

A better way to build LLM-as-a-judge pipelines
Teams usually validate their agents’ outputs by calling a frontier model as the judge. It works, but three problems stack up fast:
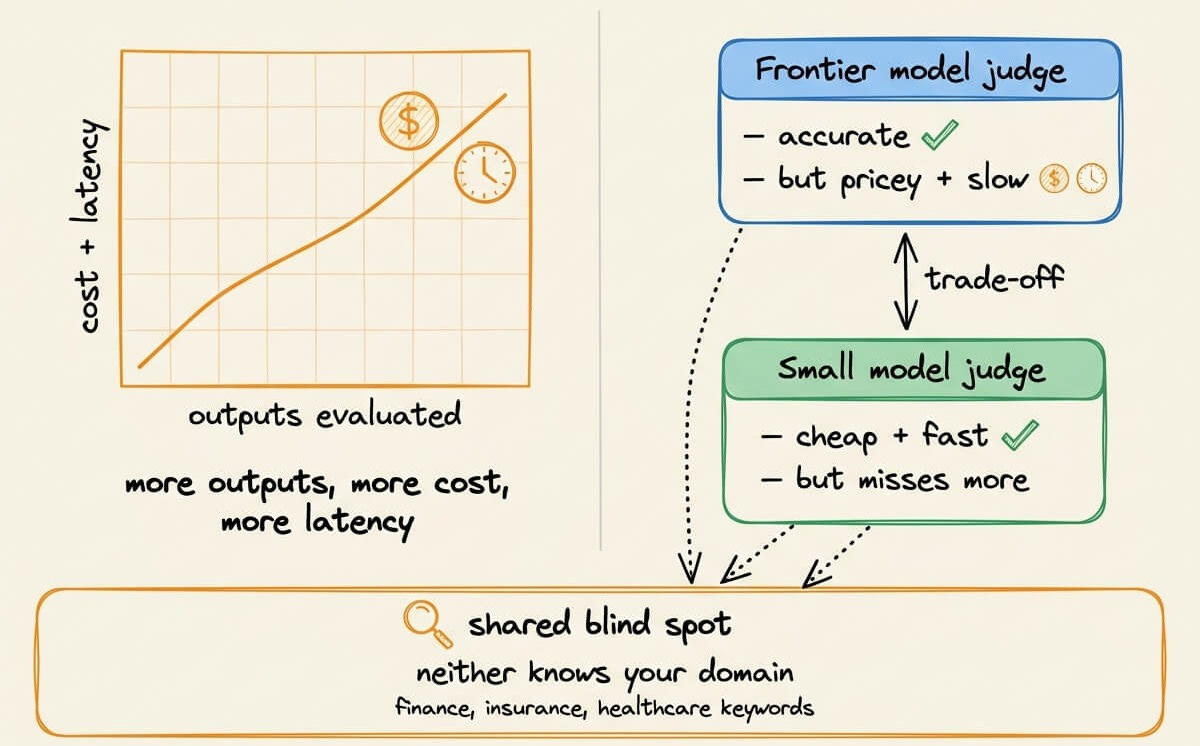
Cost: you’re hitting a frontier API on every turn, every tool call, every response. In production that burns millions.
Latency: bigger models, remote calls, slow reasoning on every check.
Blind spots: frontier models don’t actually know your domain. In finance, insurance, or healthcare, they miss the keywords and principles your work depends on.
In the video above, we walk through a different approach, which is to train your own small LLM judge.
Instead of a giant model, you start with a small one and let the system generate the training data for you. It decomposes your domain, samples synthetic examples, runs them through a debate arena where judges reach consensus, and then trains on the refined set.
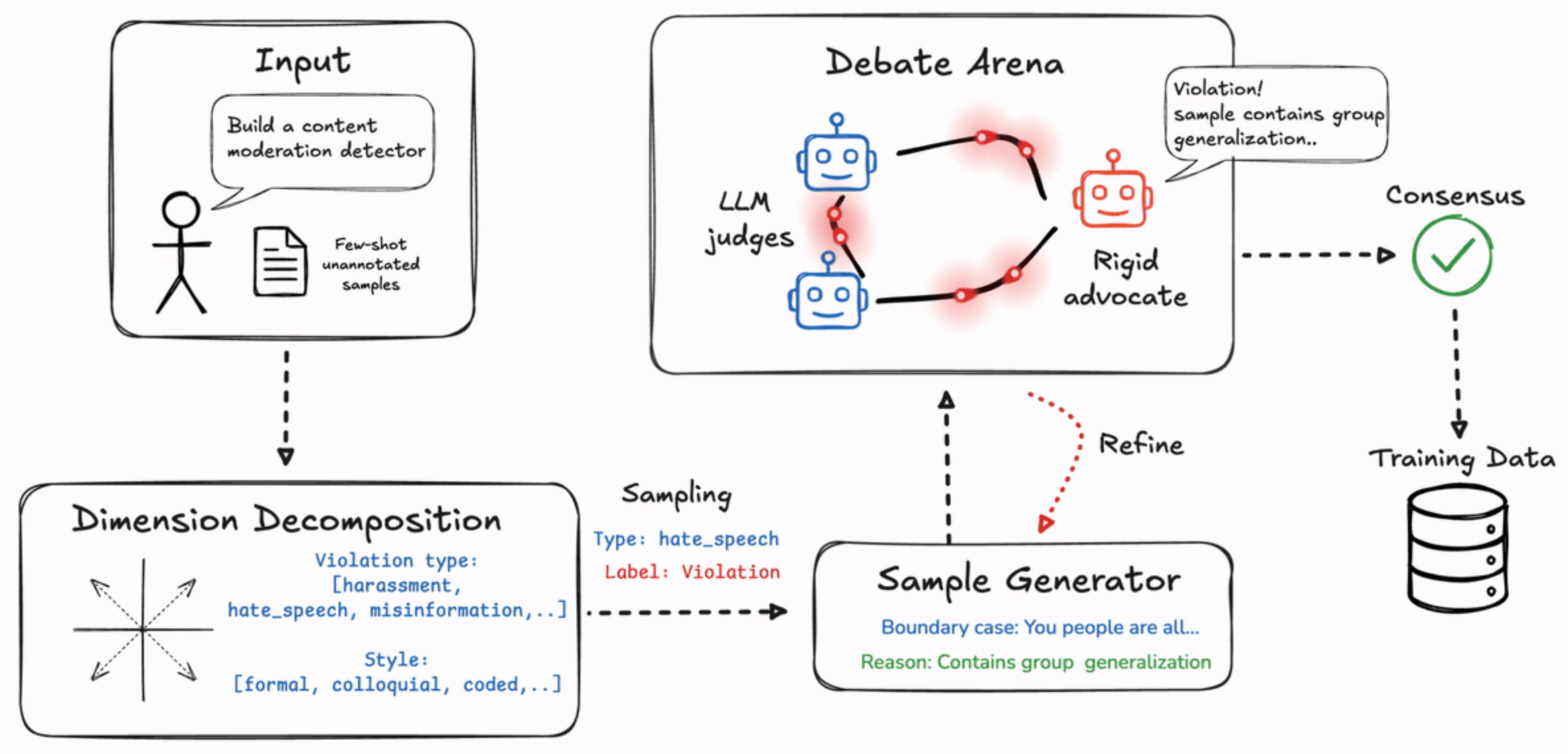
This gives you a judge that’s cheaper, faster, and more accurate on your data than Gemini, Claude, or GPT, with an OpenAI-compatible endpoint you can even deploy on-prem.
We have shown the whole thing end-to-end, using a Claude Code plugin and a web interface, with a real insurance RAG grounding evaluator as the example.
You can get the plugin on GitHub here →
Here’s the full breakdown:
00:00 - Intro
00:12 - Three problems with using frontier LLMs as judges
01:05 - A different approach: train your own small judge
01:31 - How it works (synthetic data and a debate arena)
02:50 - Installing the Claude Code plugin
04:03 - Defining your task with /eval
04:34 - Example: an insurance RAG grounding evaluator
05:51 - Kicking it off and giving early feedback
06:26 - Choosing labels, domain, and strictness
08:30 - The web interface and dashboard
09:52 - Bringing your own example data (optional)
10:26 - The finished model: endpoint, accuracy, and speed
11:16 - Control, on-prem deployment, and interpretability
11:57 - Benchmarks vs frontier models and the GitHub repo
12:30 - Outro
Thanks to the PlurAI team for working with us on this today’s issue!
Hermes Mixture of Agents (MoA) explained
An agent runs on one model, and that model’s blind spots become the agent’s blind spots.
The same LLM does the reasoning, the tool calls, and the final answer, so wherever it’s weak, nothing else in the loop is there to catch it.
The usual workaround is to run the same prompt through a few models by hand and reconcile the answers. It works, but it lives outside the agent, so the tools, the memory, and the session are gone the moment that detour starts.
Hermes Agent by Nous Research shipped a mixture of Agents, which folds that whole process back inside the agent.
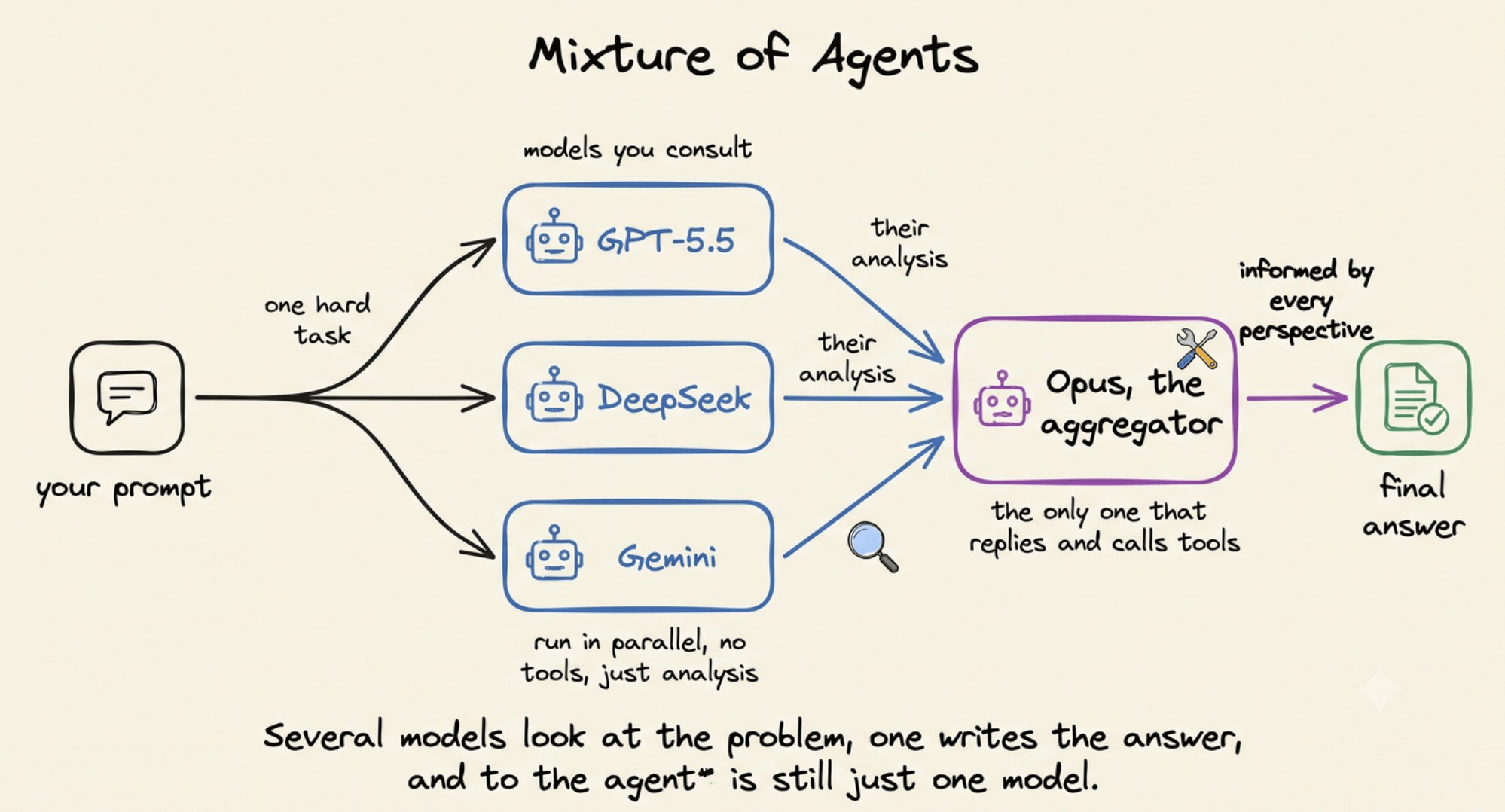
The unit you work with is a preset. Think of it as a recipe that names a few models to consult and one model to write the final answer, saved under a label you can remember and reuse.
So a preset might list GPT-5.5 and DeepSeek as the models to consult, with Opus as the one that replies. You set it up once, give it a name, and pick it later like any other model.
The models you consult run first and hand their analysis to the one writing the answer. That final model is the one that actually replies and makes the tool calls, now informed by several perspectives instead of one.
In Hermes, the preset you set up shows up as a model you can select.
So everything that already works in Hermes keeps working, like tool calls, follow-up iterations, memory, and the same session context behaves exactly as they do with a single model, because to the agent loop it is a single model.
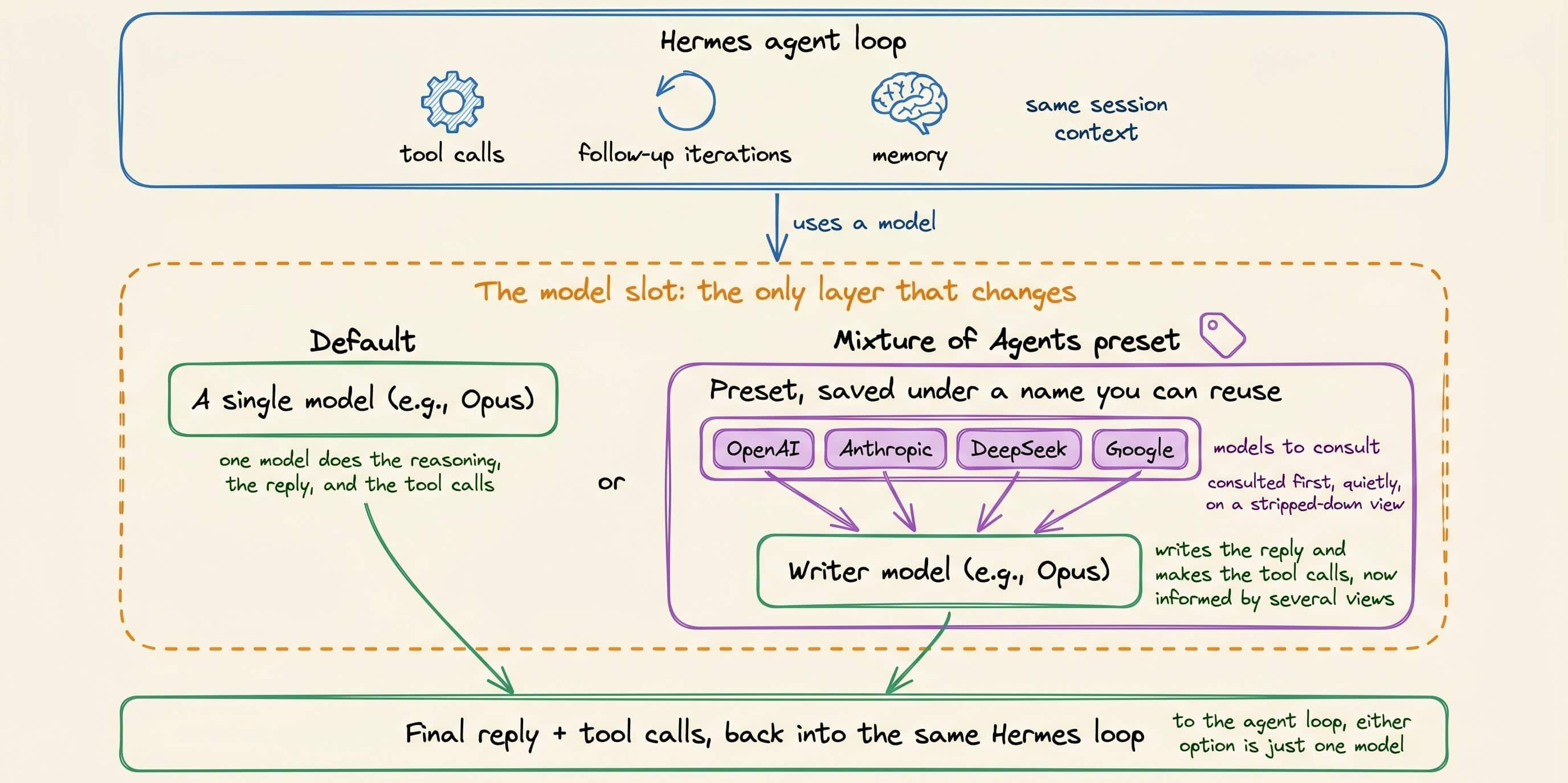
The models can come from anywhere, i.e., a preset can mix OpenAI, Anthropic, DeepSeek, and Google, and it is not capped at two.
A few things follow from that design:
It composes a model instead of choosing one. Several models covering each other’s blind spots can beat the strongest one on its own.
It stays cheap to run. The models you consult see a stripped-down view of the conversation, so the extra calls stay light and the main context keeps its cache.
It reaches past any single frontier model since it combines the providers already on hand.
It is not a default setting so that it turns on only for the hard tasks where a second opinion matters, and stays off for routine work where speed wins.
The team behind Hermes has reported the effect on its own benchmark. A preset running Opus-4.8 over a GPT-5.5 reference scored higher than either model alone, by roughly six points and eight to eleven percent.
The lesson is not that one model has to win, but rather the fact that the best answer might not always come from a single model, and the agent should make blending them as easy as picking one.
If you want to learn how to set up Hermes, we wrote a full deep dive covering the Hermes agent’s architecture, memory system, self-evolving skills, GEPA optimization, and how to set up multiple specialized agents.

Good day!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
