

If you have ever struggled to understand the DBSCAN clustering algorithm, such as:
What are core points, border points, and noise points?
How do its hyperparameters fit into the algorithm?
How it performs clustering?
…then the above video will help you build an intuitive understanding.
It covers all the steps that we typically follow in DBSCAN.
If you find animations like these useful, let me know. I’ll publish more such stuff:
Why DBSCAN?
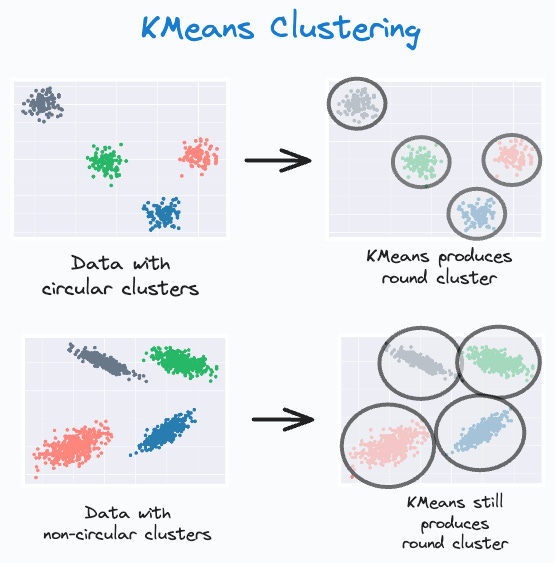
While KMeans is widely used due to its simplicity and effectiveness as a clustering algorithm, it has many limitations:
It does not account for cluster covariance.
It can only produce spherical clusters. As shown below, even if the data has non-circular clusters, it still produces round clusters.
Density-based algorithms, like DBSCAN, quite effectively address these limitations.
The video above explains how it works.
Of course, like any other algorithm, DBSCAN also has some limitations.
One significant limitation is its run-time, which grows quadratically with the number of data points, as depicted below:

DBSCAN++ is a major step towards a fast and scalable DBSCAN.
We covered it here: DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Note: I hired Mustafa Marzouk to create the above video. You can find him on LinkedIn here. He creates awesome animations in Manim.
👉 Over to you: What are some other limitations of DBSCAN?
Thanks for reading!
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
