

I have been using FireDucks quite extensively lately.
For starters, FireDucks is a heavily optimized alternative to Pandas with exactly the same API as Pandas.
All you need to do is replace the Pandas import with the FireDucks import. That’s it.
As per FireDucks’ official benchmarks across 22 queries:

Modin had an average speed-up of 0.9x over Pandas.
Polars had an average speed-up of 39x over Pandas.
But FireDucks had an average speed-up of 50x over Pandas.
A demo of this speed-up is also shown in the video above.
At its core, FireDucks is heavily driven by lazy execution, unlike Pandas, which executes right away.
This allows FireDucks to build a logical execution plan and apply possible optimizations.
That said, FireDucks supports an eager execution mode as well, like Pandas, which you can use as follows:

So I tested Pandas and FireDucks head-to-head on several common tabular operations under eager evaluation.
The results have been summarized below:
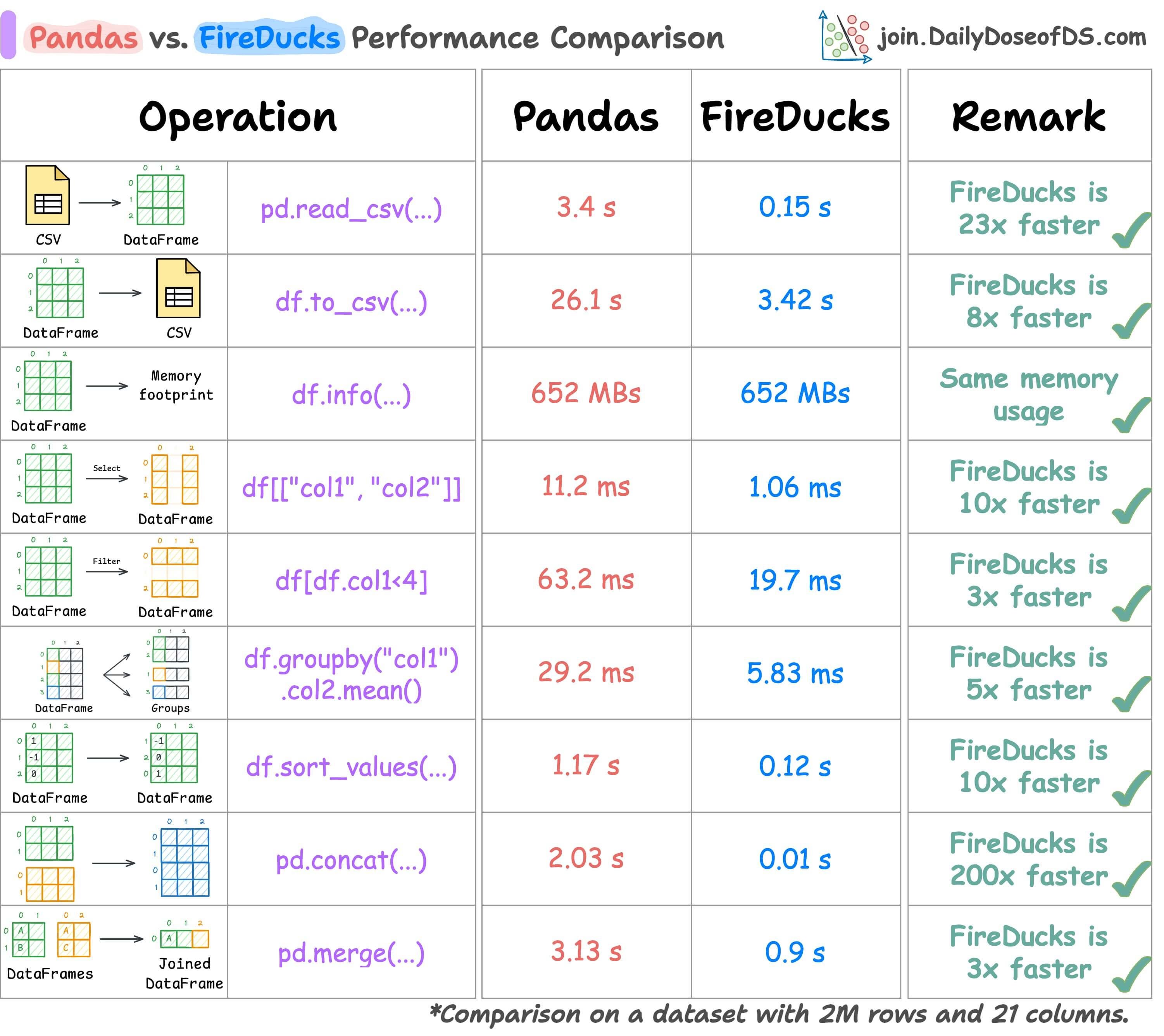
As depicted above, FireDucks performs better than Pandas in all operations.
Isn’t that amazing?
How to use FireDucks?
First, install the library:

Next, there are three ways to use it:
If you are using IPython or Jupyter Notebook, load the extension as follows:

Additionally, FireDucks also provides a pandas-like module (
fireducks.pandas), which can be imported instead of using Pandas. Thus, to use FireDucks in an existing Pandas pipeline, replace the standard import statement with the one from FireDucks:

Lastly, if you have a Python script, executing it as shown below will automatically replace the Pandas import statement with FireDucks:

Done!
It’s that simple to use FireDucks.
The code for the above benchmarks is available in this colab notebook.
👉 Over to you: What are some other ways to accelerate Pandas operations in general?
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn how to build real-world RAG apps, evaluate, and scale them: A crash course on building RAG systems—Part 3 (With Implementation).
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality.
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
