

The possibilities with MCPs are endless.
Today, let us show you how we used MCP to power an RAG application over complex documents.
To give you more perspective, here’s our document:

Here’s our tech Stack:
Cursor IDE as the MCP client.
EyelevelAI's GroundX to build an MCP server that can process complex docs.
Here's how it works:
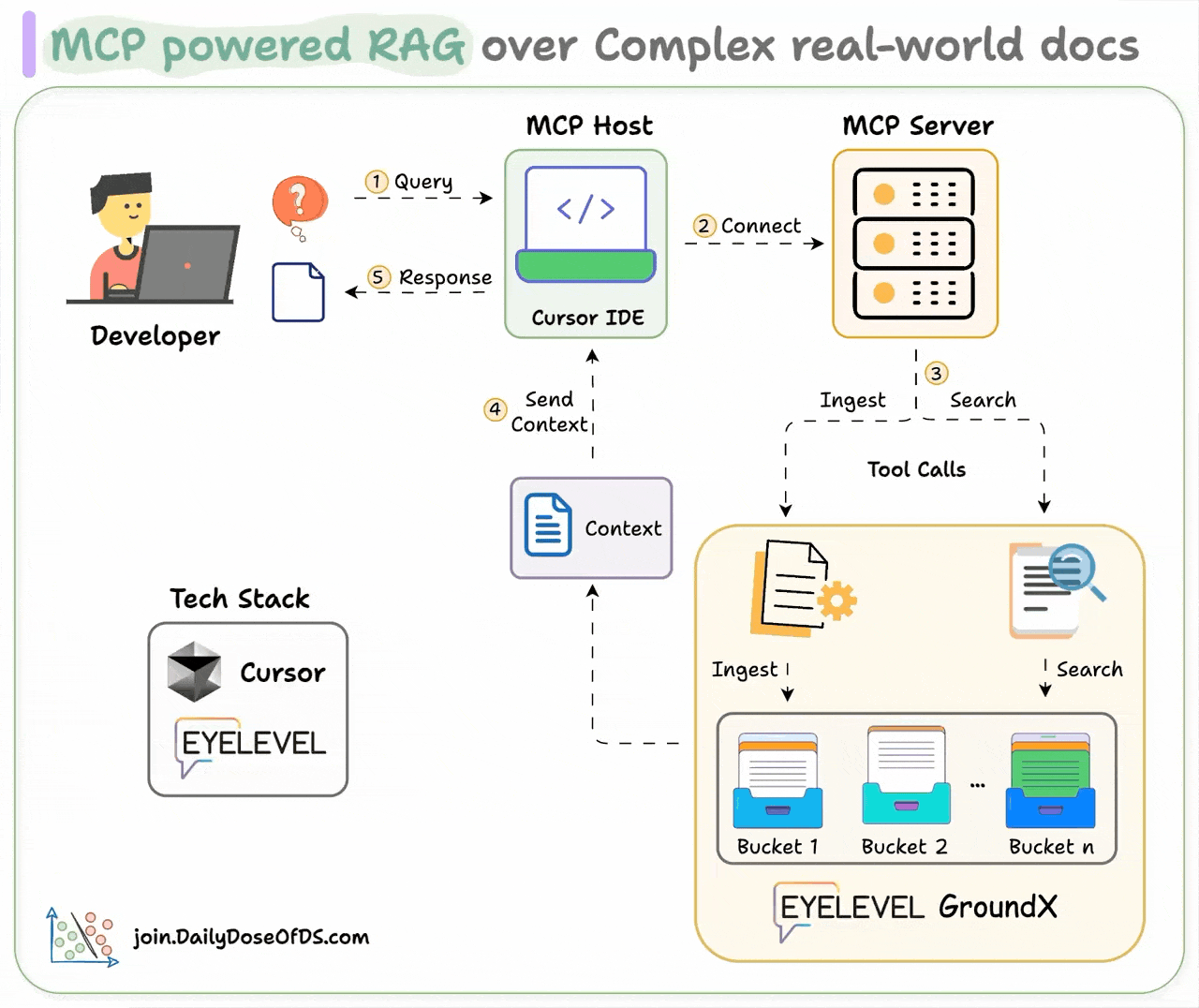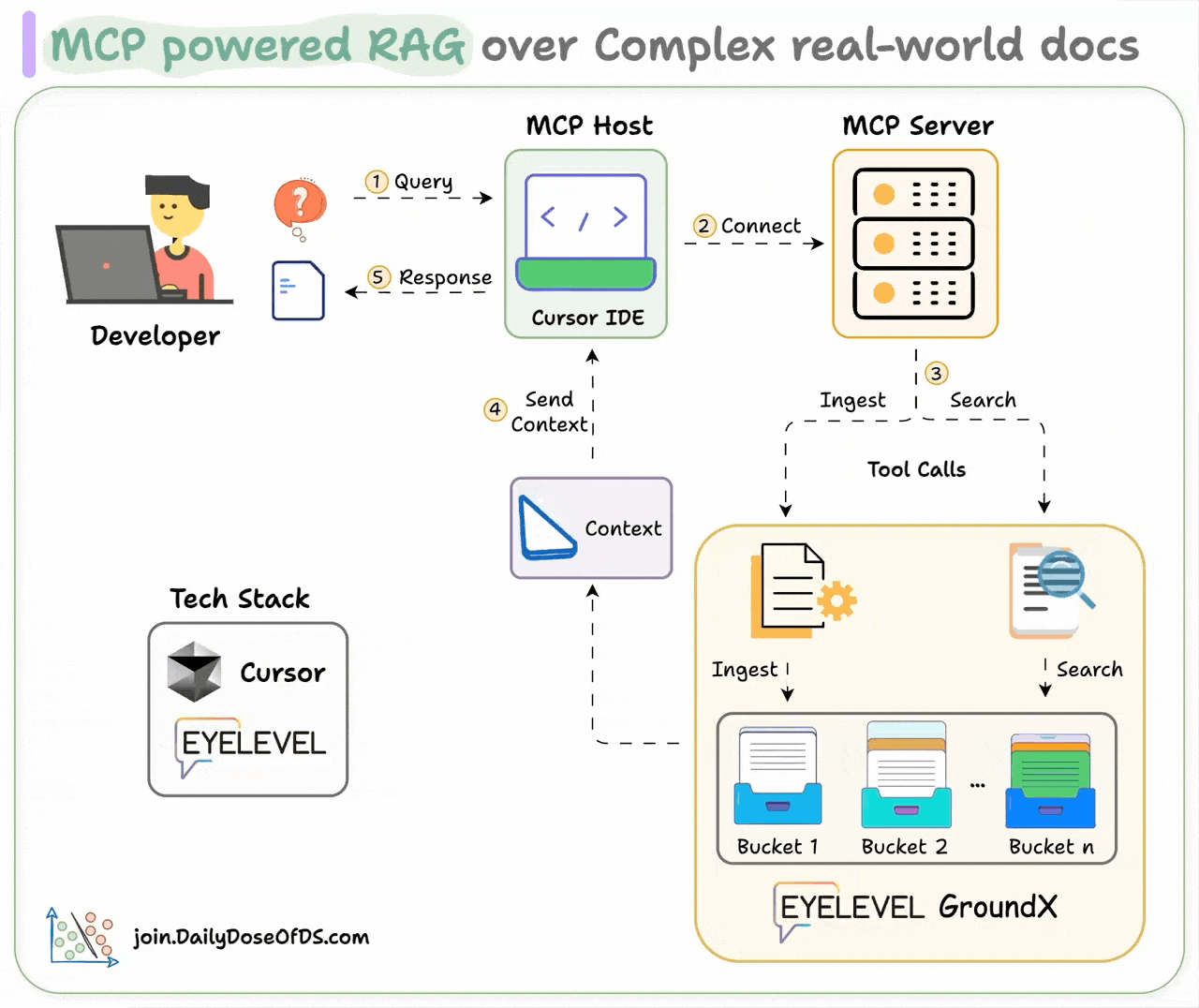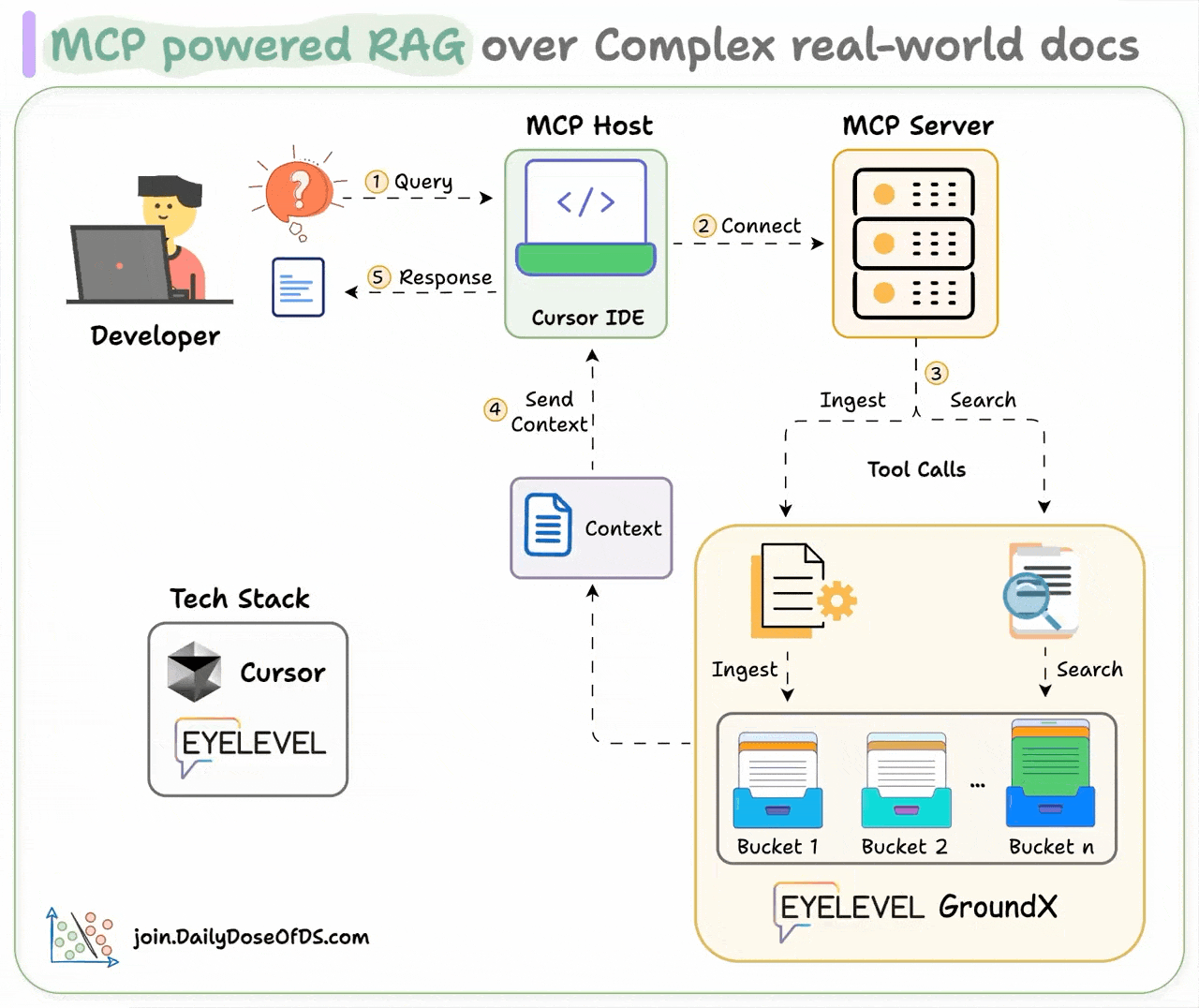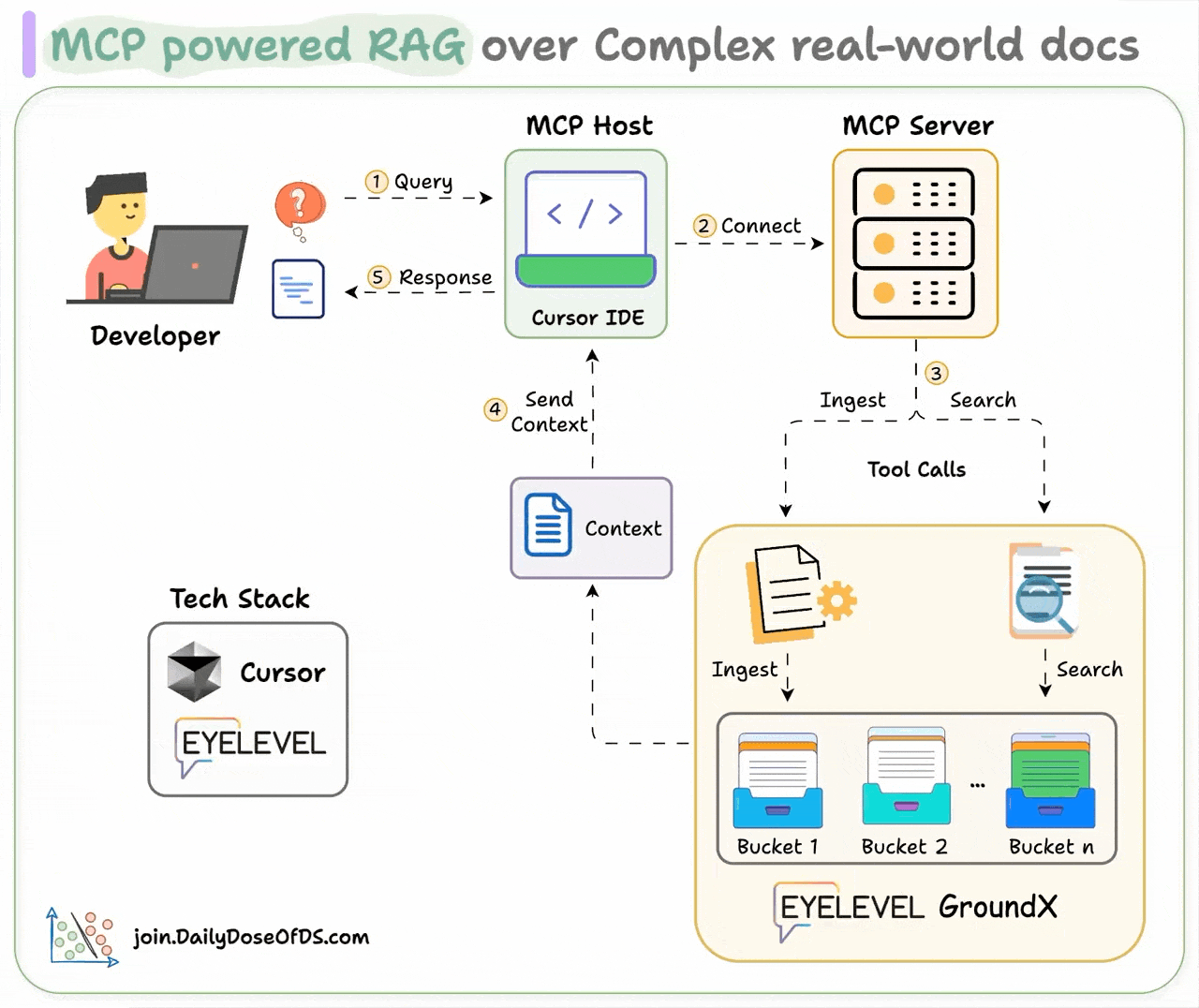
User interacts with the MCP client (Cursor IDE)
Client connects to the MCP server and selects a tool.
Tools leverage GroundX to do an advanced search over docs.
Search results are used by the client to generate responses.
If you prefer to watch, we have added a video at the top.
Implementation
Now, let's dive into the code! The GitHub repo with the code is linked later in the issue.
Set up server
First, we set up a local MCP server using FastMCP and provide a name.

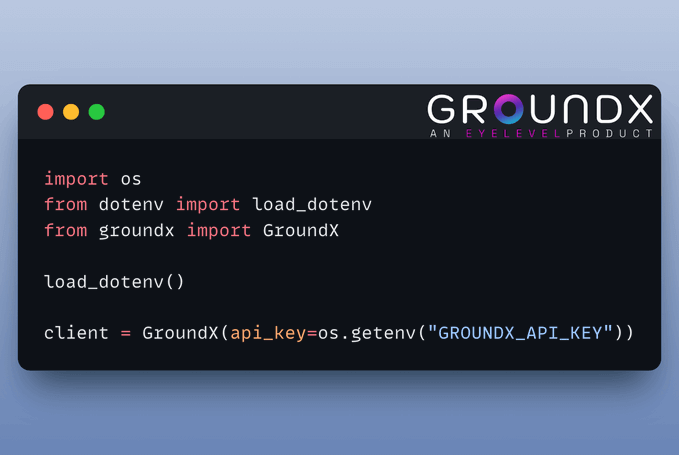
Create GroundX Client
GroundX offers capabilities document search and retrieval capabilities for complex real-world documents. You need to get an API key here and store it in a .env file.
Once done, here's how to set up a client:
Create Ingestion tool
This tool is used to ingest new documents into the knowledge base.
The user just needs to provide a path to the document to be ingested:

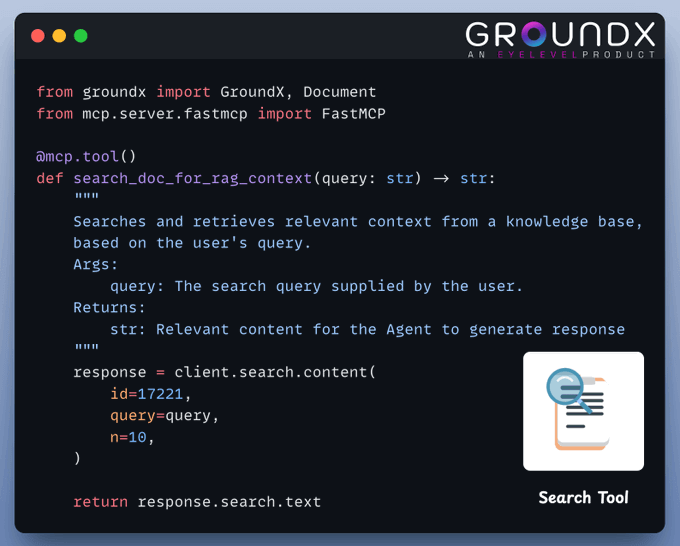
Create Search tool
This tool leverages GroundX’s advanced capabilities to do search and retrieval from complex real-world documents.
Here's how to implement it:
Start the server
Starts an MCP server using standard input/output (stdio) as the transport mechanism:

Connect to Cursor
Inside your Cursor IDE, follow this:
Cursor → Settings → Cursor Settings → MCP
Then add and start your server like this:
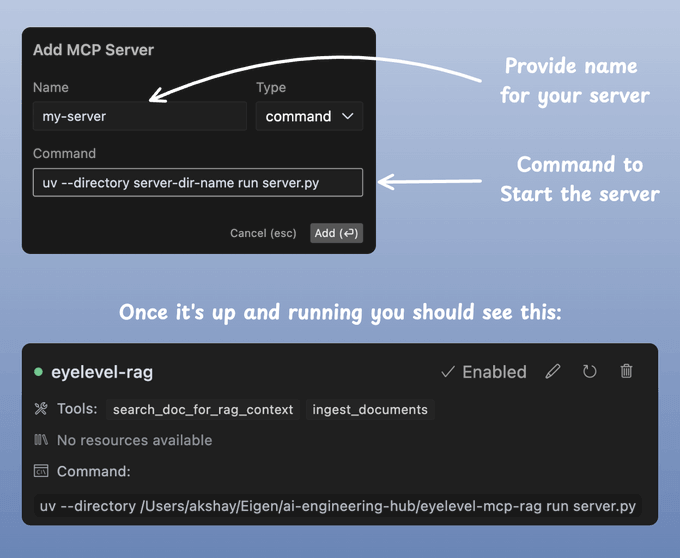
Done!
Now, you can interact with these documents directly through your Cursor IDE.
The video below gives a walk-through of what it looks like:
You can test EyeLevel on your own complex docs here →
We use EyeLevel on all complex use cases because they have built powerful enterprise-grade parsing systems that can intuitively chunk relevant content and understand what’s inside each chunk, whether it's text, images, or diagrams, as shown below:

As depicted above, the system takes an unstructured (text, tables, images, flow charts) input and parses it into a JSON format that LLMs can easily process to build RAGs over.
You can try EyeLevel to build real-world robust RAG systems below:
Also, find the code for this demo in this GitHub repo →
Thanks to EyeLevel for showing us their powerful RAG solution and working with us on today’s issue.
Thanks for reading!
