

Improve any RAG/Agentic app in a few lines of code!
Cleanlab Codex, developed by researchers from MIT, automatically detects incorrect AI responses in real-time with state-of-the-art precision.
It requires no data/modeling work nor configuration, and it works with any AI Agent you're building.
This snippet below demonstrates the usage in a RAG setup:
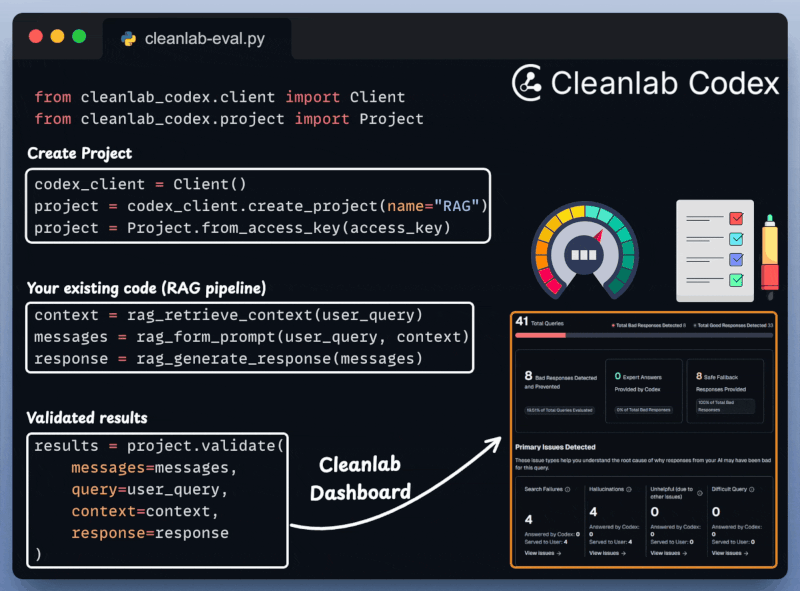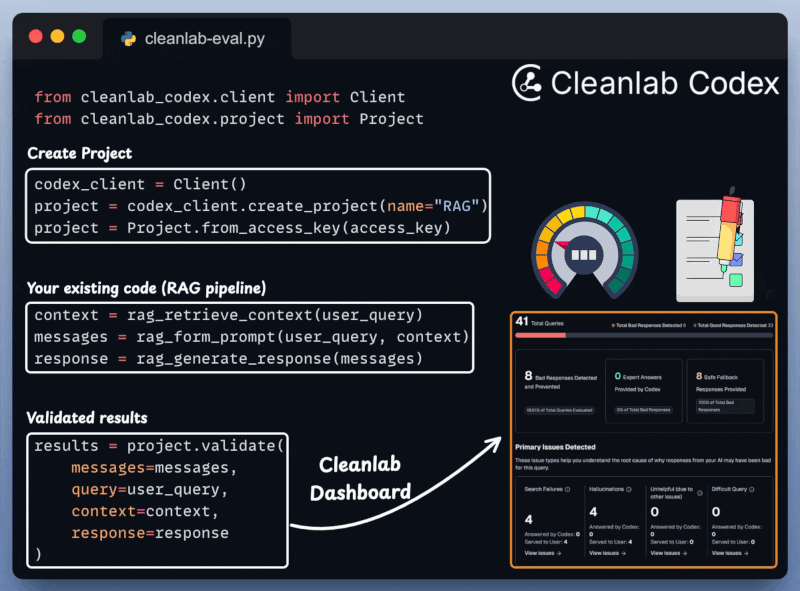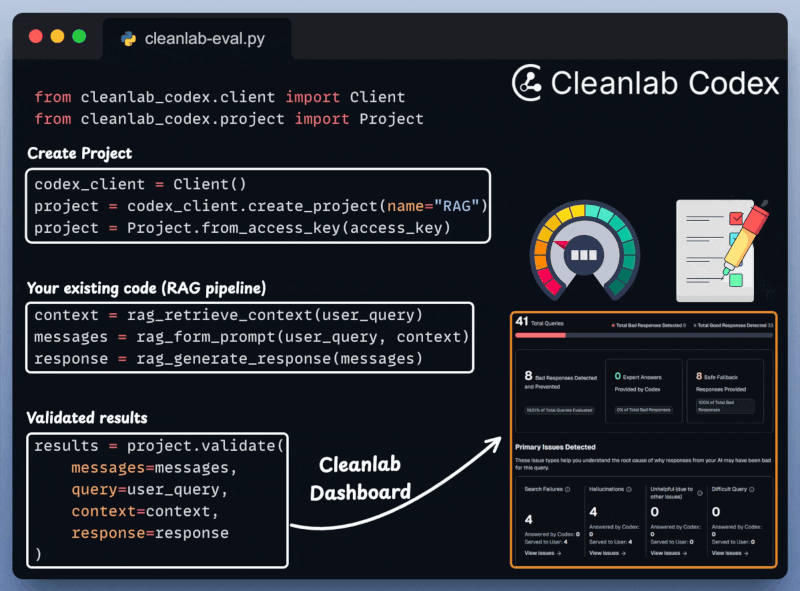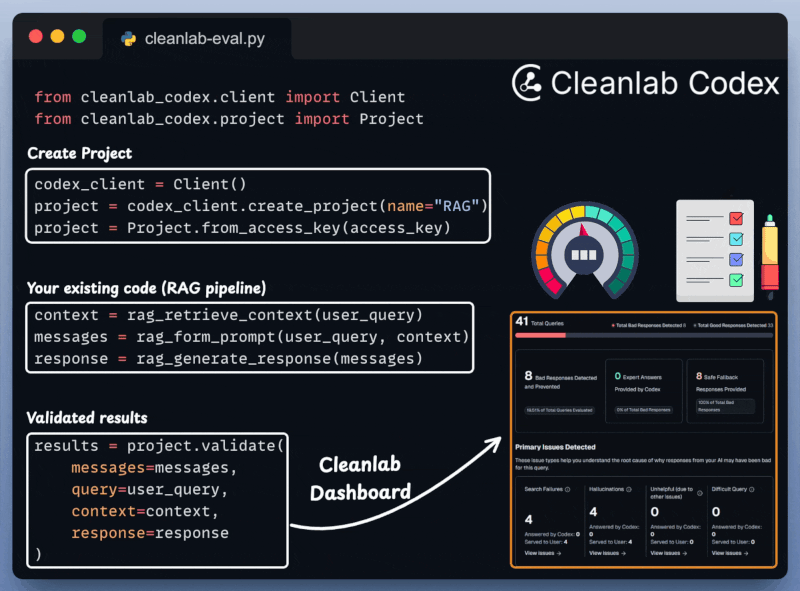
Define your project.
Get your input prompt, context, and AI’s response.
Validate the pipeline and get a visual summary report.
This is incredibly important for RAG/Agentic workflows that are quite susceptible to inaccuracies and hallucinations.
It frees your engineering team to focus on the core AI (data connectors, LLM orchestration, retrieval/tools) while providing an independent trust/safety layer and human-in-the-loop interfaces.
Build a Multimodal Agentic RAG
Tech giants use Multimodal RAG every day in production!
Spotify uses it to answer music queries
YouTube uses it to turn prompts into tracks
Amazon Music uses it to create a playlist from a prompt
Today, let's learn how to build a Multimodal Agentic RAG that can query documents and audio files using the user’s speech.
Tech stack:
AssemblyAI for transcription.
Milvus as the vector DB.
Beam for deployment (open-source).
CrewAI Flows for orchestration.
Here's the workflow:
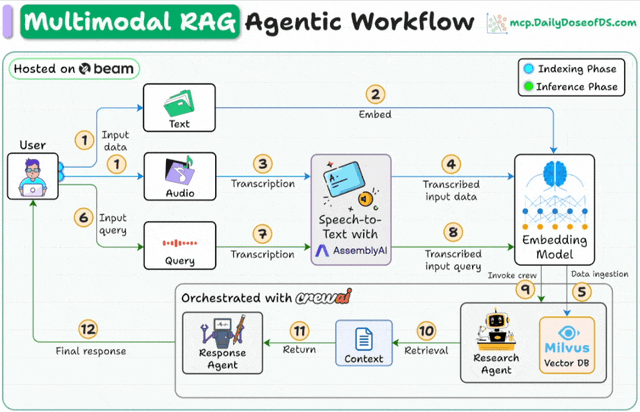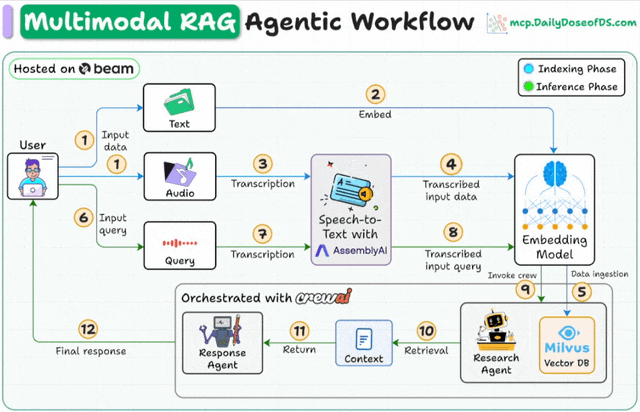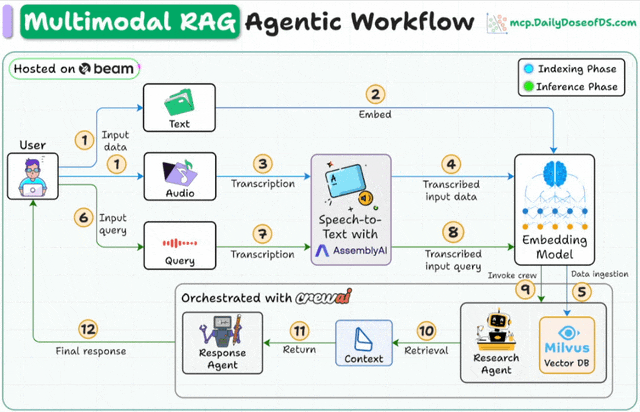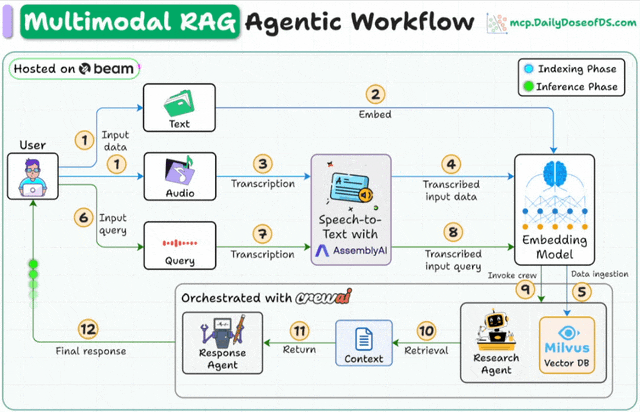
User inputs data (audio + docs).
AssemblyAI transcribes the audio files.
Transcribed text & docs are embedded in the Milvus vector DB.
Research Agent retrieves info based on the user’s query.
Response Agent uses it to craft a response.
Let's build it!
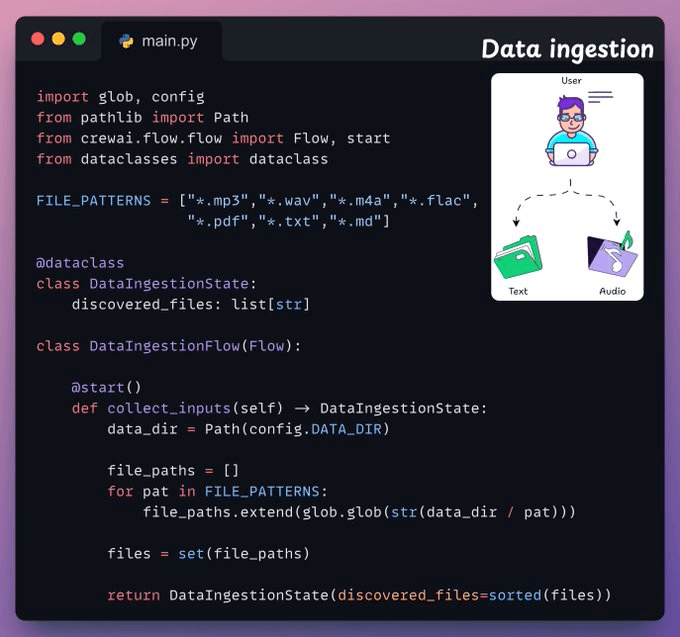
Data Ingestion
To begin, the user provides the text and audio input data in the data directory.
CrewAI Flow implements the logic to discover the files and get them ready for further processing.
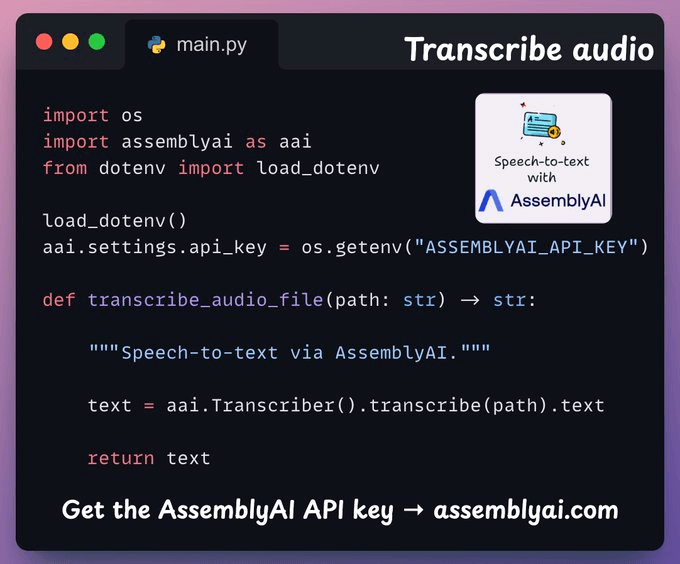
Transcribe audio
Next, we transcribe the user's audio input using AssemblyAI's Speech-to-text platform.
AssemblyAI is not open source, but it gives ample free credits to use their SOTA transcription models, which are more than sufficient for this demo.
You can get the AssemblyAI API key with 100+ hrs of free transcription here →
Embed input data
Moving on, the transcribed input data from the above step and the input text data are embedded and stored in the Milvus vector DB.

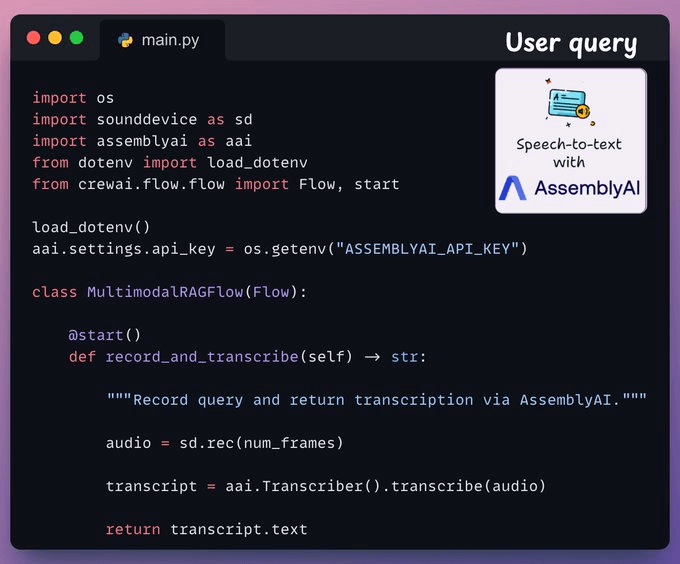
User query
Ingestion is over, and now we move to the inference phase!
Next, the user inputs a voice query, which is transcribed by AssemblyAI.
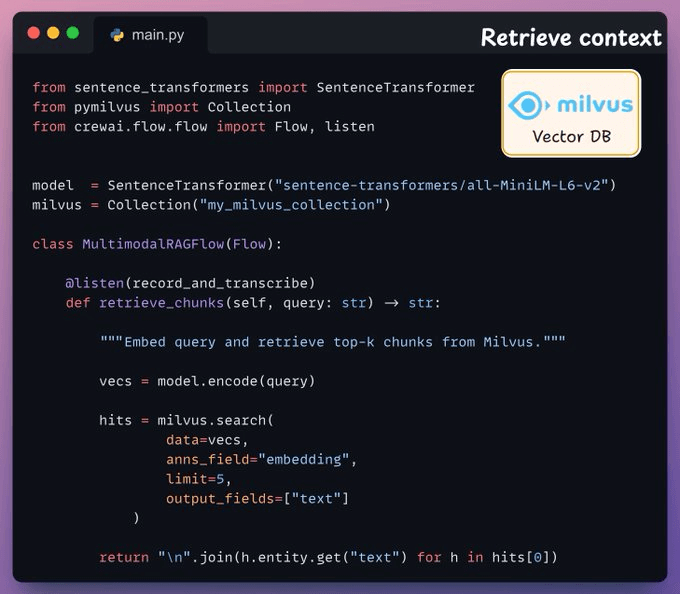
Retrieve context
Next, we generate an embedding for the query and pull the most relevant chunks from the Milvus vector DB.
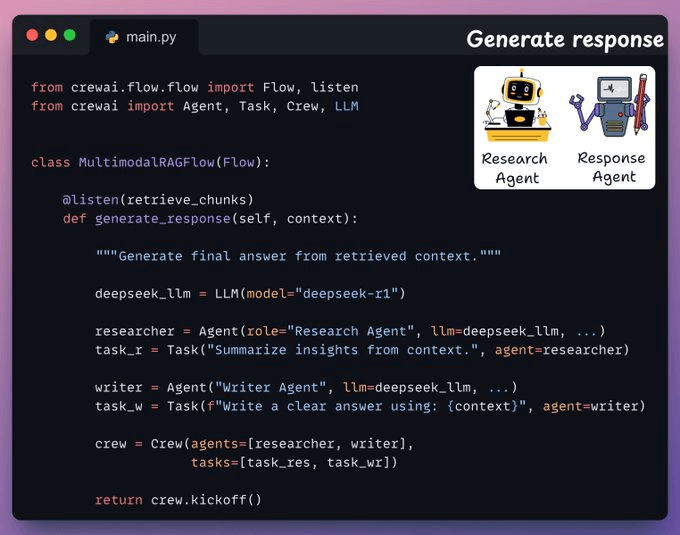
Generate an answer
Once we have the relevant context, our Crew is invoked to generate a clear and cited response for the user.
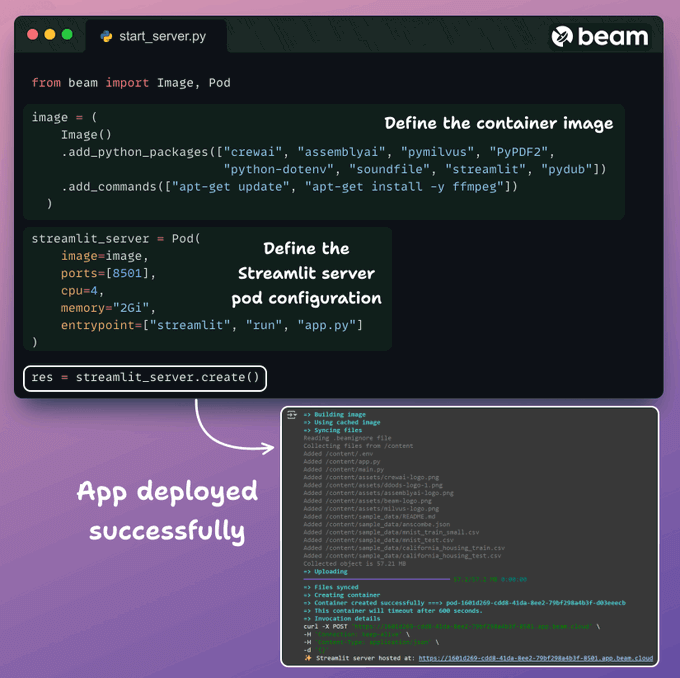
Finally, we wrap everything up into a clean Streamlit interface and deploy the app into a serverless container using Beam (open-source).
We import the necessary Python dependencies and specify the compute specifications for the container.
Once deployed, we get a 100% private deployment for the Multimodal RAG Agentic workflow that we just built.
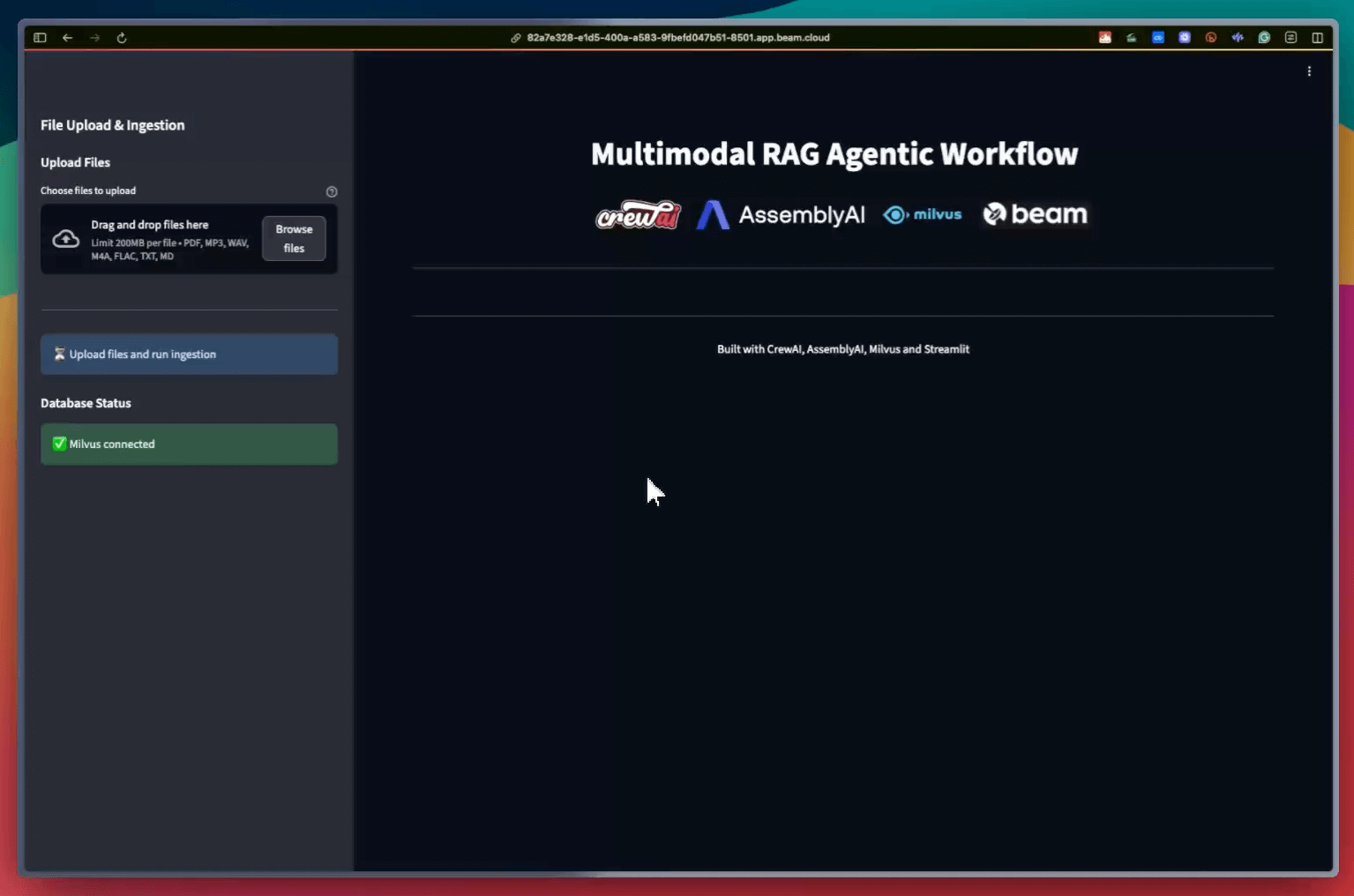
That is how you can build your own Multimodal Agentic RAG.
Some relevant links:
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
