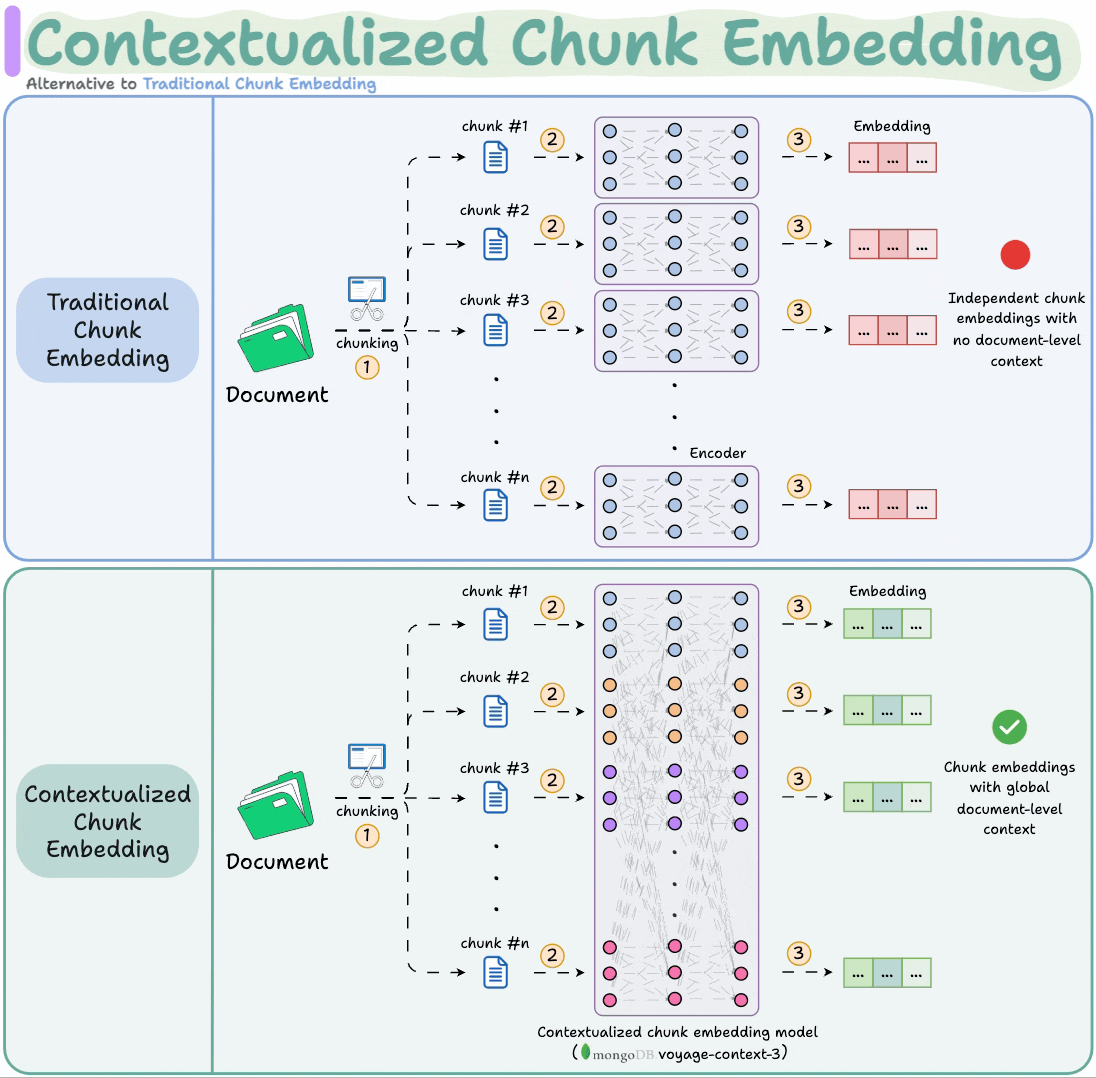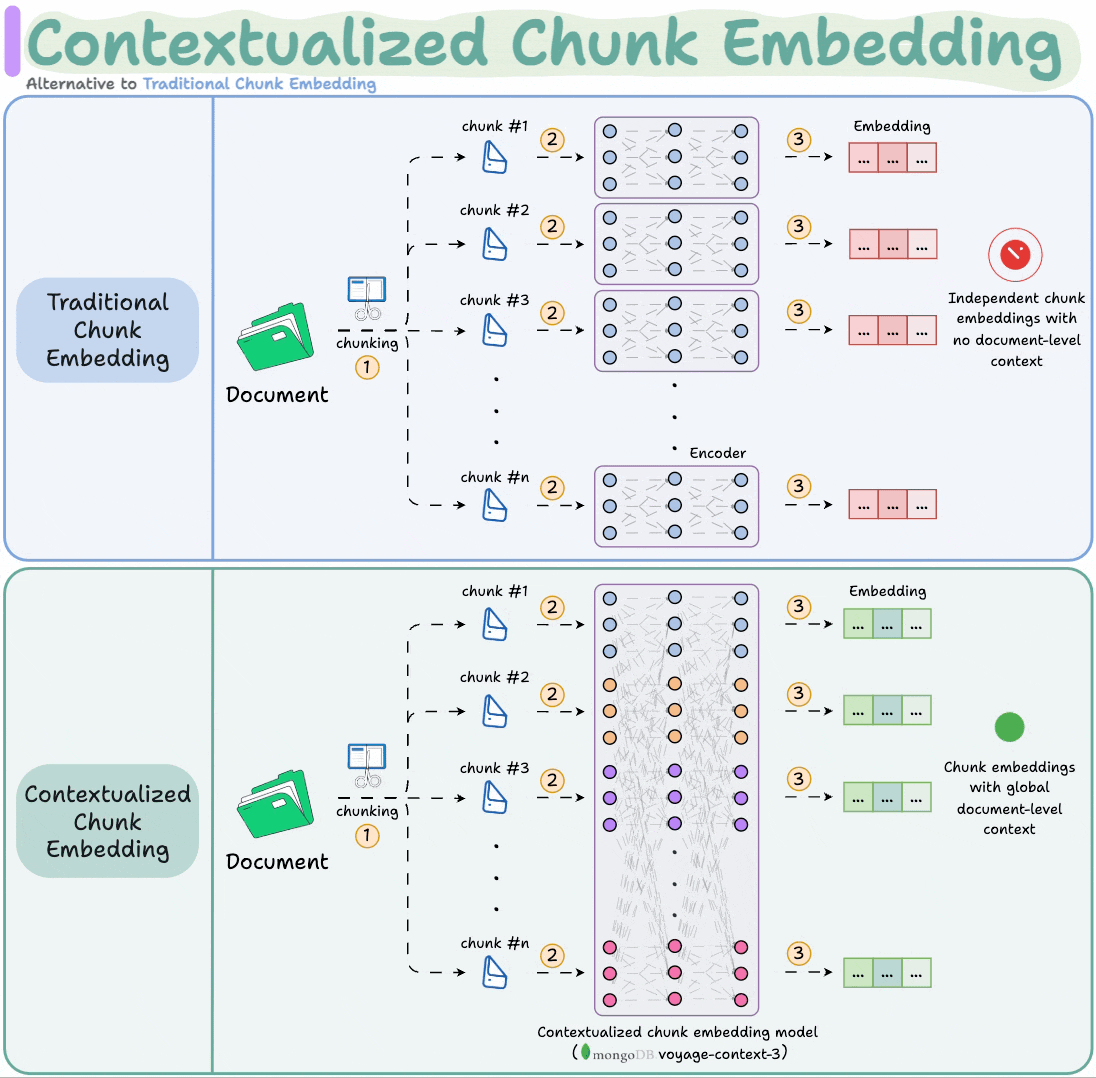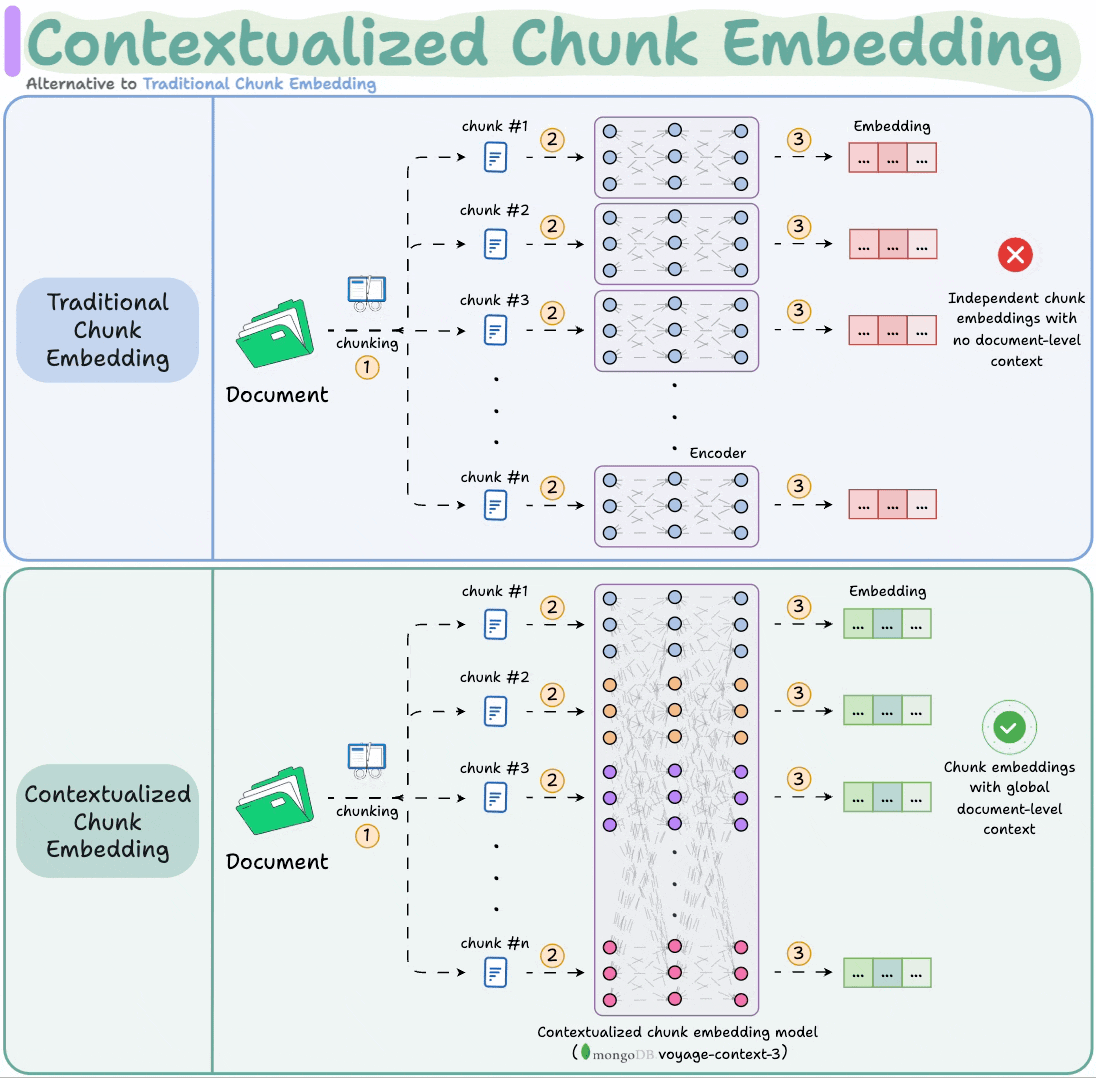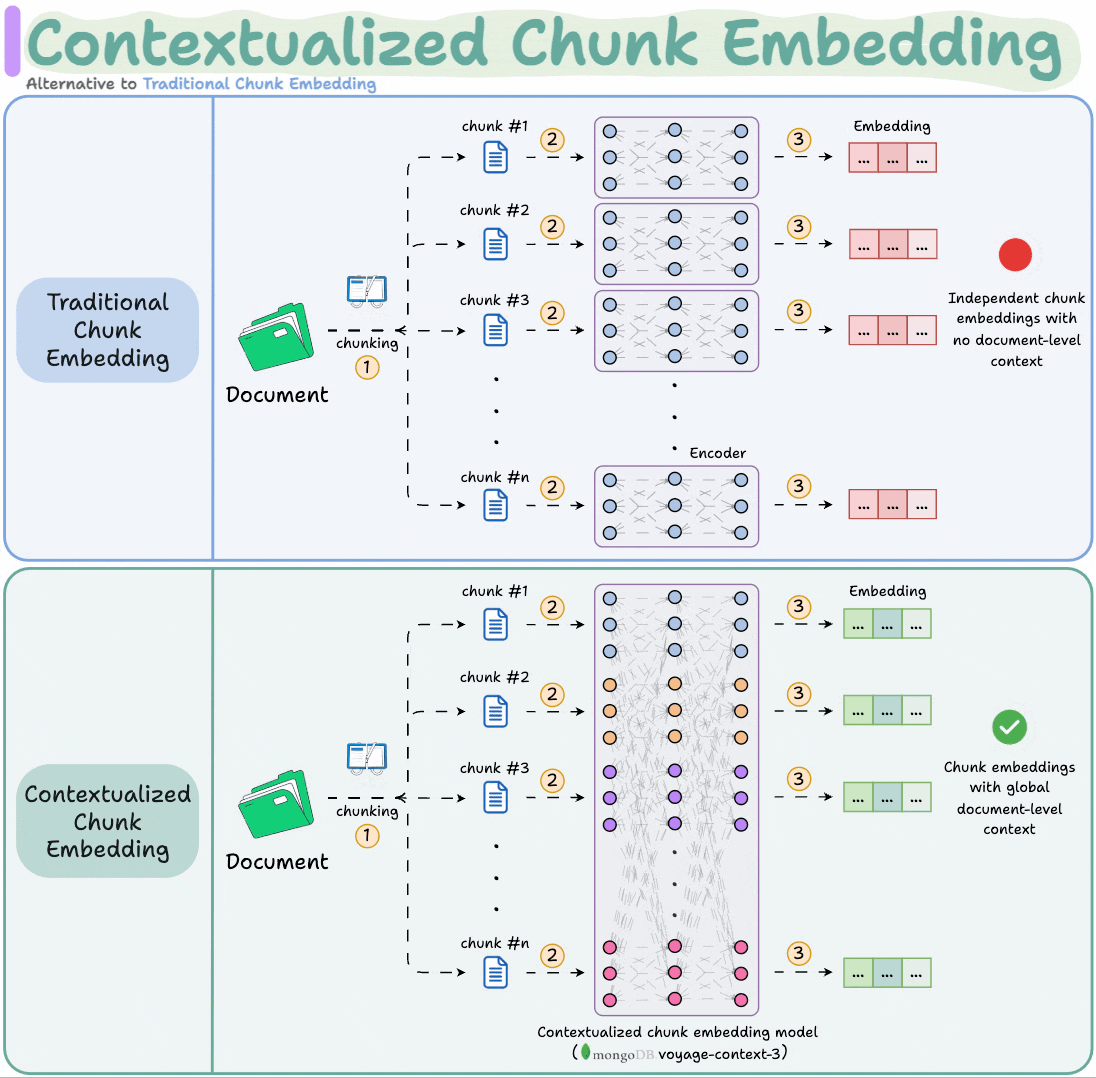
voyage-context-3 is a contextualized chunk embedding model that produces chunk embeddings with full document context.
This is unlike common chunk embedding models that embed chunks independently.
(We'll discuss the results later)
Here's an overview of our app:
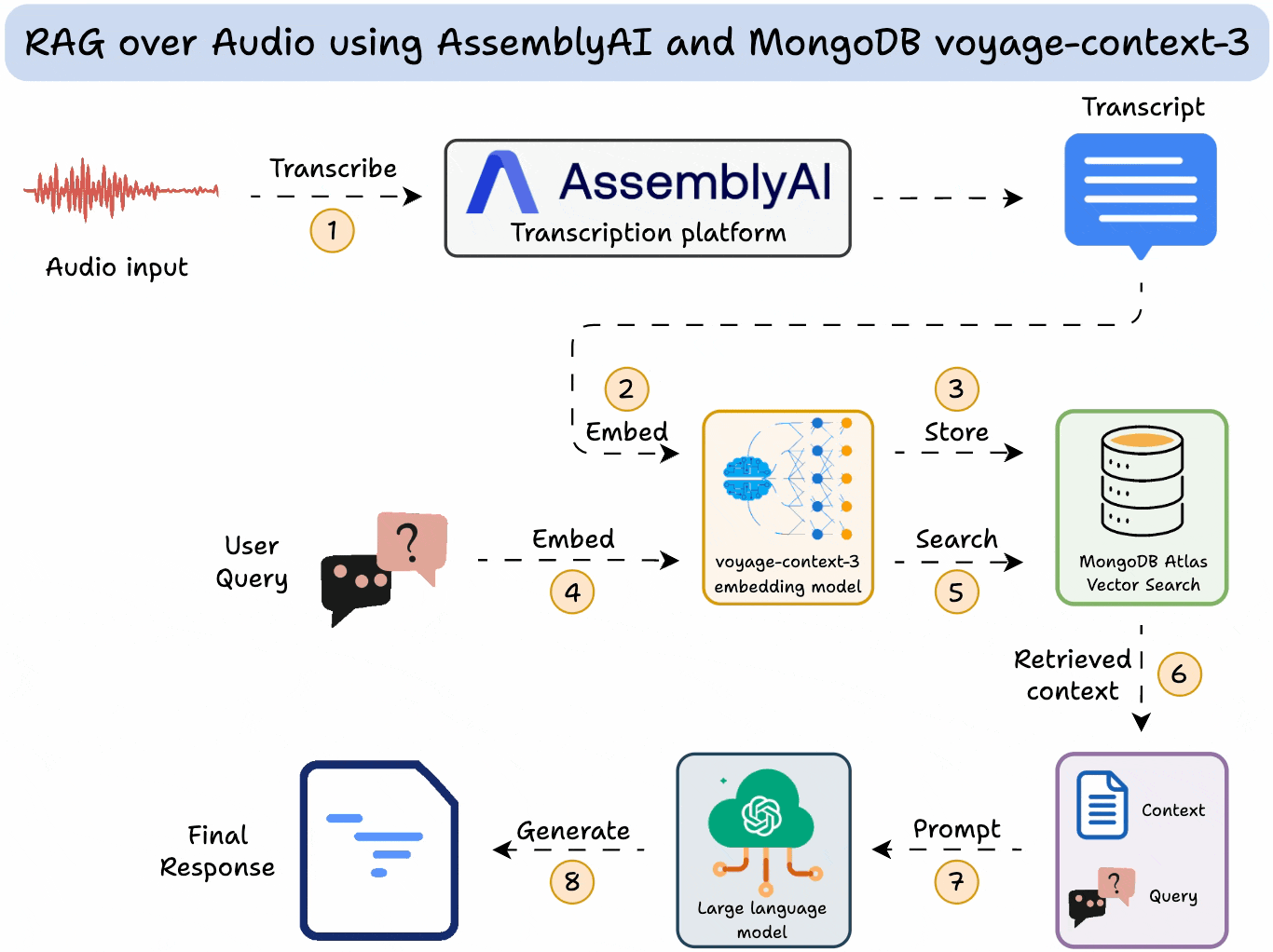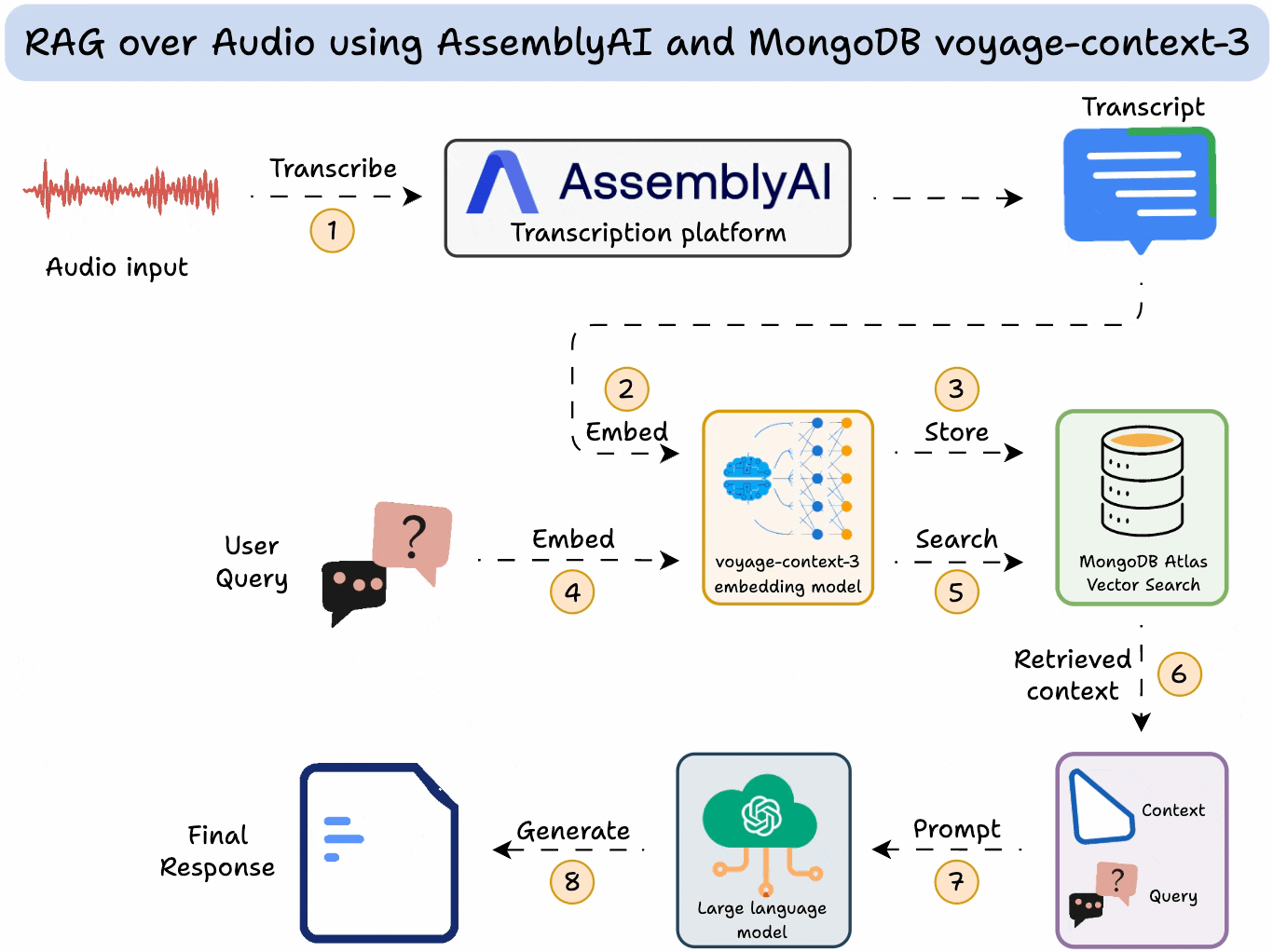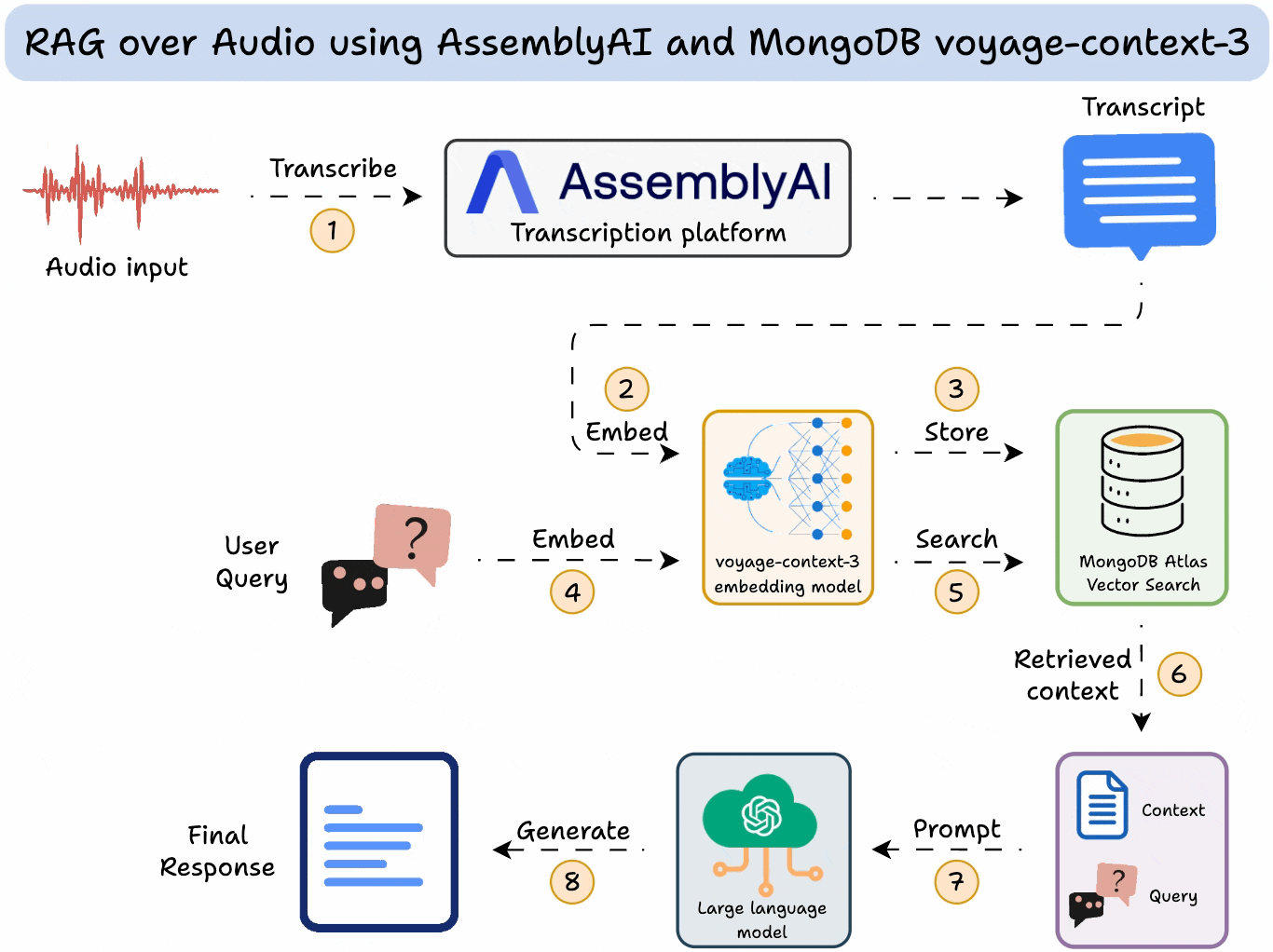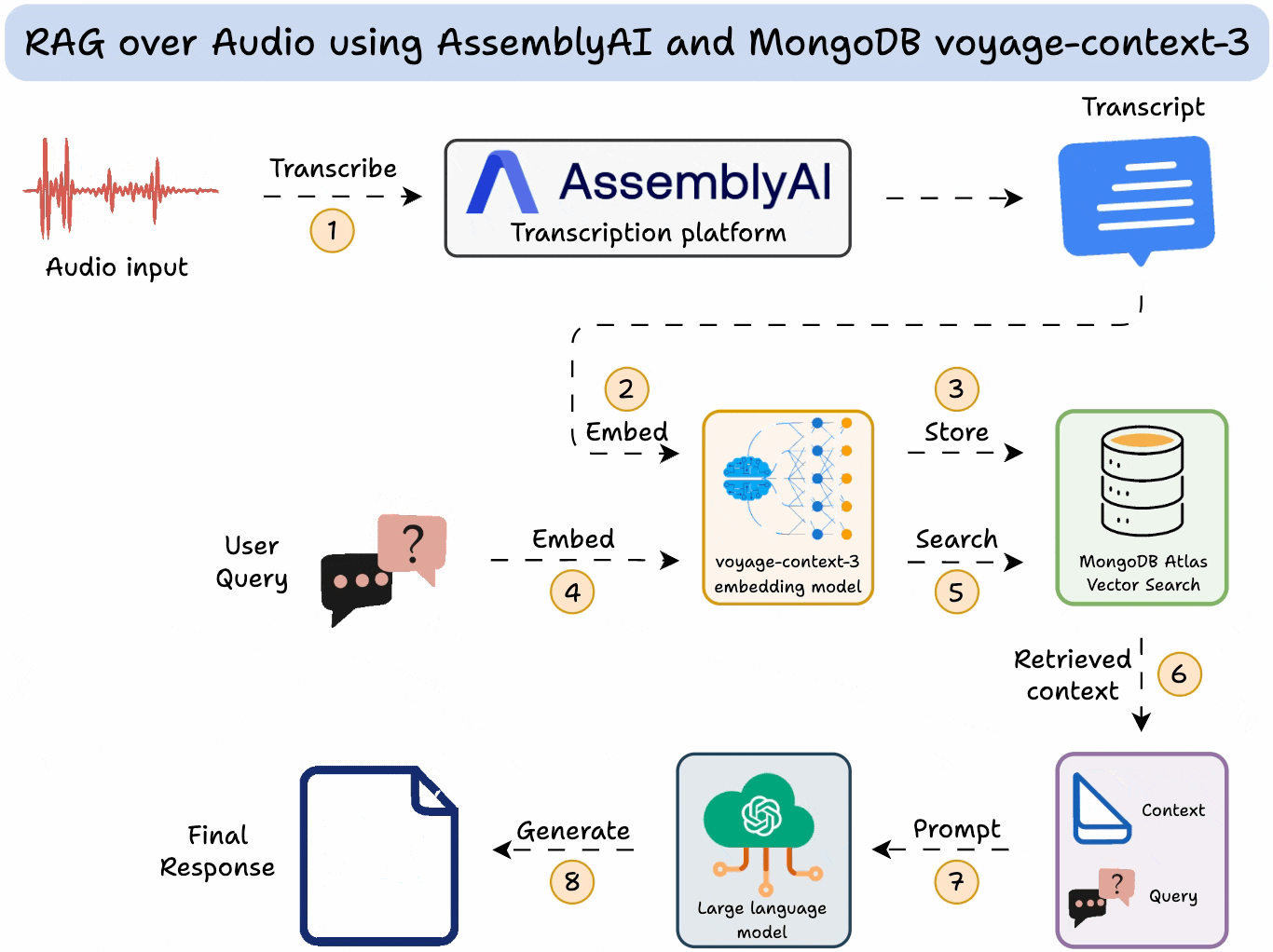
Transcribe the audio using AssemblyAI
Embed the transcript using MongoDB's voyage-context-3 model.
Store it in a vector DB.
Query the vector DB to get context.
Use gpt-oss as the LLM to generate a response.
Get the API key
Assembly and MongoDB are not open-source. But they give you ample free credits, which are more than sufficient for this demo.
We need two API keys to run this project.
Store them in the .env file.

Transcription
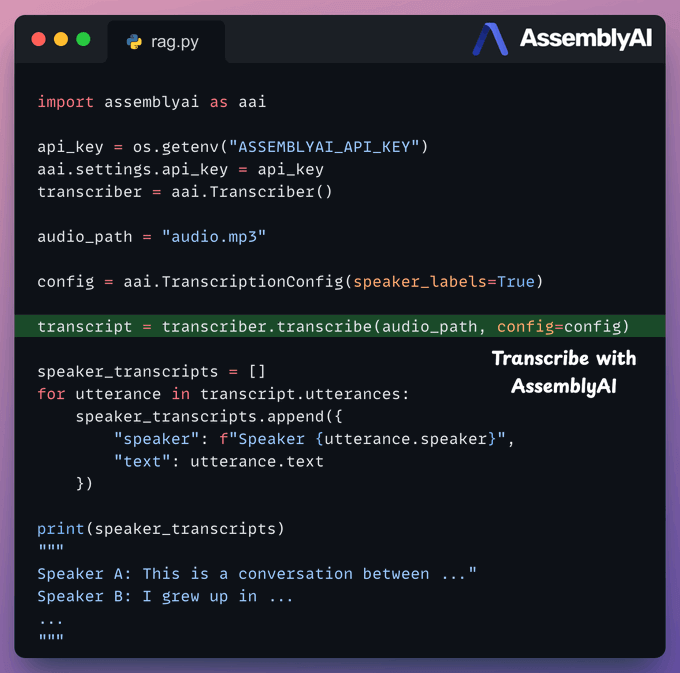
We use AssemblyAI to transcribe audio with speaker labels.
To do this:
We set up the transcriber object.
We enable speaker label detection in the config.
We transcribe the audio using AssemblyAI.
Embed transcripts and store them in a vector DB
To do this, we:
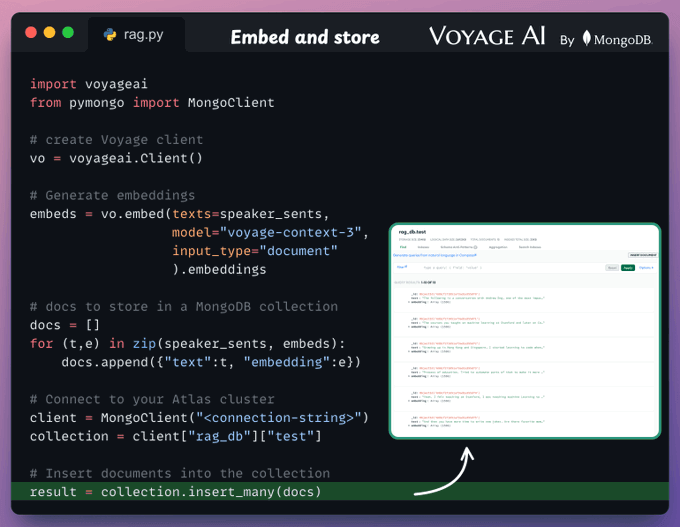
Create a Voyage client and generate embeddings.
Instantiate a MongoDB Atlas Vector Search client.
Create a vector DB collection in the client.
Push the embeddings.
Retrieval
Now, to retrieve relevant context from the vector DB, we:
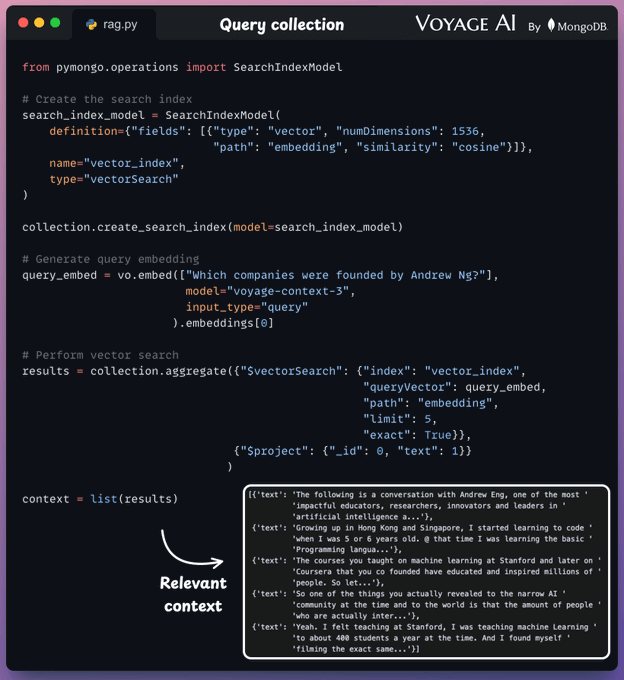
Define a search index.
Convert the text query into an embedding.
Perform a vector search to get the relevant context.
Generate response
Finally, after retrieving the context:
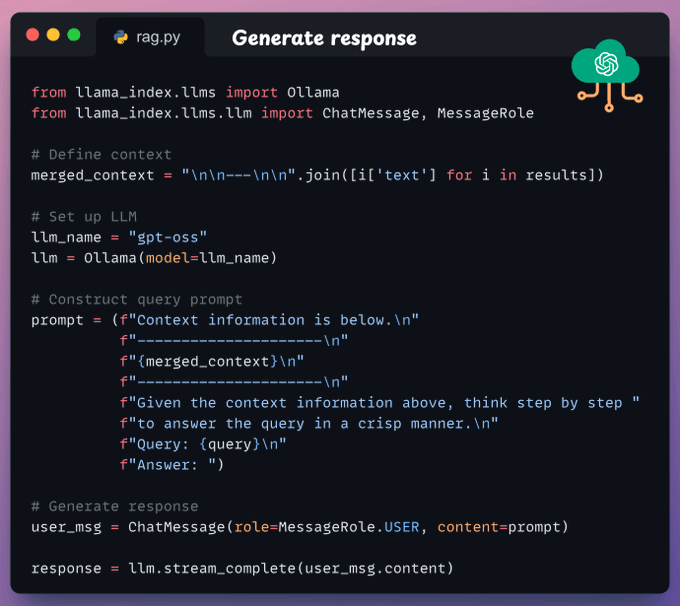
We construct a prompt.
We use gpt-oss served via Ollama to generate a response.
Streamlit UI
To make this accessible, we wrap the entire app in a Streamlit interface.
It’s a simple UI where you can upload and chat with the audio file directly.
You can check the demo below.
We used voyage-context-3 because of the following:
RAG is 80% retrieval and 20% generation.
So if RAG isn't working, most likely, it's a retrieval issue, which further originates from chunking and embedding.
voyage-context-3 solves this.
It is a contextualized chunk embedding model that produces vectors for chunks that capture the full document context without any manual metadata and context augmentation.
This is unlike common chunk embedding models that embed chunks independently.
This makes your embeddings semantically rich and context-aware, without the overhead of dealing with metadata, and hence the speed.
Across 93 retrieval datasets, spanning nine domains (web reviews, law, medical, long documents, etc.):
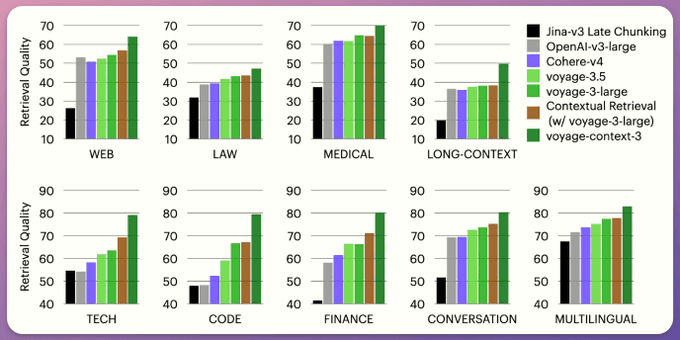
voyage-context-3 outperforms:
all models across all domains
OpenAI-v3-large by 14.2%
Cohere-v4 by 7.89%
Jina-v3 by 23.66%
Also, it cuts vector DB costs by ~200x because compared to OpenAI-v3-large (float, 3072d). voyage-context-3 (binary, 512) offers 0.73% better retrieval quality.
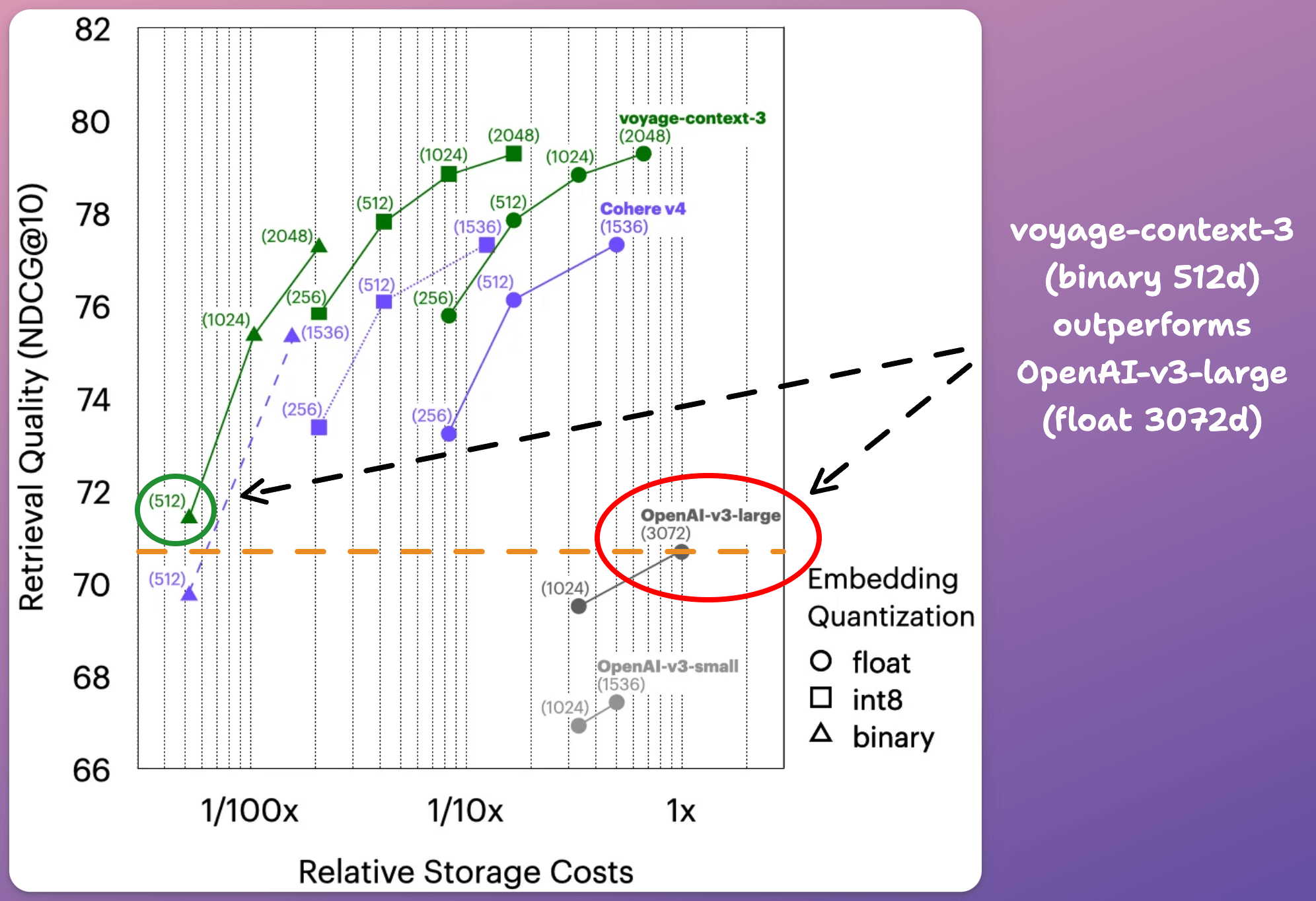
This means:
6x reduction in embedding size
and 32x reduction in precision (binary vs float32)
which totals 32*6 = a little under 200x.
In terms of practical usage...
voyage-context-3 can be used as a drop-in replacement for standard embeddings, with minimal changes.
It accepts all chunks of a doc at once, instead of embedding each chunk separately.
Over to you: Which aspect of voyage-context-3 do you find the most interesting?
Thanks to the MongoDB team for working with us on this demo!
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
