

Pixeltable: Declarative Data Infrastructure for Multimodal AI Apps

Pixeltable is an open-source Python library for multimodal AI data.
Store videos, images, text & embeddings in one place.
Transform with computed columns
Index for similarity search
Add custom UDFs
Built by the Apache Parquet team.
Thanks to the Pixeltable team for partnering today!
Make RAG systems 32x memory efficient!
There’s a simple technique that’s commonly used in the industry that makes RAG ~32x memory efficient!
Perplexity uses it in its search index
Azure uses it in its search pipeline
HubSpot uses it in its AI assistant
To learn this, we’ll build a RAG system that queries 36M+ vectors in <30ms.
And the technique that will power it is called Binary Quantization.
Tech stack:
Llama Index for orchestration (open-source)
Milvus as the vector DB (open-source)
Beam Cloud for serverless deployment (open-source)
Kimi-K2 as the LLM hosted on Groq (hosted)
Here's the workflow:
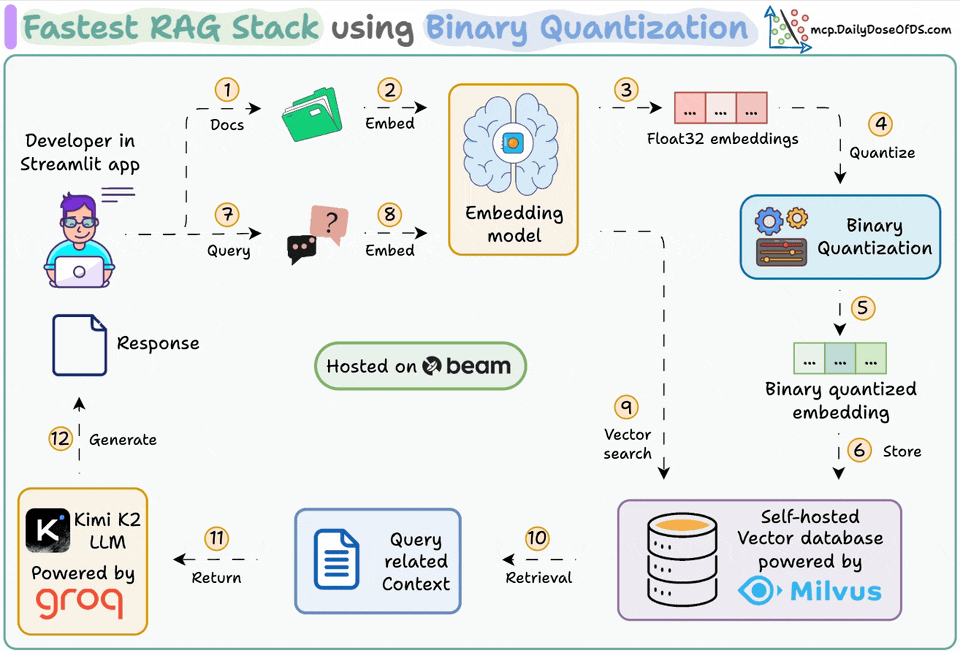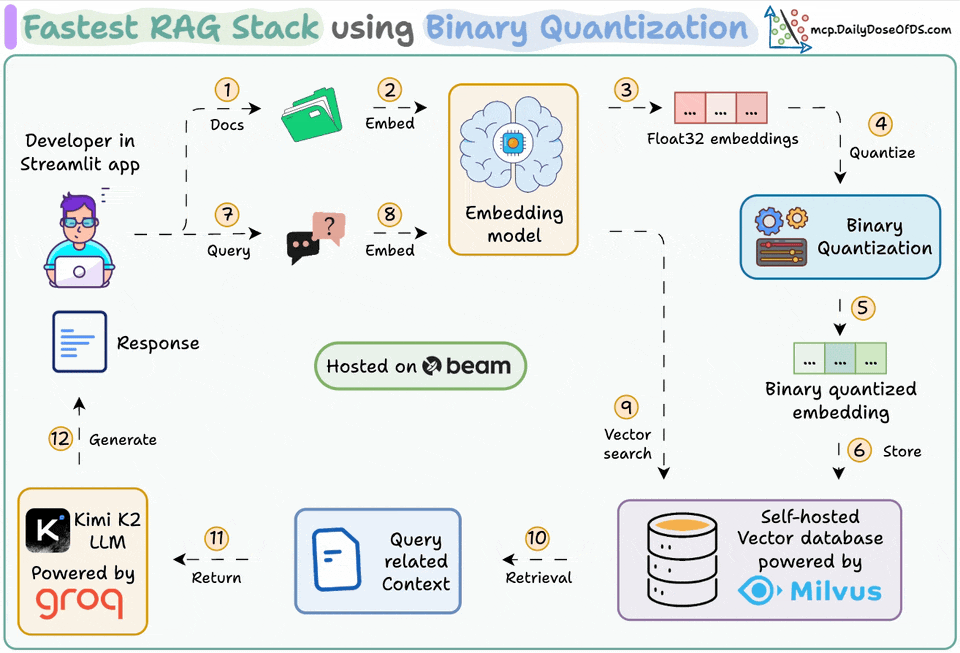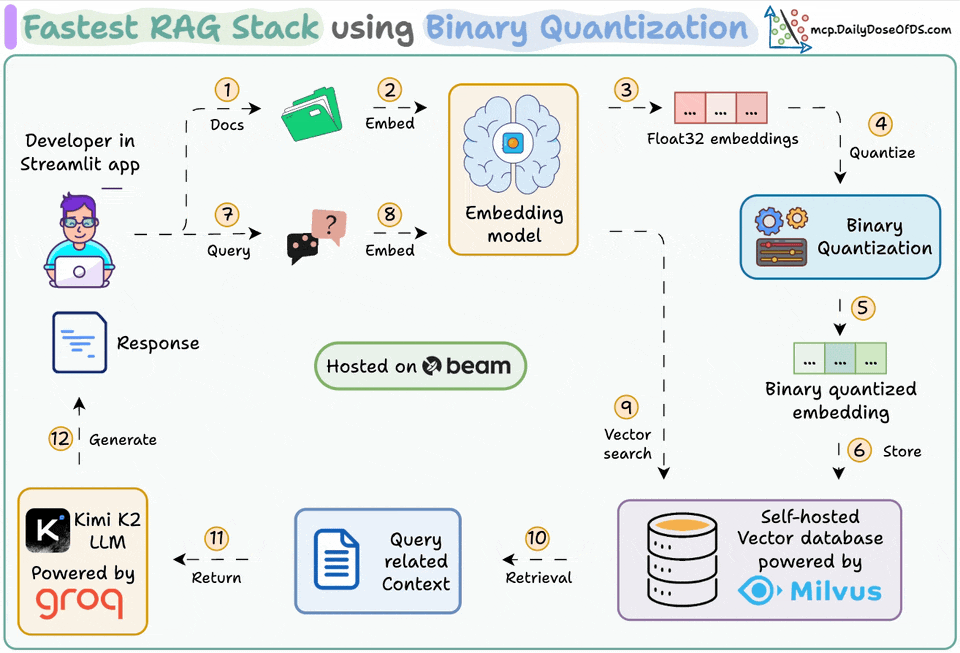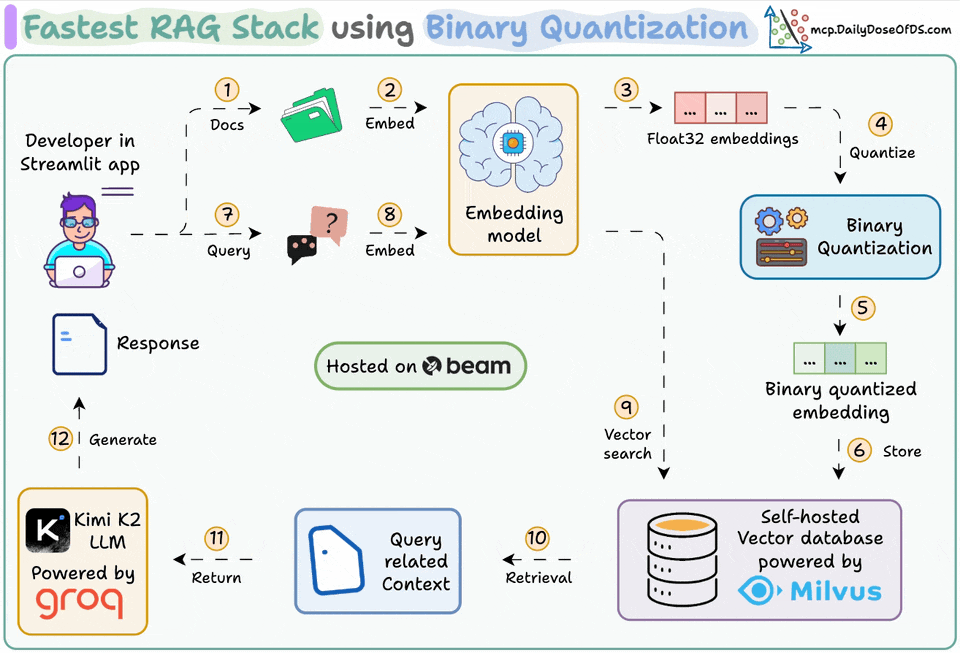
Ingest documents and generate binary embeddings.
Create a binary vector index and store embeddings in the vector DB.
Retrieve top-k similar documents to the user's query.
LLM generates a response based on additional context.
Let's build it!
Setup Groq
Before we begin, store your Groq API key in a .env file and load it into your environment to leverage the world's fastest AI inference.

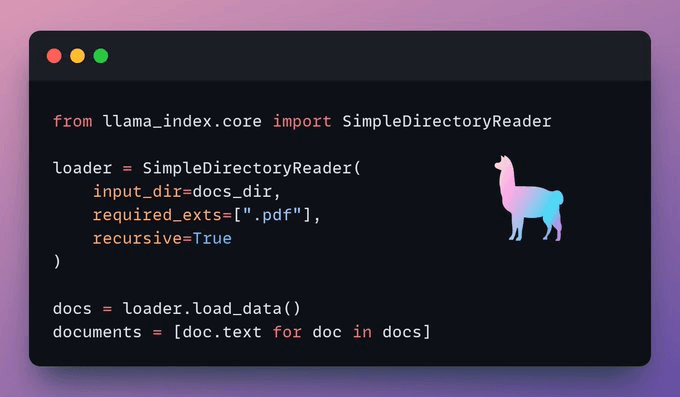
Load data
We ingest our documents using LlamaIndex's directory reader tool.
It can read various data formats including Markdown, PDFs, Word documents, PowerPoint decks, images, audio, and video.
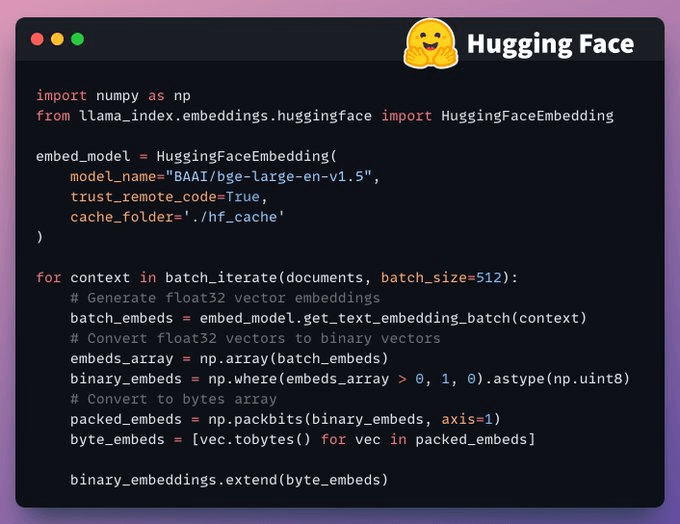
Generate Binary Embeddings
Next, we generate text embeddings (in float32) and convert them to binary vectors, resulting in a 32x reduction in memory and storage.
This is called binary quantization.
Vector indexing
After our binary quantization is done, we store and index the vectors in a Milvus vector database for efficient retrieval.
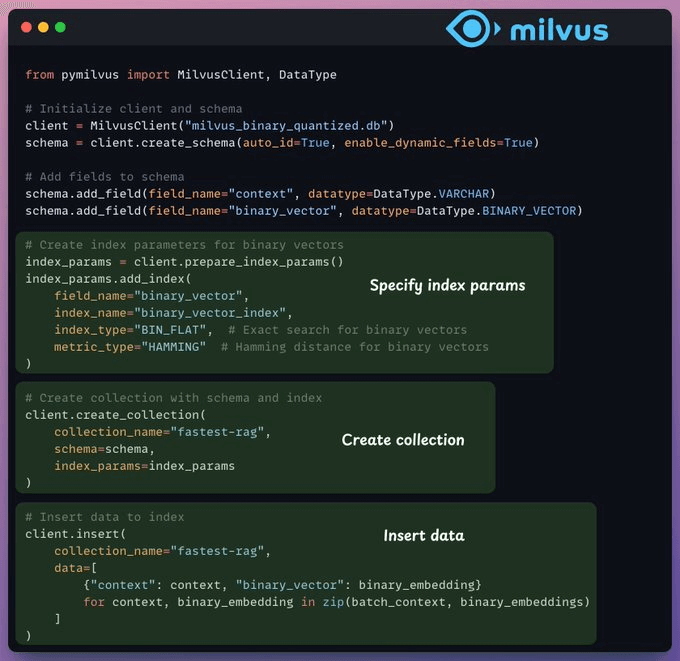
Indexes are specialized data structures that help optimize the performance of data retrieval operations.
Retrieval
In the retrieval stage, we:
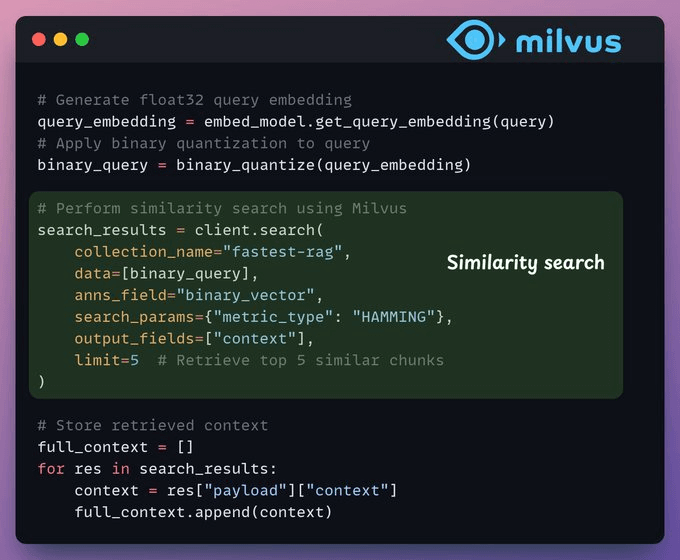
Embed the user query and apply binary quantization to it.
Use Hamming distance as the search metric to compare binary vectors.
Retrieve the top 5 most similar chunks.
Add the retrieved chunks to the context.
Generation
Finally, we build a generation pipeline using the Kimi-K2 instruct model, served on the fastest AI inference by Groq.
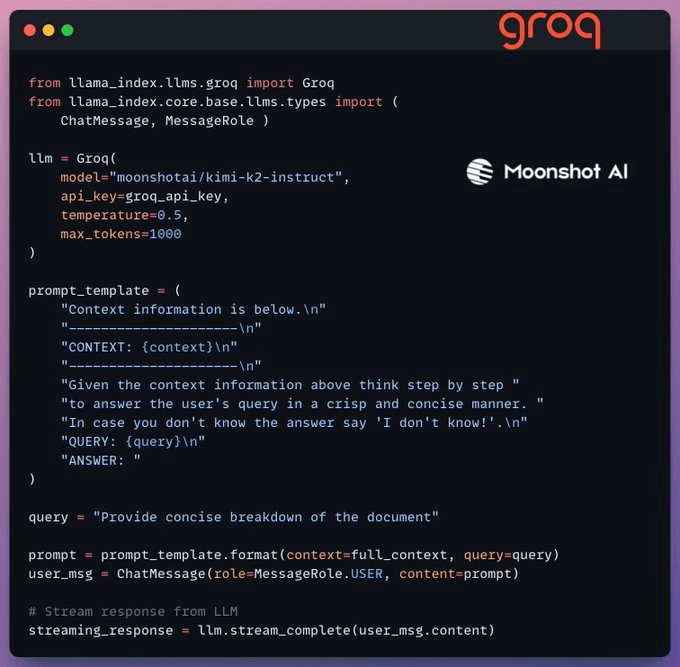
We specify both the query and the retrieved context in a prompt template and pass it to the LLM.
Deployment with Beam
Beam provides ultra-fast serverless deployment of any AI workflow. It is fully open-source, and you can self-host it on your premises (GitHub repo).
Thus, we wrap our app in a Streamlit interface, specify the Python libraries, and the compute specifications for the container.
Finally, we deploy the app in a few lines of code
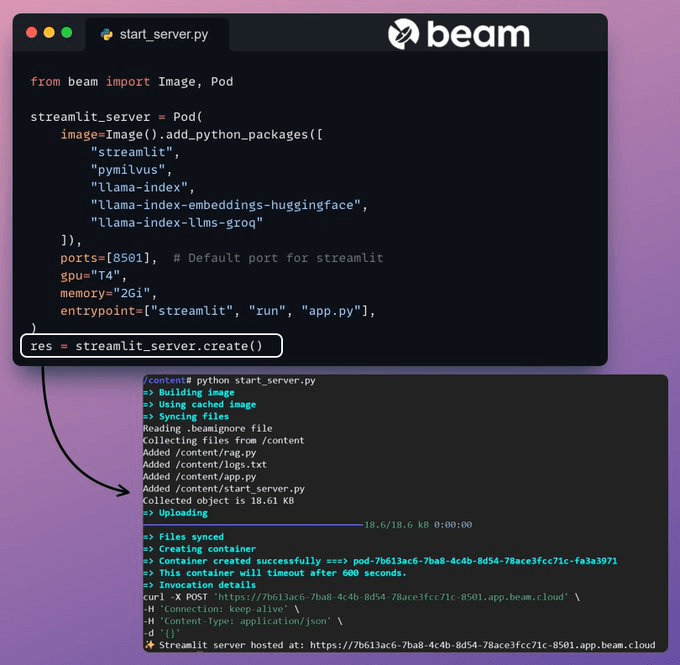
Run the app
Beam launches the container and deploys our streamlit app as an HTTPS server that can be easily accessed from a web browser.
Moving on, to truly assess the scale and inference speed, we test the deployed setup over the PubMed dataset (36M+ vectors).
Our app:
queried 36M+ vectors in <30ms.
generated a response in <1s.
Done!
We just built the fastest RAG stack leveraging BQ for efficient retrieval and using ultra-fast serverless deployment of our AI workflow.
Milvus docs on Binary Quantization →
You can find the code for today’s demo here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
