

Reinforcement learning for LLMs always had one major problem: manually defining reward functions.
You have to figure out how to score model outputs, handle edge cases, and tune everything until training works.
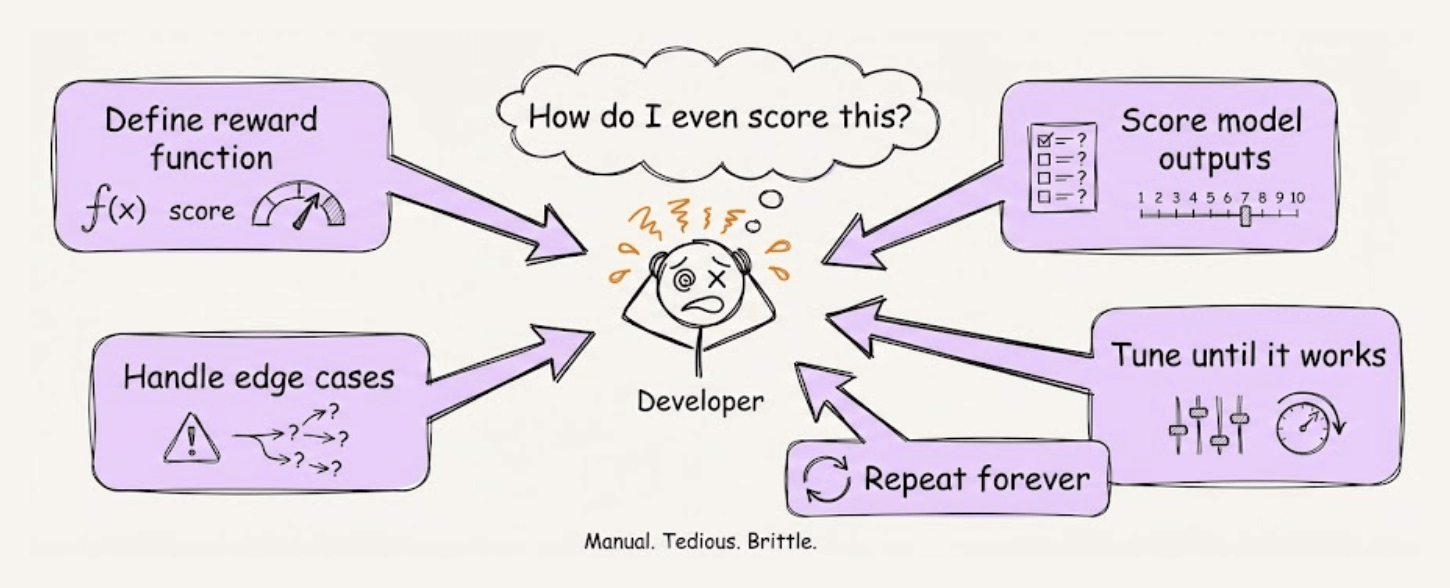
ART (Agent Reinforcement Trainer) is an open-source framework that solves this with a simple approach:

Let the agent attempt tasks multiple times
An LLM judge relatively grades each attempt
The model learns from what worked vs what didn’t
Notice that it needs no manual reward engineering. You don’t have to manually score output or tune penalties. You just need to know which attempt was better, and LLM judges are naturally great at that comparison.
If this sounds familiar, it’s because it’s the core idea behind GRPO (Group Relative Policy Optimization), the algorithm that made DeepSeek R1 so effective.
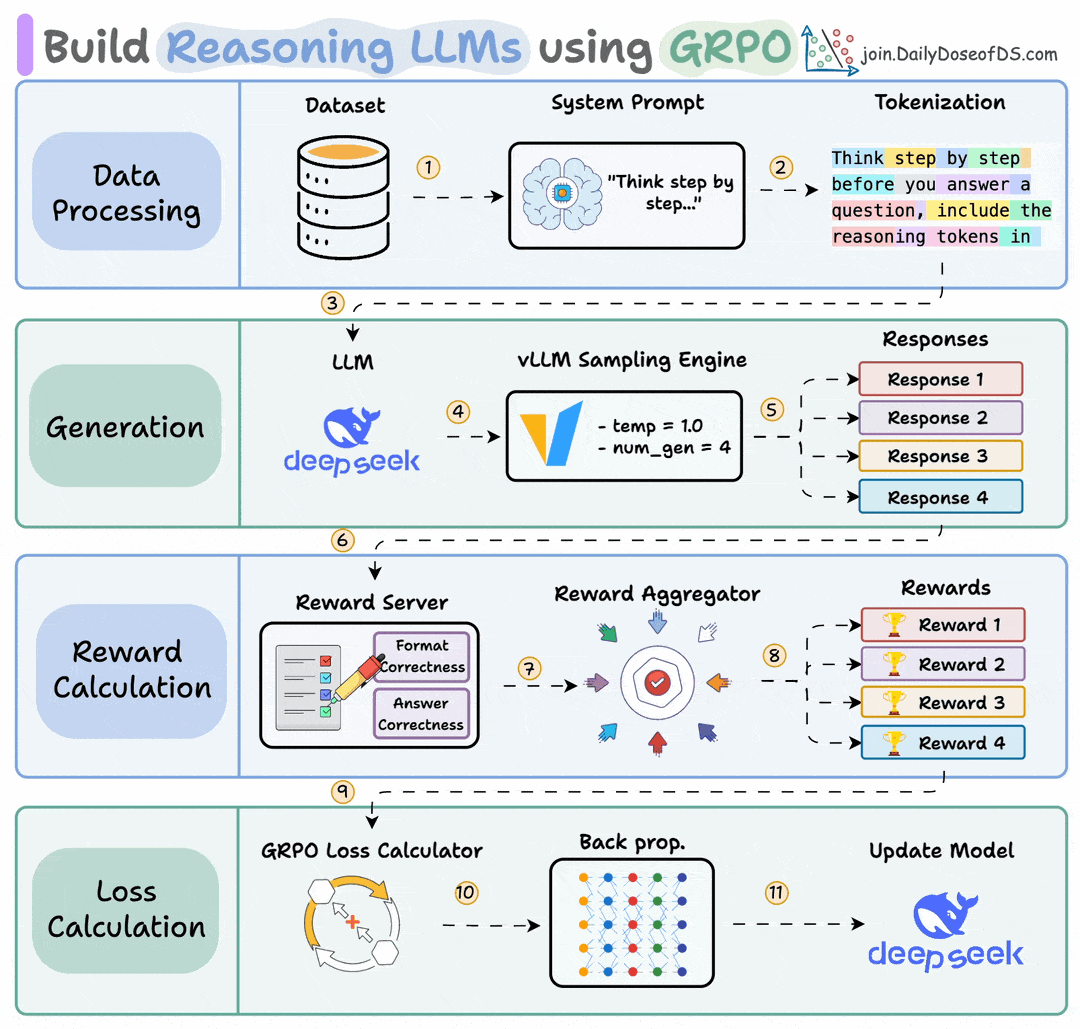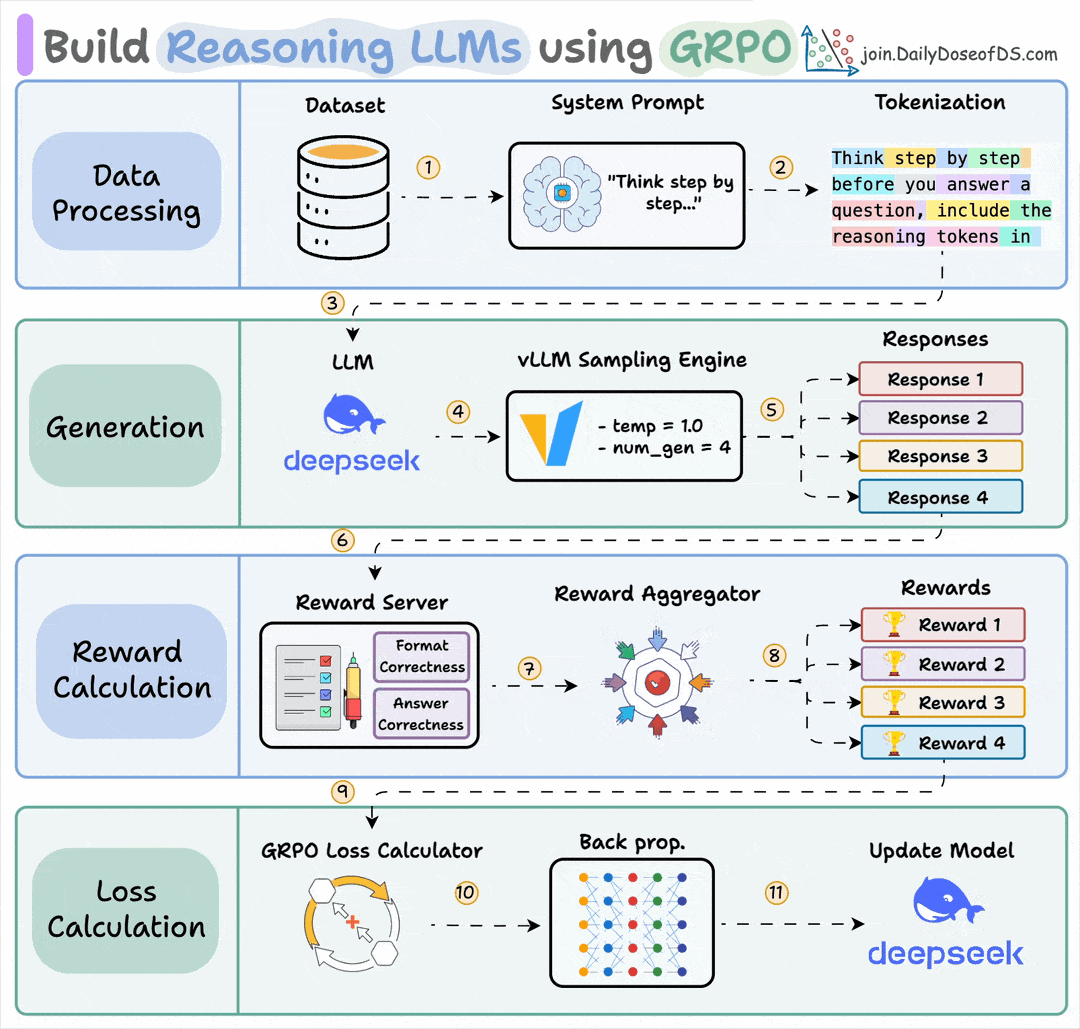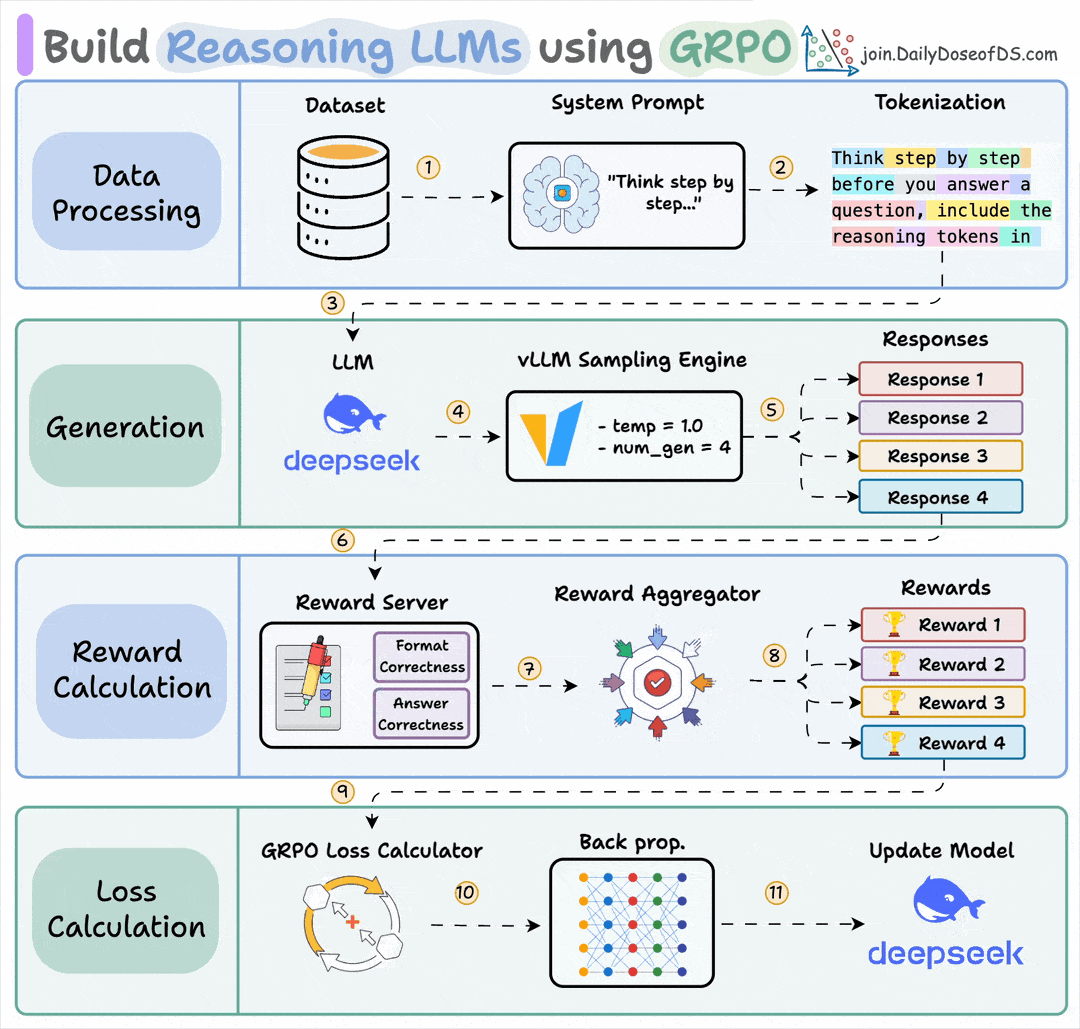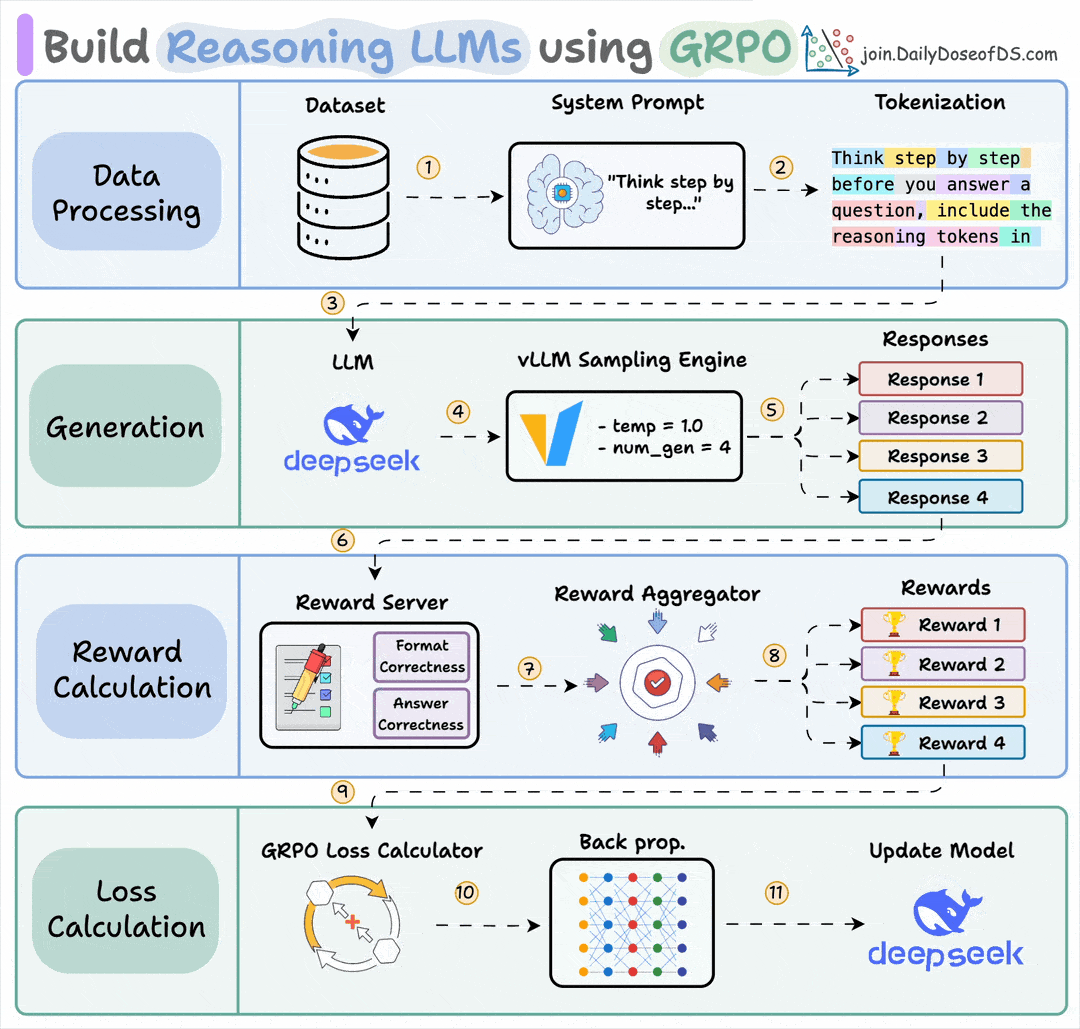
But here’s what makes ART different.
Most RL frameworks are built for simple chatbot interactions.
One input, one output, and done. But real-world agents search through documents, invoke APIs, and reason across multiple steps before completing a task.
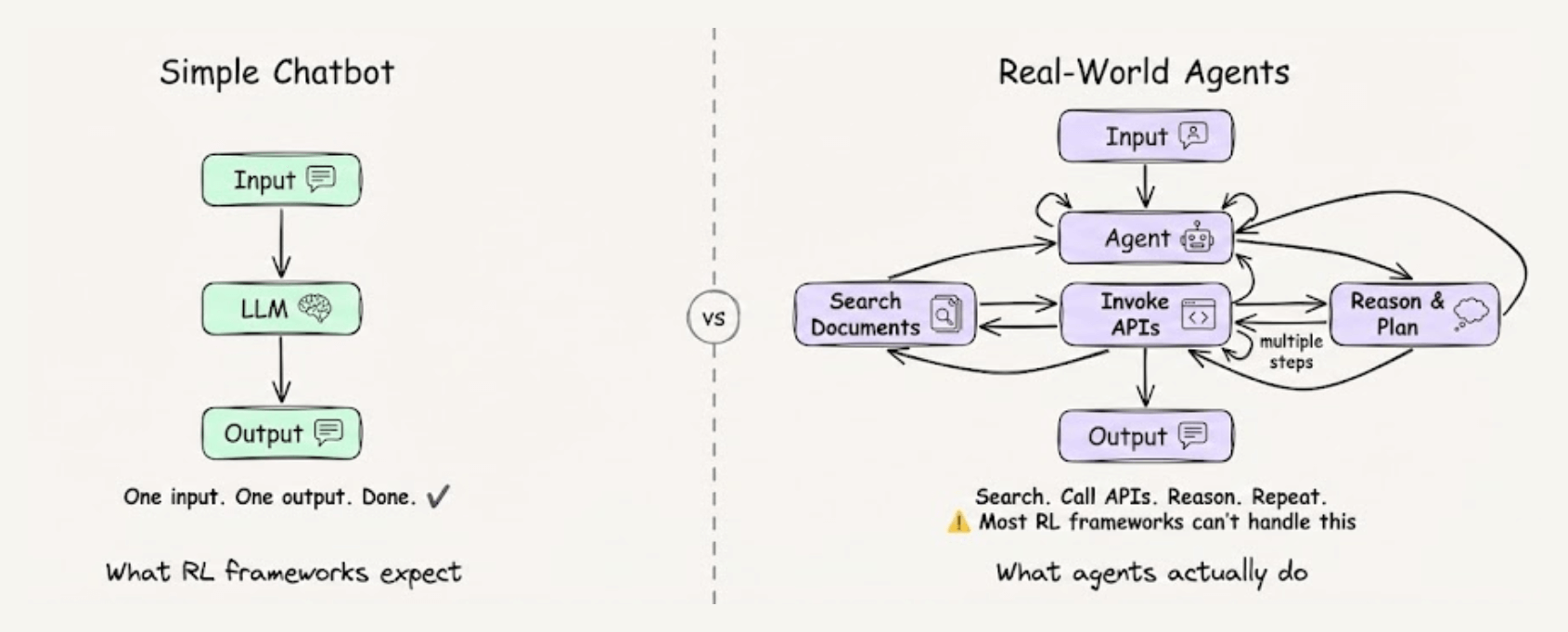
Most RL frameworks can’t handle this complexity, but ART can.
It provides:
Native support for tool calls and multi-turn conversations.
Integrations with LangGraph, CrewAI, and ADK.
Efficient GPU utilization during training.
It handles the entire infrastructure using vLLM to serve models and generate trajectories, and Unsloth to apply GRPO and run training.
These are two of the most popular open-source LLM frameworks, stitched together into one seamless workflow.
This means you can easily fine-tune a small open-source model to outperform sophisticated closed-source models on your specific task.
In the video at the top, we walk through the entire process:
setting up ART,
understanding how the GRPO training loop works,
and fine-tuning Qwen to intelligently search through emails.
Everything runs locally. 100% open-source.
What you learn here can be applied to any problem.
You can find the ART GitHub repo here →
It has the notebook from the video, plus additional examples!
Thanks for watching!
