

Why don't you automate that?
The browser is still the most universal interface.
Browserbase built AI to finally automate it, cleanly, securely, and at scale.

See how Browserbase powers the world's best tools with headless browsers.
Thanks to Browserbase for partnering today!
Compare OpenAI gpt-oss and Qwen 3 on Maths & Reasoning
Yesterday, OpenAI released open-weight models in the gpt-oss series designed for powerful reasoning, agentic tasks, and versatile developer use cases.
Let’s build a pipeline to compare it to Qwen 3
Tech stack:
LiteLLM for orchestration.
Opik to build the eval pipeline (open-source).
OpenRouterAI to access the models.
You'll also learn about G-Eval & building custom eval metrics.
Here's the workflow:
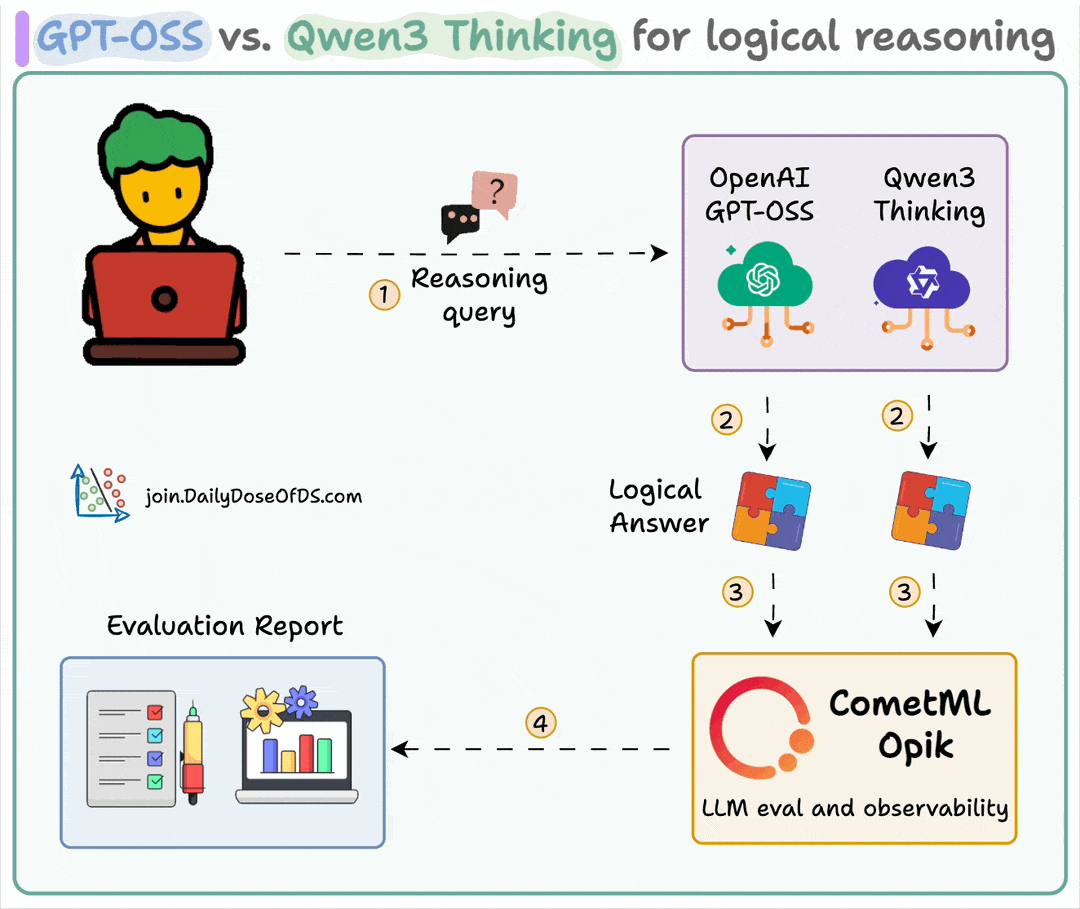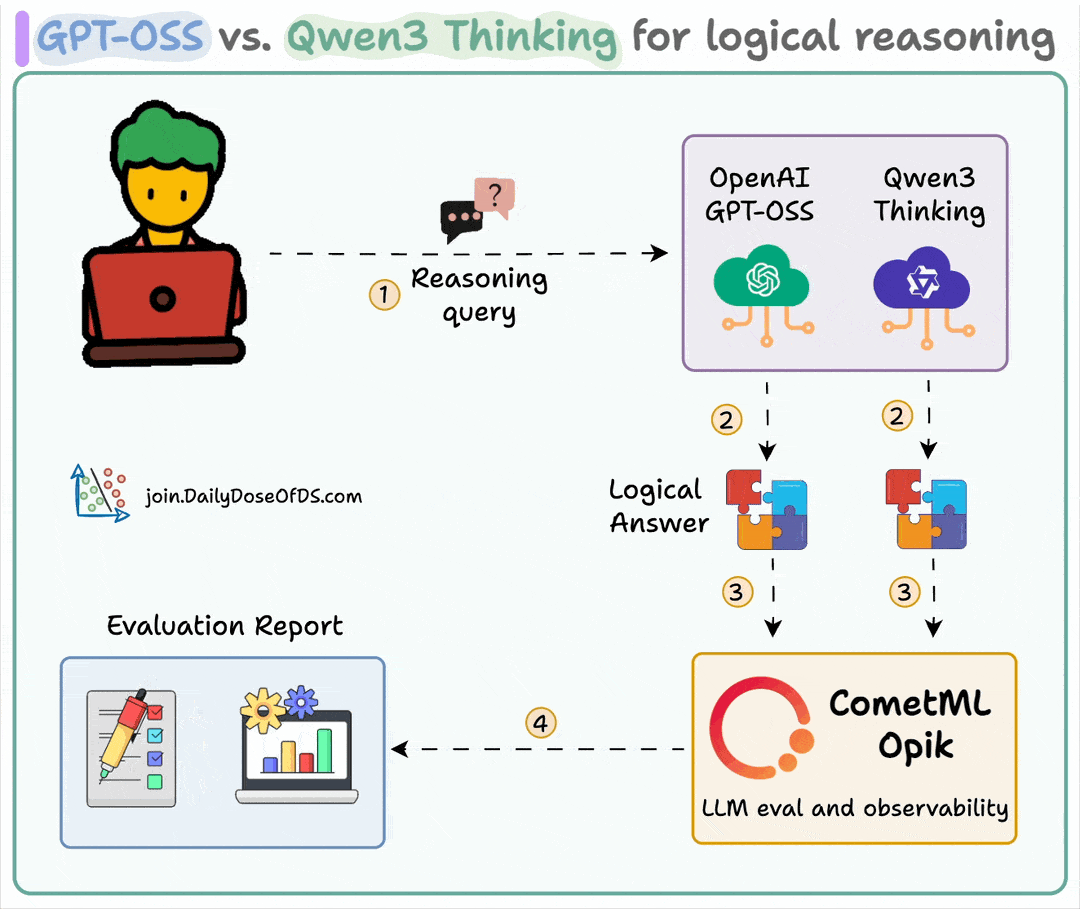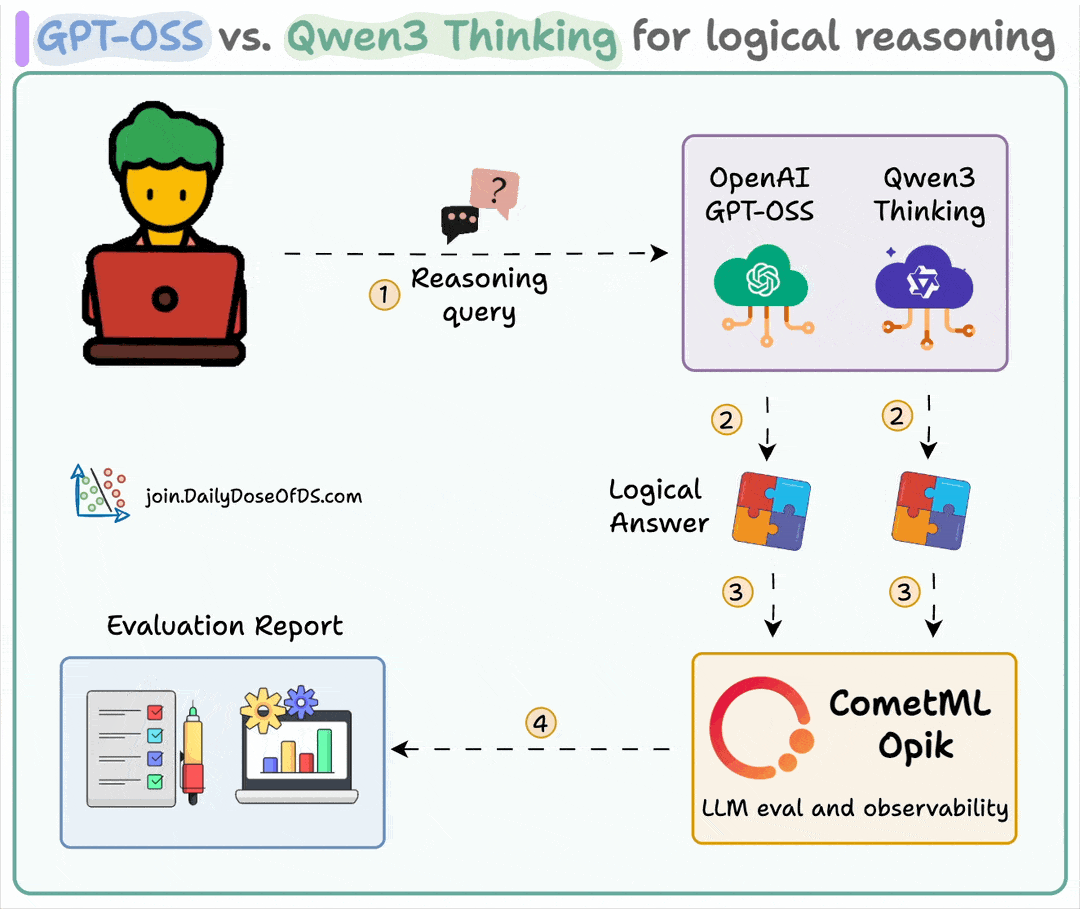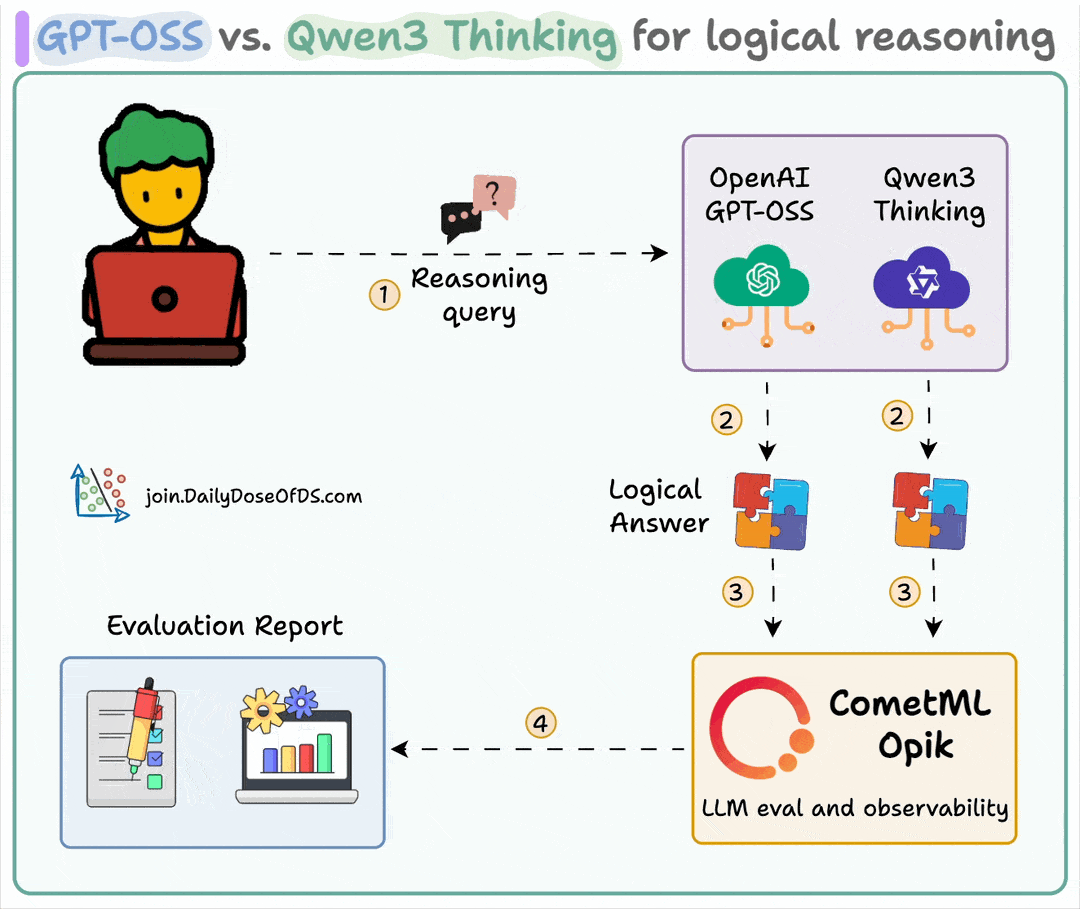
User submits query
Both models generate reasoning tokens along with the final response
Query, response, and reasoning logic are sent for evaluation
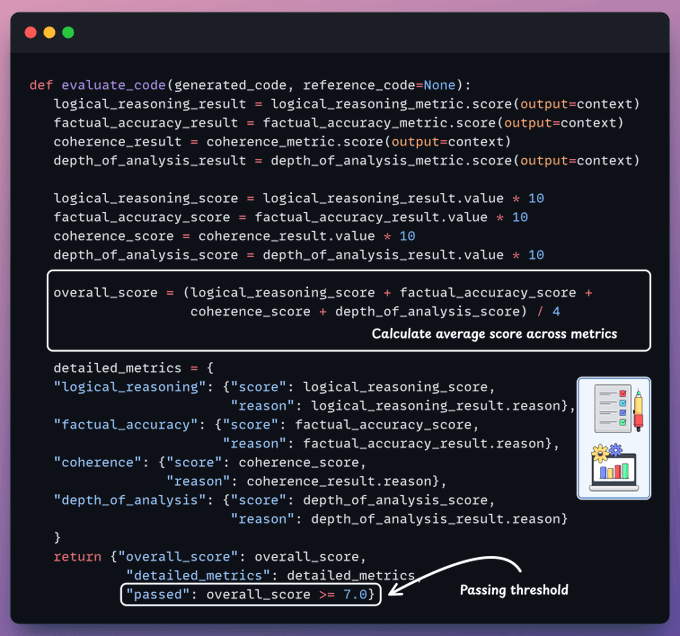
Detailed evaluation is conducted using Opik's G-Eval across four metrics.
Let’s implement this!
Load API keys
In this demo, we'll use OpenRouter to access gpt-oss and Qwen3 models.
OpenAI key is required for the judge LLM in G-Eval.
Store OpenRouter and OpenAI API keys in a .env file to load into the environment.

Logical Reasoning metric
We will now create evaluation metrics for our task using Opik's G-Eval.
This metric evaluates the coherence and validity of logical steps and conclusions.

Factual Accuracy metric
This metric assesses the accuracy of factual claims and information.

Coherence metric
This metric evaluates the clarity and organization of the response.

Depth of Analysis metric
This metric evaluates the depth and insightfulness of the reasoning.

Generate model response
Now we are all set to generate responses from both models.
We enter the query into the prompt box and stream responses from both models simultaneously.

Evaluate generated reasoning
Finally, we use GPT-4o as the judge LLM.
It evaluates both reasoning responses, generates the metrics mentioned above, and provides details for each metric.
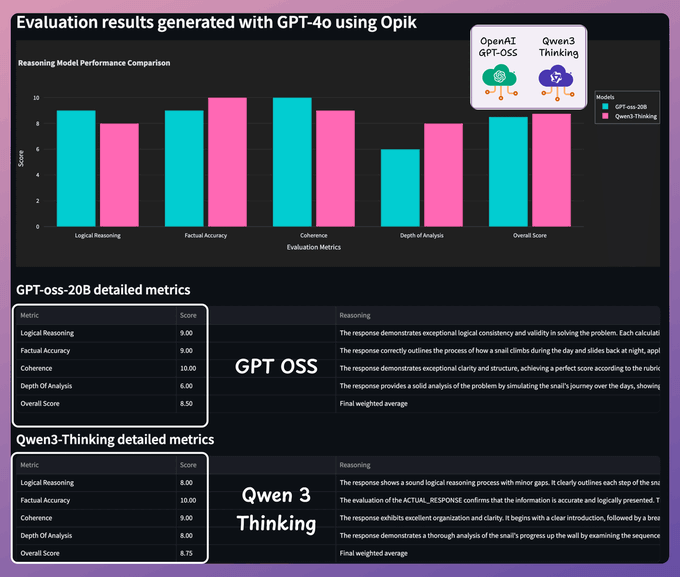
Time to test.. (1/2)
Query 1: A snail climbs up a 10-foot wall. Each day it climbs 3 feet, but each night it slides back 2 feet. On which day will it reach the top?
Here are the detailed results:
Time to test.. (2/2)
Query 2: A runaway trolley is heading toward 5 people. You can pull a lever to divert it to a side track, where it will kill 1 person instead. What should you do and why?
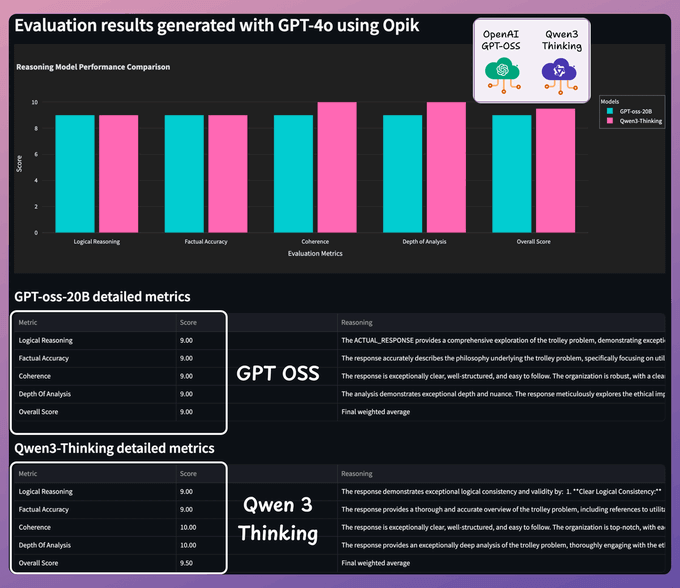
Both models are highly capable: Qwen 3 offers verbose and detailed reasoning, while GPT-oss is crisp and accurate.
Feel free to test it on more challenging queries.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
