

Websites have complex layouts.
Building RAG over them can be tedious if we use traditional text-based parsing.
We built a complex multimodal RAG that works over any complex website, and this newsletter details how we built it.
We used:
ColiVara—a unique document retrieval method that does not need chunking or text processing. It still feels like RAG but without OCR, text extraction, broken tables, or missing images.
Firecrawl for reliable scrapping.
DeepSeek Janus as the multimodal LLM.
Now let's jump into code (GitHub repo is provided later)!
Implementation
Here’s the workflow:
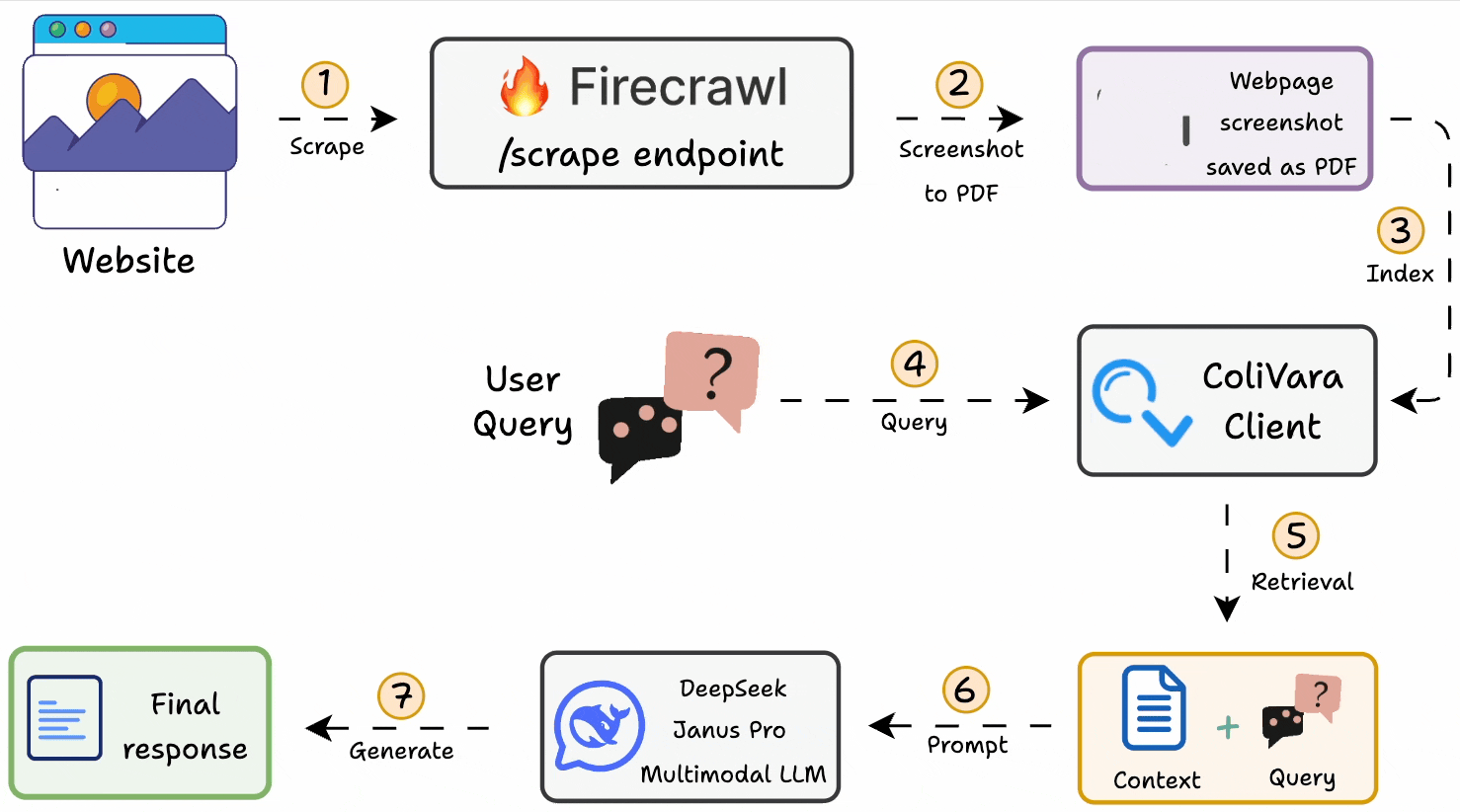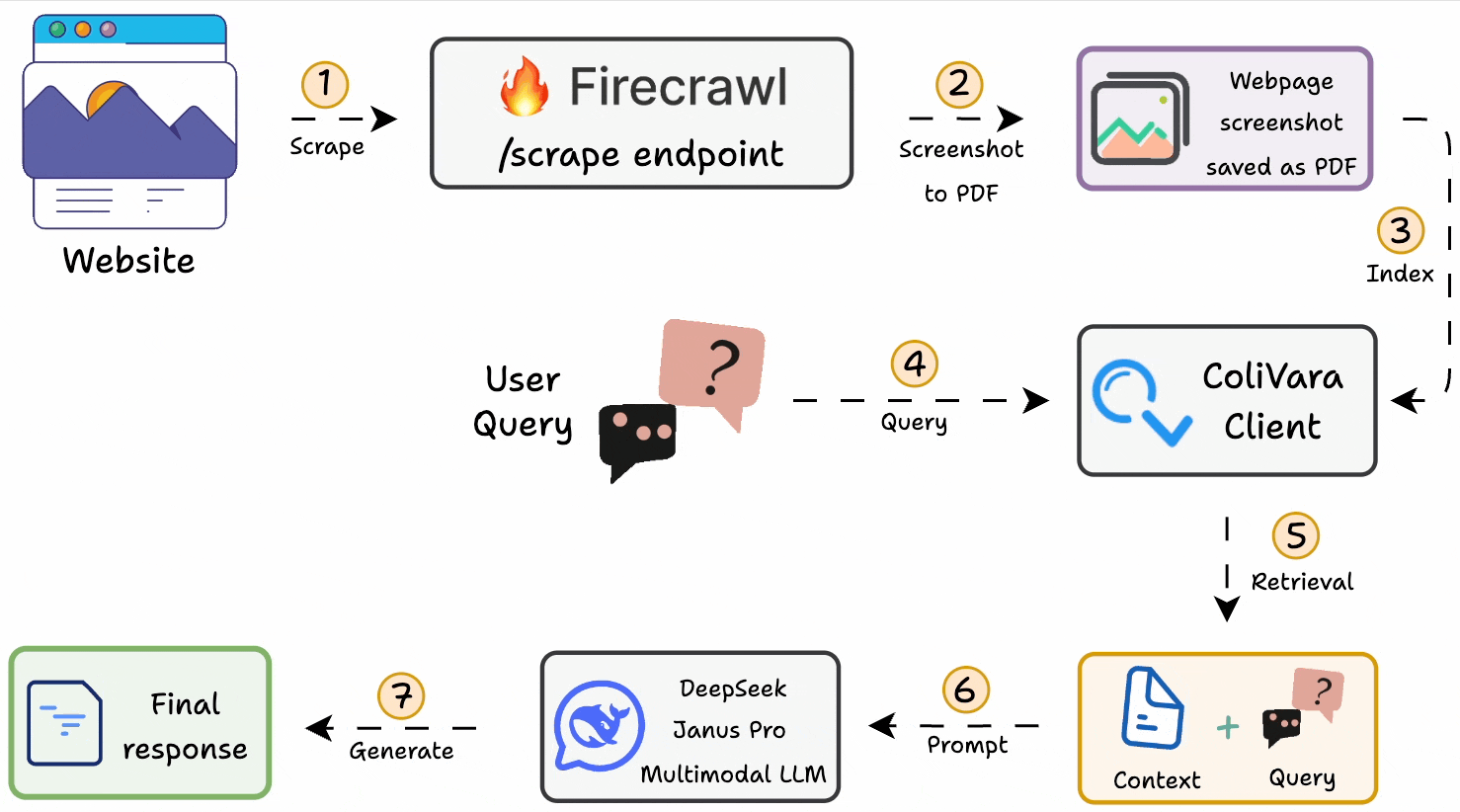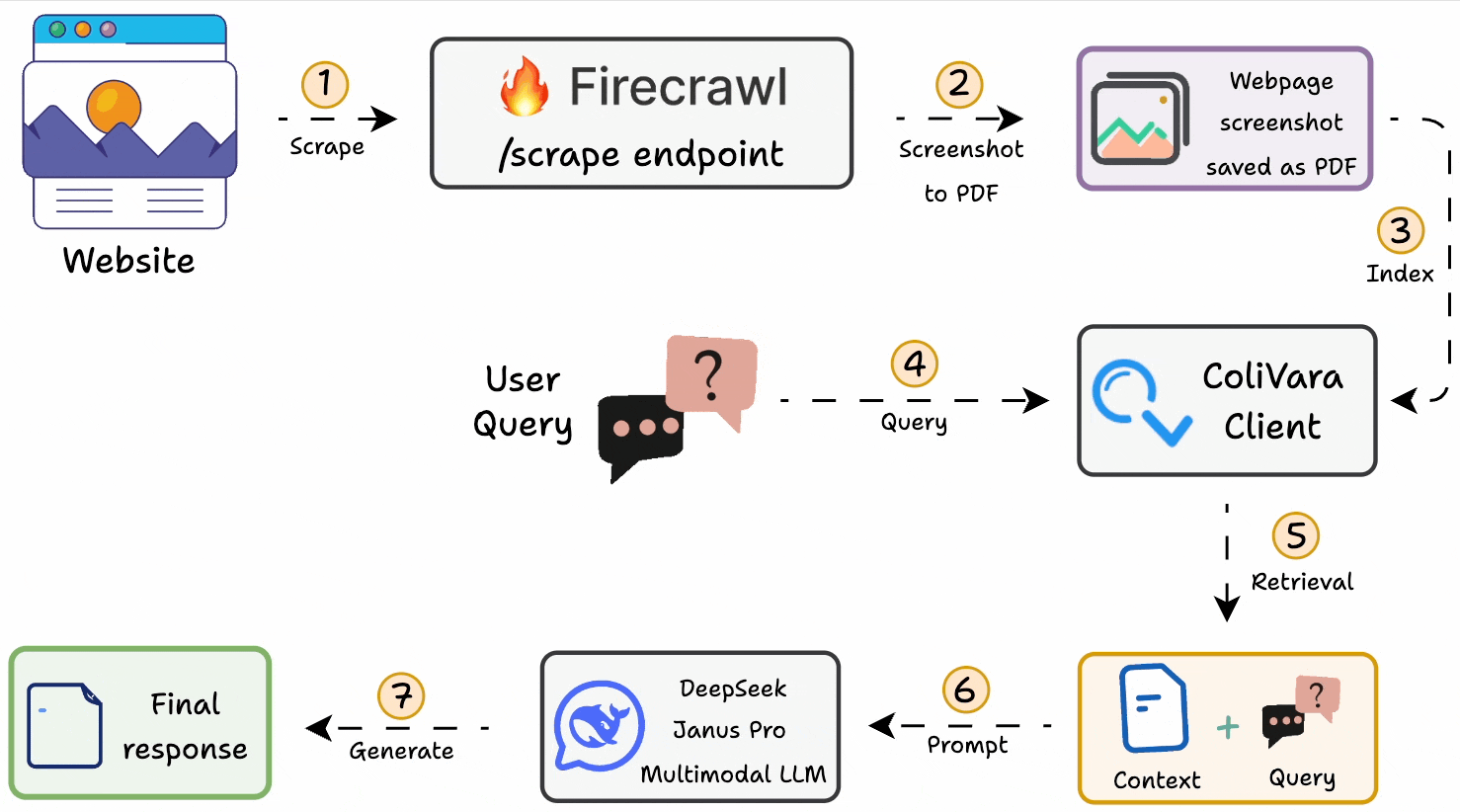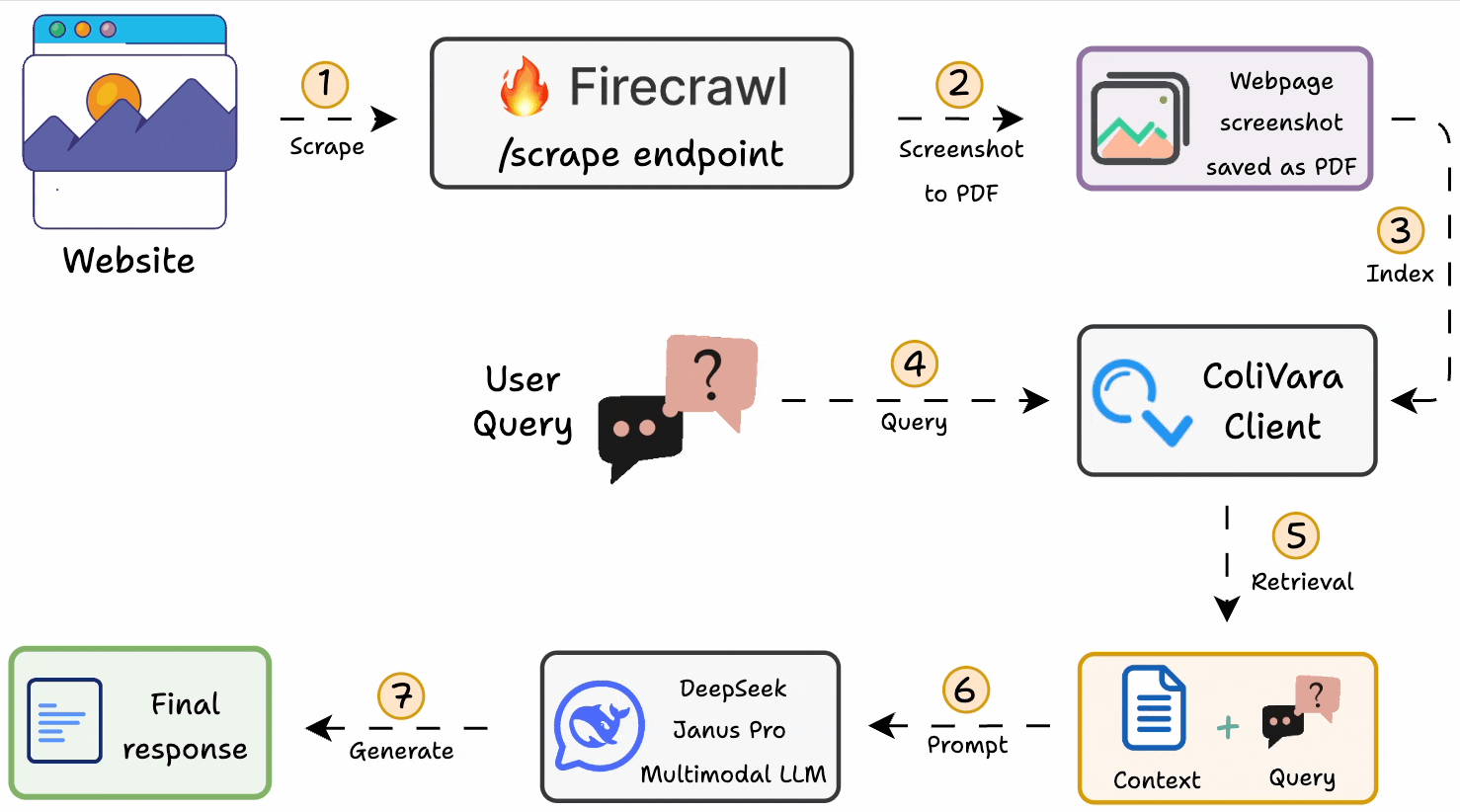
1-2) Generate a PDF of web page screenshots with Firecrawl.
3) Index it on ColiVara for SOTA retrieval.
4-5) Query the ColiVara client to retrieve context.
6-7) Use DeepSeek Janus Pro as the LLM to generate a response.
Data
I used this complex web page here.

It has several complex diagrams, text within visualizations, and tables—perfect for multimodal RAG.
Set up the API Keys
To scrape a website with Firecrawl and index it with ColiVara, create a `.env` file and specify the API keys:

Scrape with FireCrawl
Since ColiVara is a vision-based retrieval method, we first use Firecrawl to gather the whole web page as a screenshot.
This is implemented below:
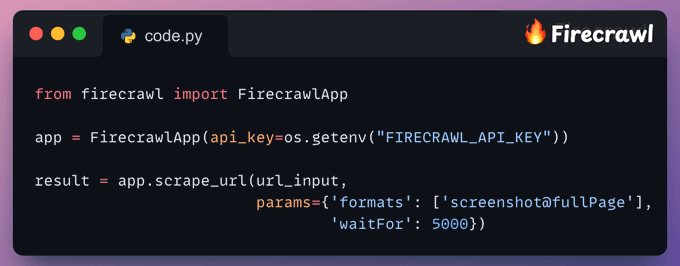
Index data to ColiVara
Next, we take the web page screenshot, convert it to a PDF, and index it with ColiVara. To do this:
First, create a ColiVara RAG client and a collection.
Next, upload the document to the collection.

No need to set up a vector database!
Set up DeepSeek Janus-Pro
Next, we set up our DeepSeek's latest Janus-Pro by downloading it from HuggingFace.

Query and generate
Now that we have indexed the document and set up the LLM, we send a retrieval request to ColiVara with the user query to generate a response.

Done!
We have implemented a 100% local Multimodal RAG powered by DeepSeek's latest Janus-Pro.
To make this accessible, we wrap the entire app in a Streamlit interface.
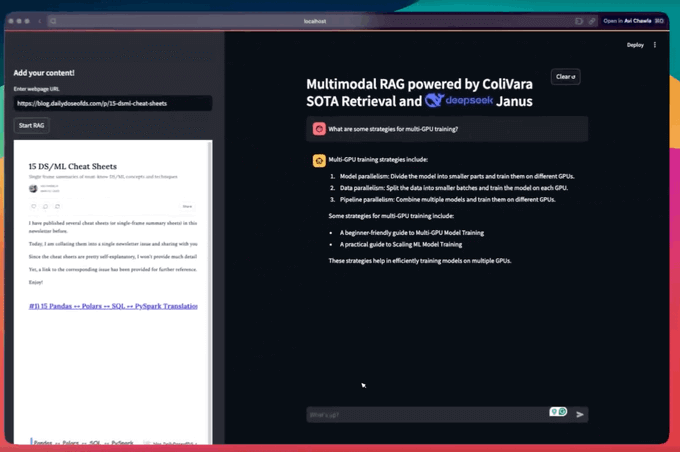
By providing a link to the website, you can chat with it—while using a SOTA retrieval and SOTA multimodal LLM.
Wasn’t that easy and straightforward?
About ColiVara
A RAG workflow typically involves 80% retrieval and 20% generation.
Good retrieval may still work with a weak LLM. But bad retrieval can NEVER work with the best of LLMs.
If your RAG isn't working, most likely, it's a retrieval issue.
This, in turn, means it's an issue related to how the data was chunked and embedded.
ColiVara is an advanced retrieval method that does not involve chunking.

It treats docs as images and uses vision models for embedding, just like humans do.
This provides far better accuracy than traditional RAG systems that rely on chunking without latency issues.
Supports 100+ file formats
Seamless local or cloud quickstart
APIs & SDKs for both Python/TypeScript
Late-interaction embeddings for extra accuracy
No vector DB management (pgVector under the hood)
The code for today's demo is available here: Multimodal RAG with ColiVara DeepSeek.
👉 Over to you: What other demos would you like to see with DeepSeek?
Thanks to ColiVara for giving us access to their SOTA retrieval mechanism and working with us on today’s issue.
Thanks for reading!
