

Add memory and knowledge graphs to CrewAI agents

CrewAI agents with Zep's memory integration maintain persistent context, access shared knowledge, and make informed decisions across sessions.
It's like giving your agents a human-like memory.
Key Features:
Persistent conversation and knowledge storage
Automatic context retrieval during execution
User-specific and organizational memory separation
Dynamic knowledge management tools
Find more info in the docs here →
Build a YC job-finder Agentic workflow

Last week, we talked about Sim, a lightweight, user-friendly framework to build AI agent workflows in minutes.
Key features:
Real-time workflow execution
Connects with your favorite tools
Works with local models via Ollama
Intuitive drag-and-drop interface using ReactFlow
Multiple deployment options (NPM, Docker, Dev Containers)
Based on our testing, Sim is a better alternative to n8n with:
An intuitive interface
A much better copilot for faster builds
AI-native workflows for intelligent agents
We used it to build a job finder for top YC startups & connected it to Telegram in minutes.
Tech stack:
The video below provides a step-by-step guide along with all the setup instructions.
You can also find all the details in Sim's GitHub repository.
GitHub repo → (don’t forget to star)
Thanks for reading!
5 levels of evolution of AI Agents
Over the last few years, we’ve gone from simple LLMs → to fully-fledged Agentic systems with reasoning, memory, and tool use.
Here’s a step-by-step breakdown.
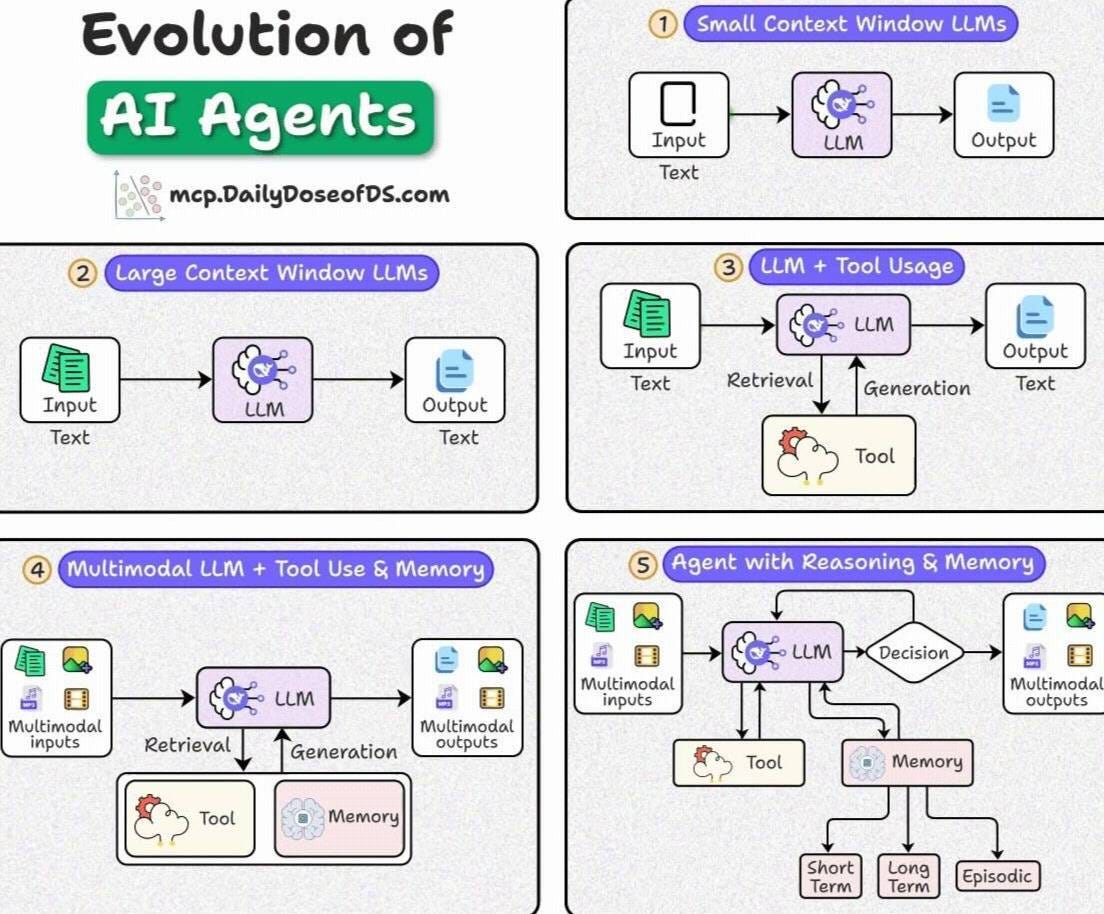
1) Small context window LLMs
Input: Text → LLM → Output: Text
Early transformer-based chatbots.
Could only process small chunks of input (short conversations, limited docs).
For instance, when ChatGPT came out, it offered a context window of just 4k tokens.
2) Large context window LLMs
Input: Large Text/Docs → LLM → Output: Text
Models like Claude/ChatGPT upgraded to handle tens of thousands tokens.
Allowed parsing bigger documents and longer conversations.
3) LLM + tool usage (RAG era)
Input: Text → LLM + Retrieval/Tool → Output: Text
Retrieval-Augmented Generation gave access to fresh + external data.
Tools like search APIs, calculators, and databases boosted LLM outputs.
4) Multimodal LLM + tool use + memory
Input: Text + Images + other modalities → LLM + Tool + Memory → Output: Multimodal
Agents could process multiple data types (text, images, audio).
Memory introduced persistence across interactions.
5) Agents with reasoning & memory
Input: Multimodal → LLM → Decision → Output: Multimodal
Equipped with:
Short-term, Long-term, and Episodic Memory
Tool Calling (search, APIs, actions)
Reasoning & ReAct-based decision-making
Essentially, this is the AI Agent era we’re living in today.
👉 Over to you: What do you think the next level will look like from here?
That said, we did a crash course to help you implement reliable Agentic systems, understand the underlying challenges, and develop expertise in building Agentic apps on LLMs, which every industry cares about now.
Here’s everything we did in the crash course (with implementation):
In Part 1, we covered the fundamentals of Agentic systems, understanding how AI agents act autonomously to perform tasks.
In Part 2, we extended Agent capabilities by integrating custom tools, using structured outputs, and we also built modular Crews.
In Part 3, we focused on Flows, learning about state management, flow control, and integrating a Crew into a Flow.
In Part 4, we extended these concepts into real-world multi-agent, multi-crew Flow projects.
In Part 5 and Part 6, we moved into advanced techniques that make AI agents more robust, dynamic, and adaptable, like Guardrails, Async execution, Callbacks, Human-in-the-loop, Multimodal Agents, and more.
In Part 8 and Part 9, we primarily focused on 5 types of Memory for AI agents, which help agents “remember” and utilize past information.
In Part 10, we implemented the ReAct pattern from scratch.
In Part 11, we implemented the Planning pattern from scratch.
In Part 12, we implemented the Multi-agent pattern from scratch.
In Part 13 and Part 14, we covered 10 practical steps to improve Agentic systems.
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
Thanks for reading!
