

Stay ahead in Tech with AWS Developer Center!

Build better with AWS, using tips and tools from the Developer Center:
Get hands-on with DevOps, Data & ML, and Generative AI.
Use any language, level up your skills.
Connect with like-minded devs all over the world on AWS Communities.
The AWS Developer Center has everything you need in one place.
Thanks to AWS for partnering on today’s issue!
KV Caching in LLMs
KV caching is a popular technique to speed up LLM inference.
To get some perspective, look at the inference speed difference in the video above.
with KV caching → 9 seconds
without KV caching → 40 seconds (~4.5x slower, and this gap widens as more tokens are produced).
Today, let’s visually understand how KV caching works.
Let's dive in!
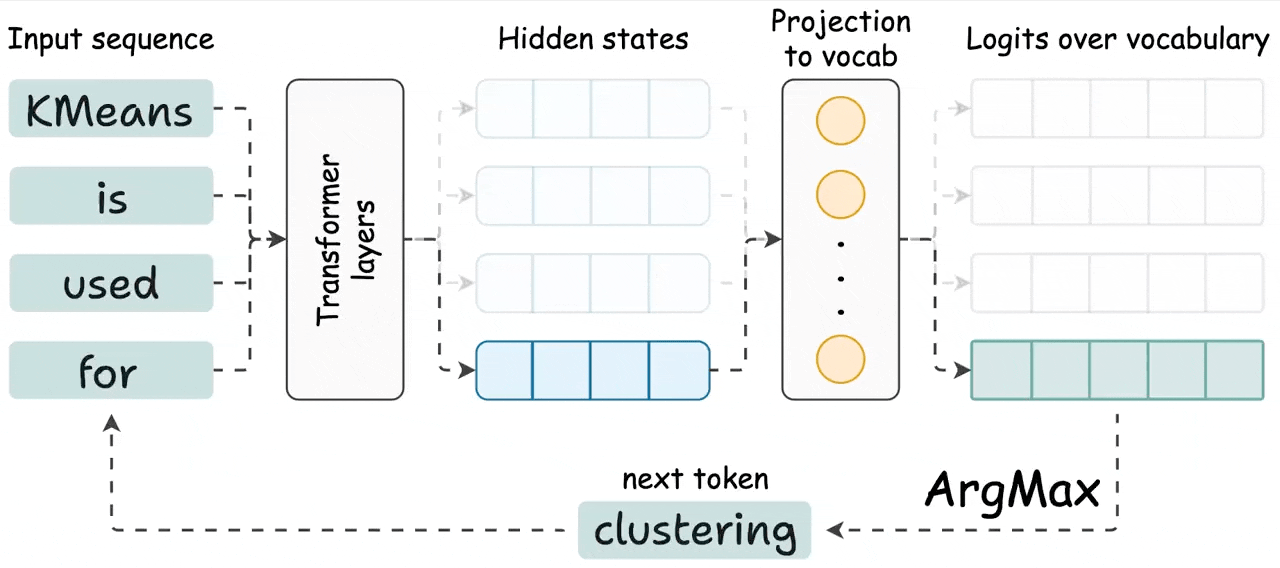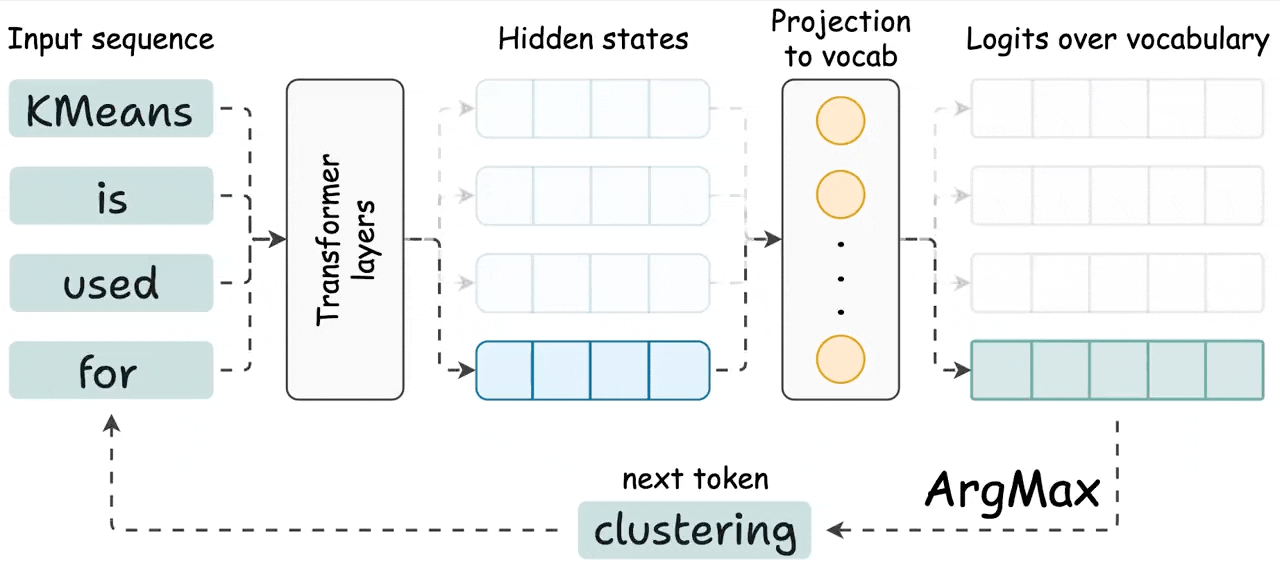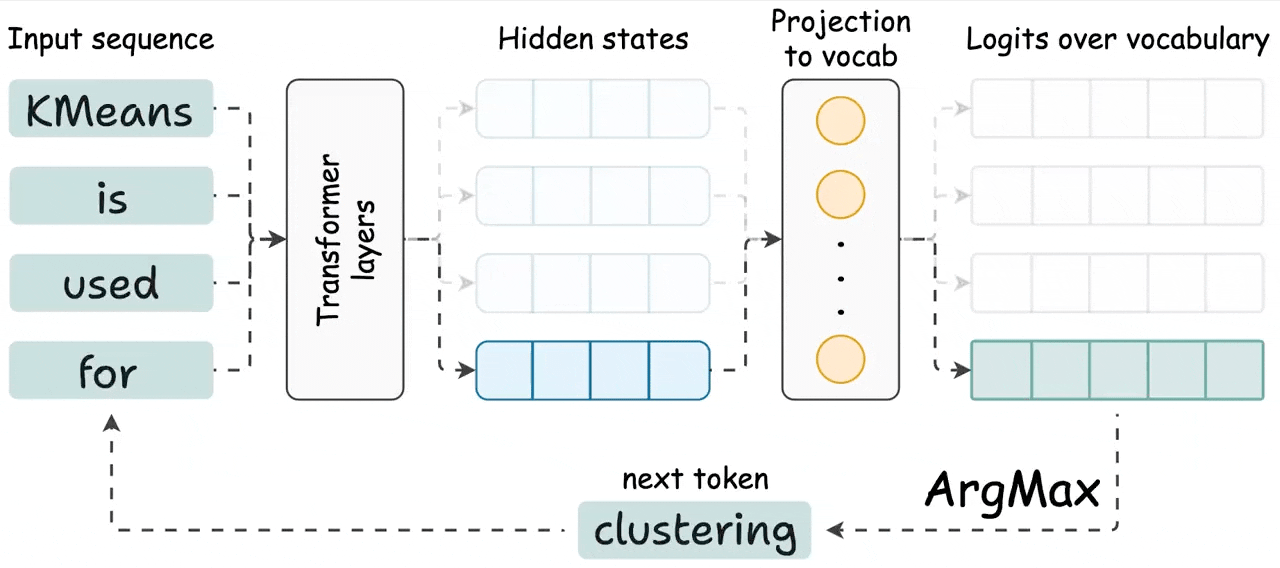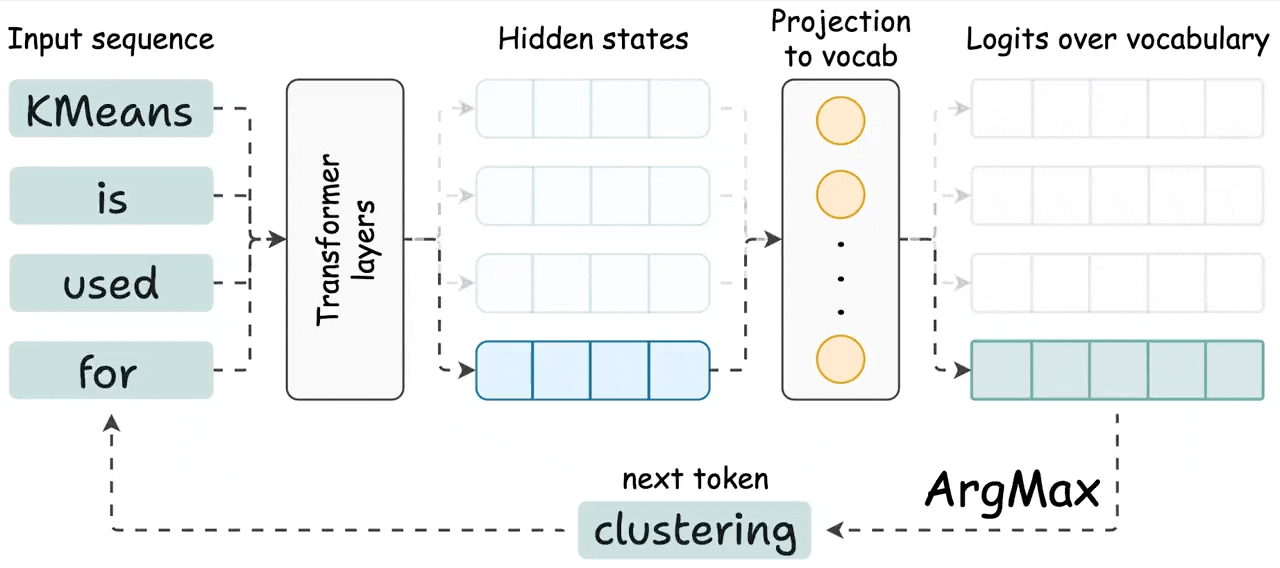
To understand KV caching, we must know how LLMs output tokens.

As shown in the visual above:
Transformer produces hidden states for all tokens.
Hidden states are projected to vocab space.
Logits of the last token is used to generate the next token.
Repeat for subsequent tokens.
Thus, to generate a new token, we only need the hidden state of the most recent token. None of the other hidden states are required.
Next, let's see how the last hidden state is computed within the transformer layer from the attention mechanism.
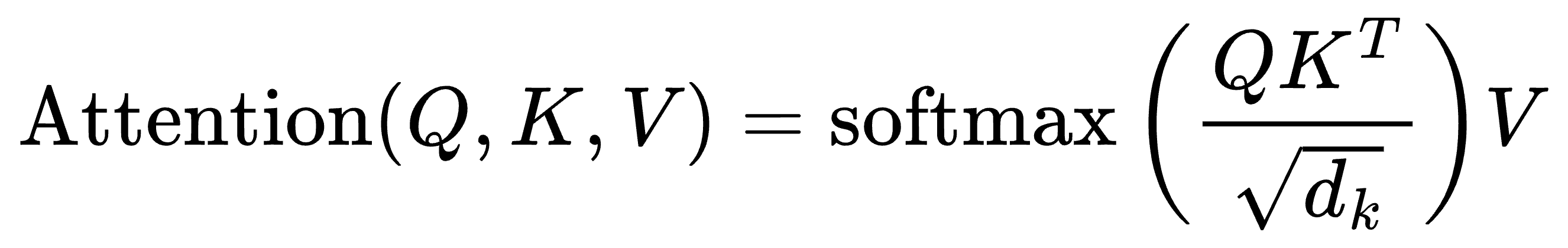
During attention, we first do the product of query and key matrices, and the last row involves the last token’s query vector and all key vectors:

None of the other query vectors are needed during inference.
Also, the last row of the final attention result involves the last query vector and all key & value vectors. Check this visual to understand better:
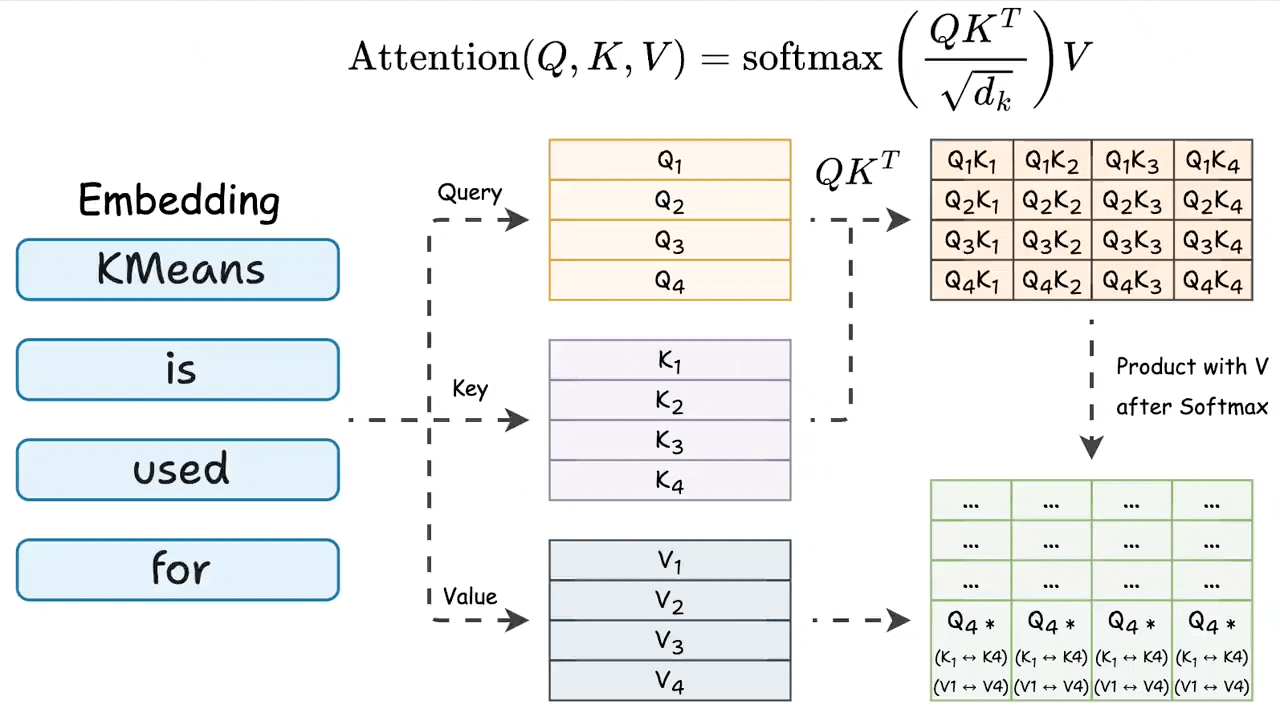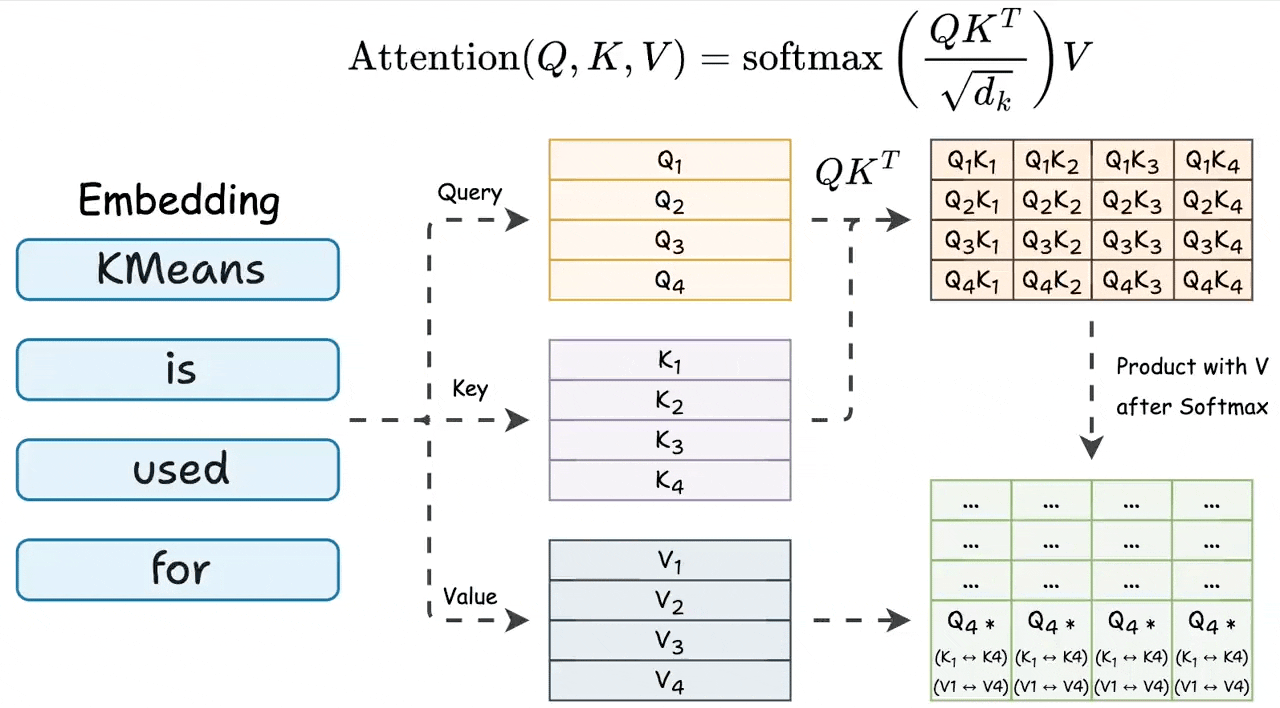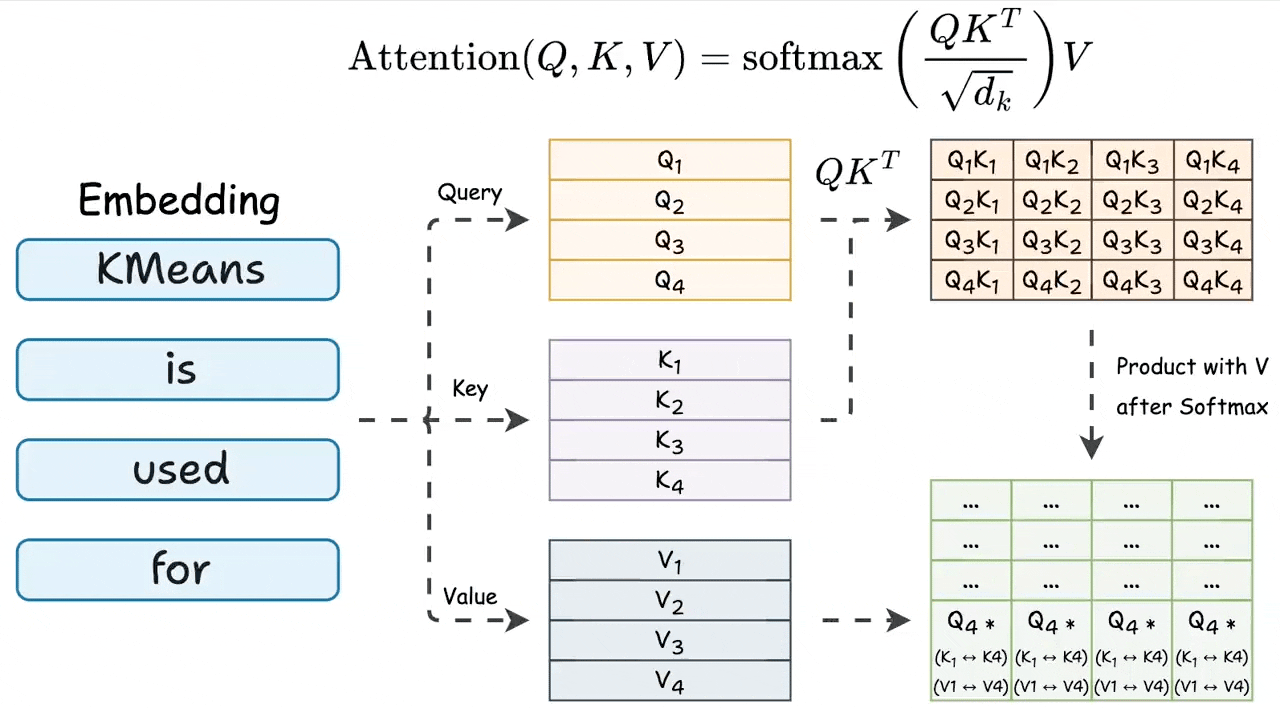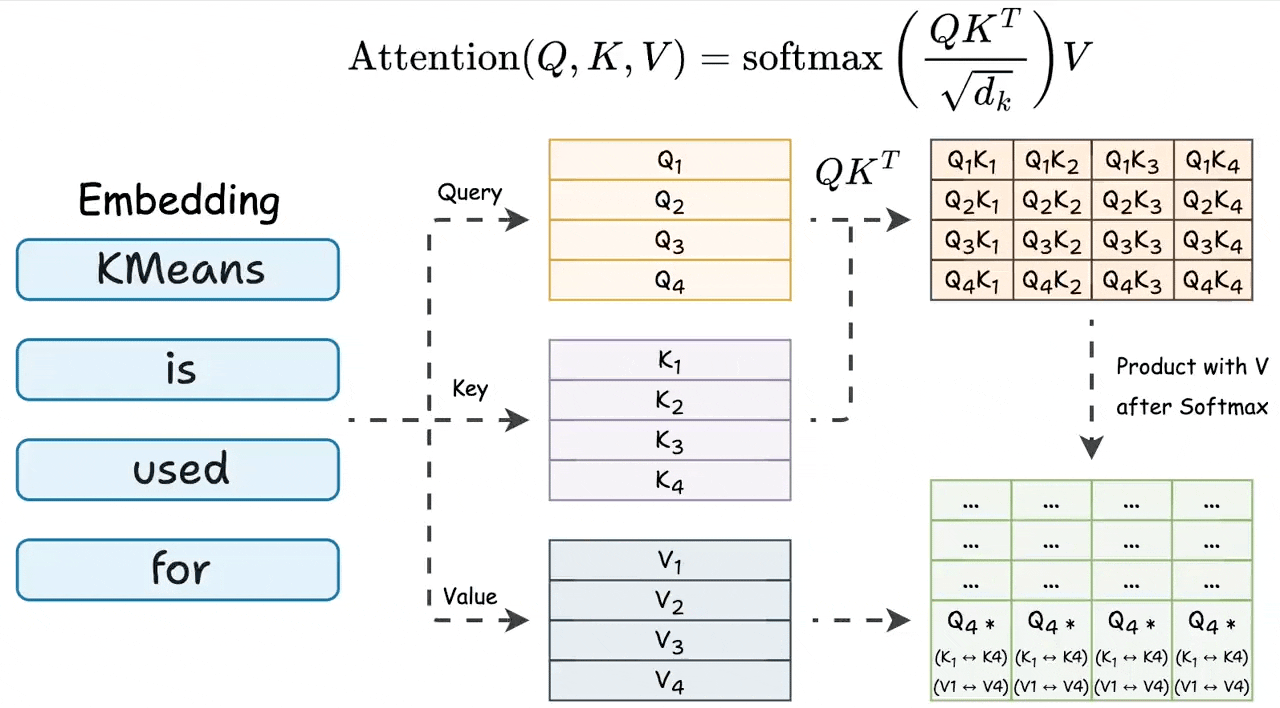
The above insight suggests that to generate a new token, every attention operation in the network only needs:
Query vector of the last token.
All key & value vectors.

But there's one more key insight here.
As we generate new tokens, the KV vectors used for ALL previous tokens do not change.
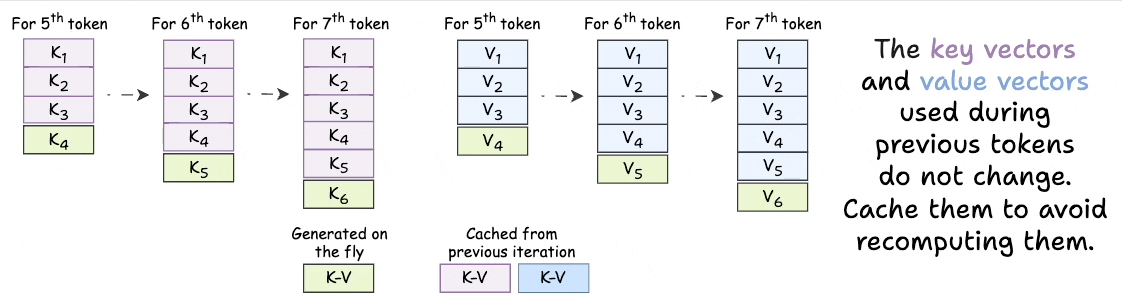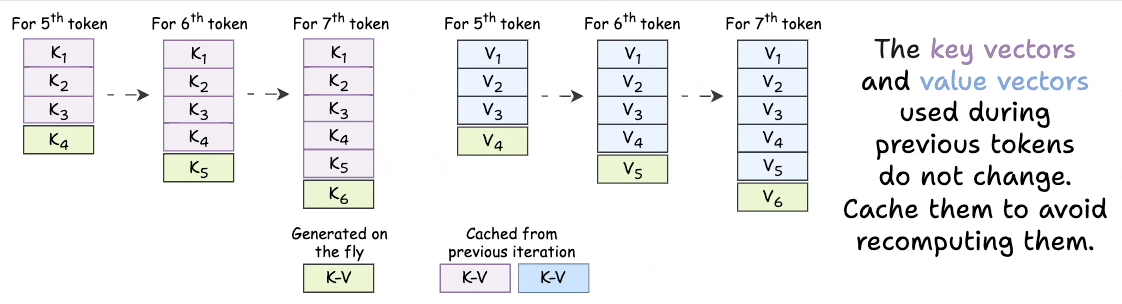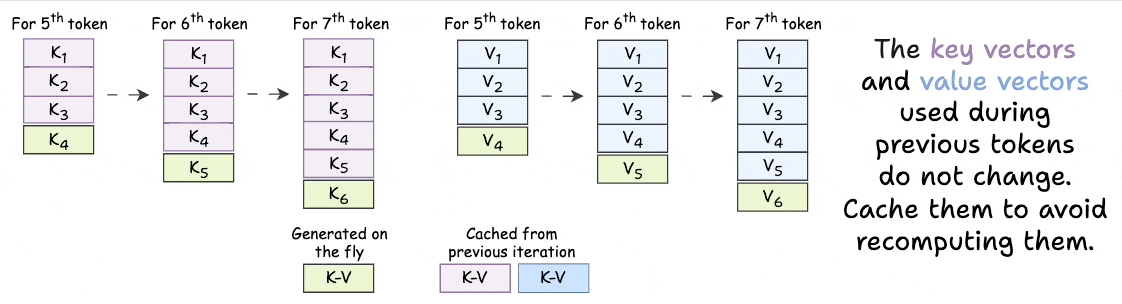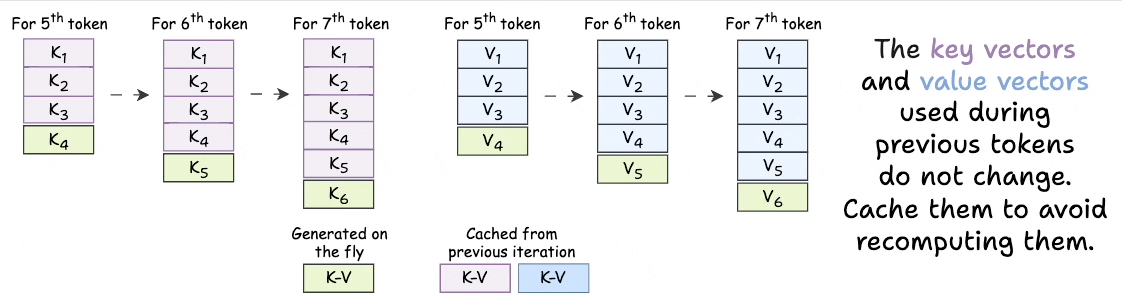
Thus, we just need to generate a KV vector for the token generated one step before.
The rest of the KV vectors can be retrieved from a cache to save compute and time.
This is called KV caching!
To reiterate, instead of redundantly computing KV vectors of all context tokens, cache them.
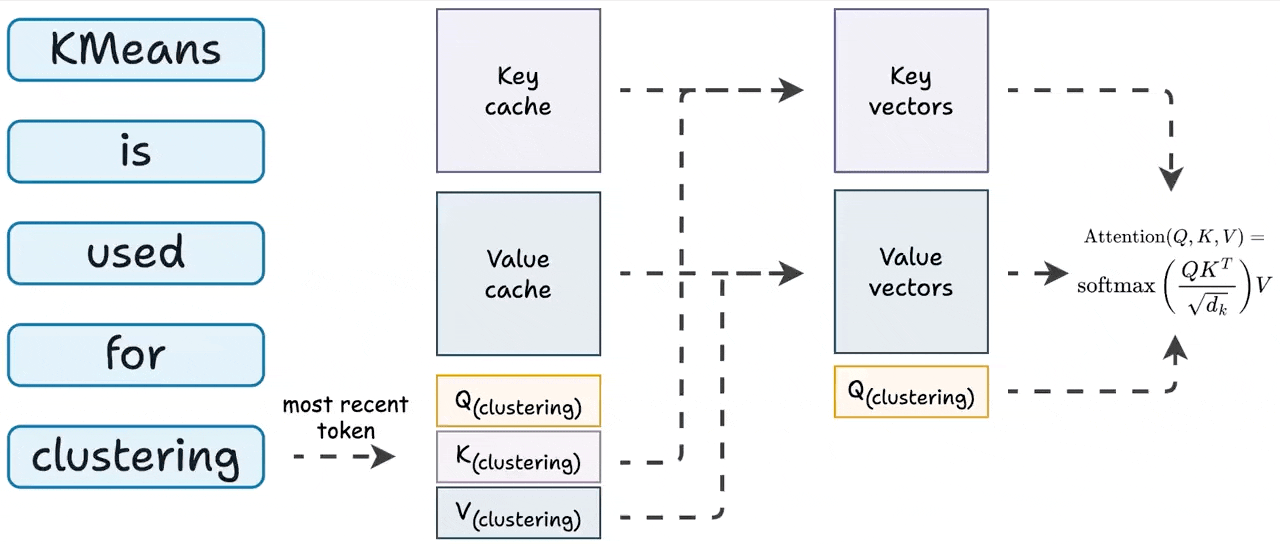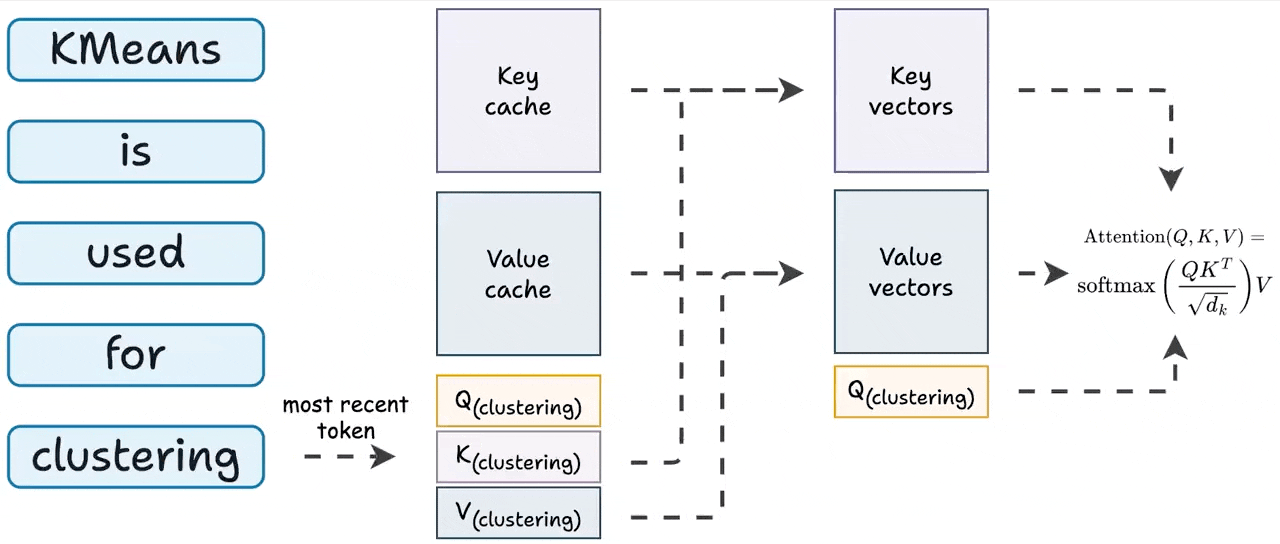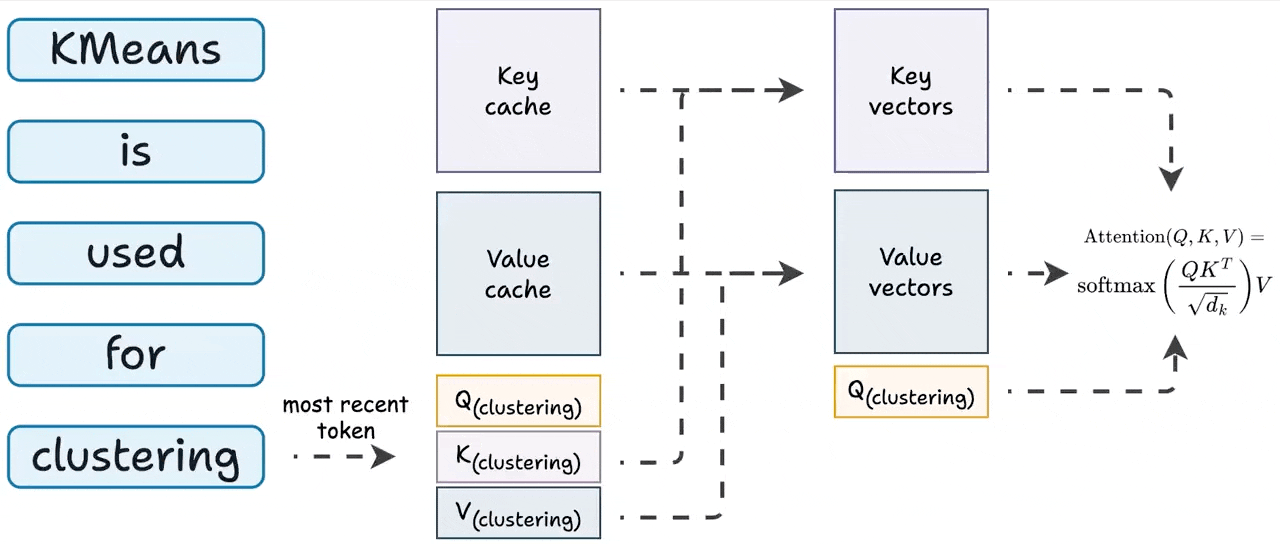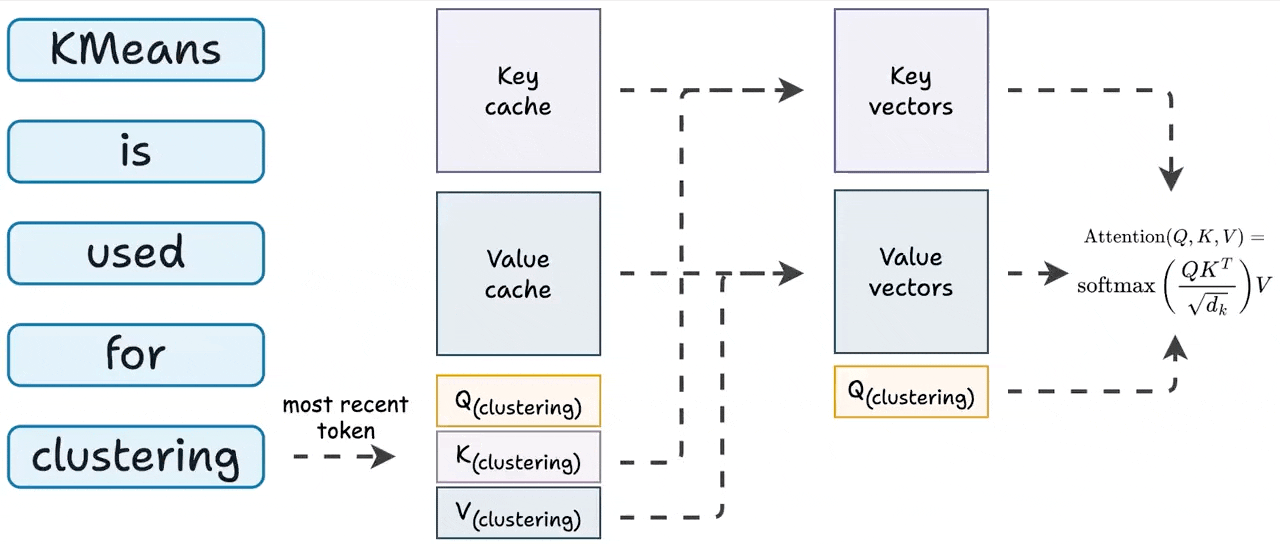
To generate a token:
Generate QKV vector for the token generated one step before.
Get all other KV vectors from the cache.
Compute attention.
Store the newly generated KV values in the cache.
As you can tell, this saves time during inference.
In fact, this is why ChatGPT takes some time to generate the first token than the subsequent tokens. During that little pause, the KV cache of the prompt is computed.
That said, KV cache also takes a lot of memory.
Consider Llama3-70B, which has:
total layers = 80
hidden size = 8k
max output size = 4k
Here:
Every token takes up ~2.5 MB in the KV cache.
4k tokens will take up 10.5 GB.
More users → more memory.
I'll cover KV optimization soon.
Over to you: How can we optimize the memory consumption?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
