

Recently, OpenAI released Swarm.
It’s an open-source framework designed to manage and coordinate multiple AI agents in a highly customizable way.
AI Agents are autonomous systems that can reason, think, plan, figure out the relevant sources and extract information from them when needed, take actions, and even correct themselves if something goes wrong.
Today, let’s cover a practical and hands-on demo of this. We’ll build an internet research assistant app that:
Accepts a user query.
Searches the web about it.
And turns it into a well-crafted article.
We shall use:
OpenAI Swarm for multi-agent orchestration.
Streamlit for the UI.
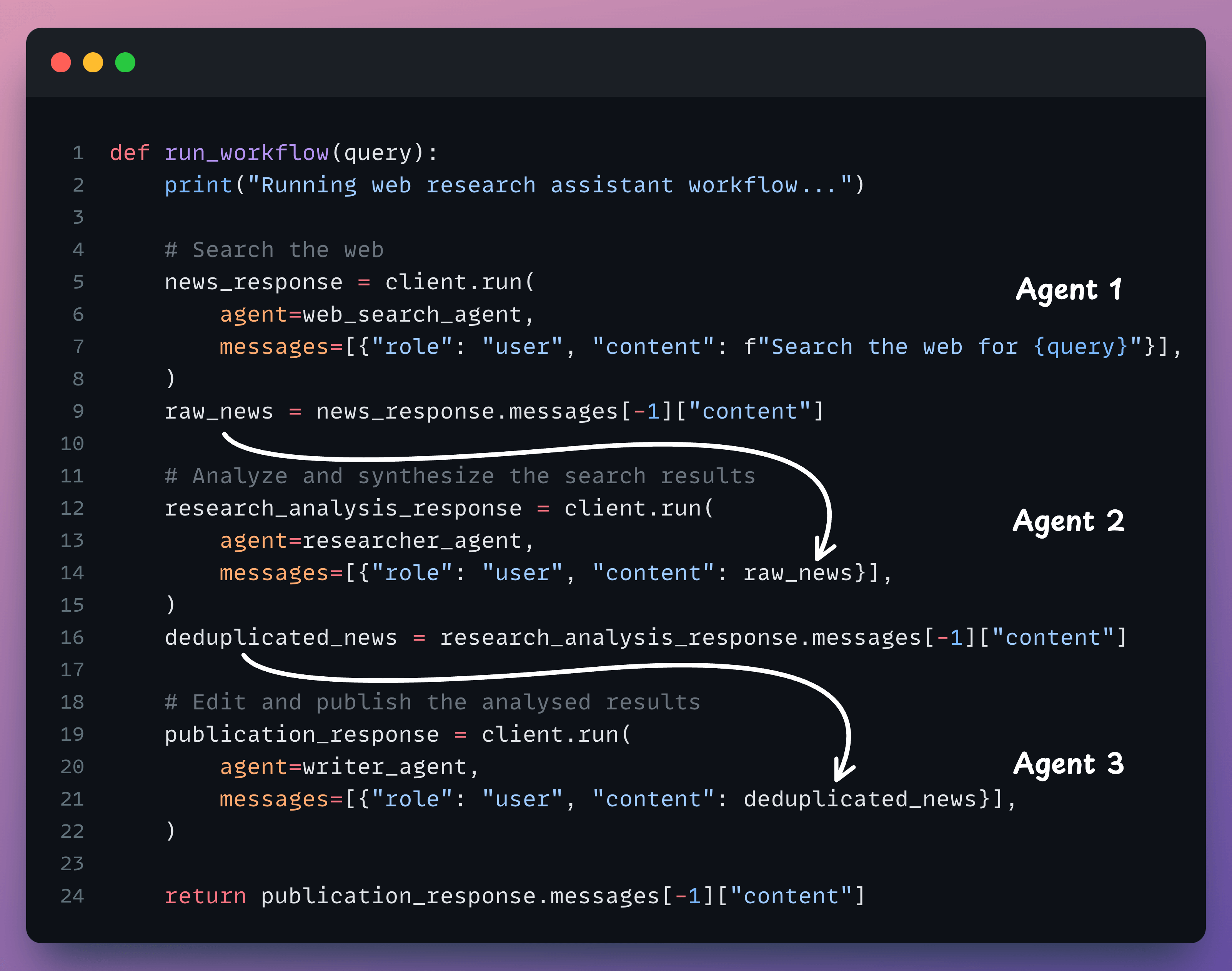
Here’s the step-by-step workflow of our multi-agent app.
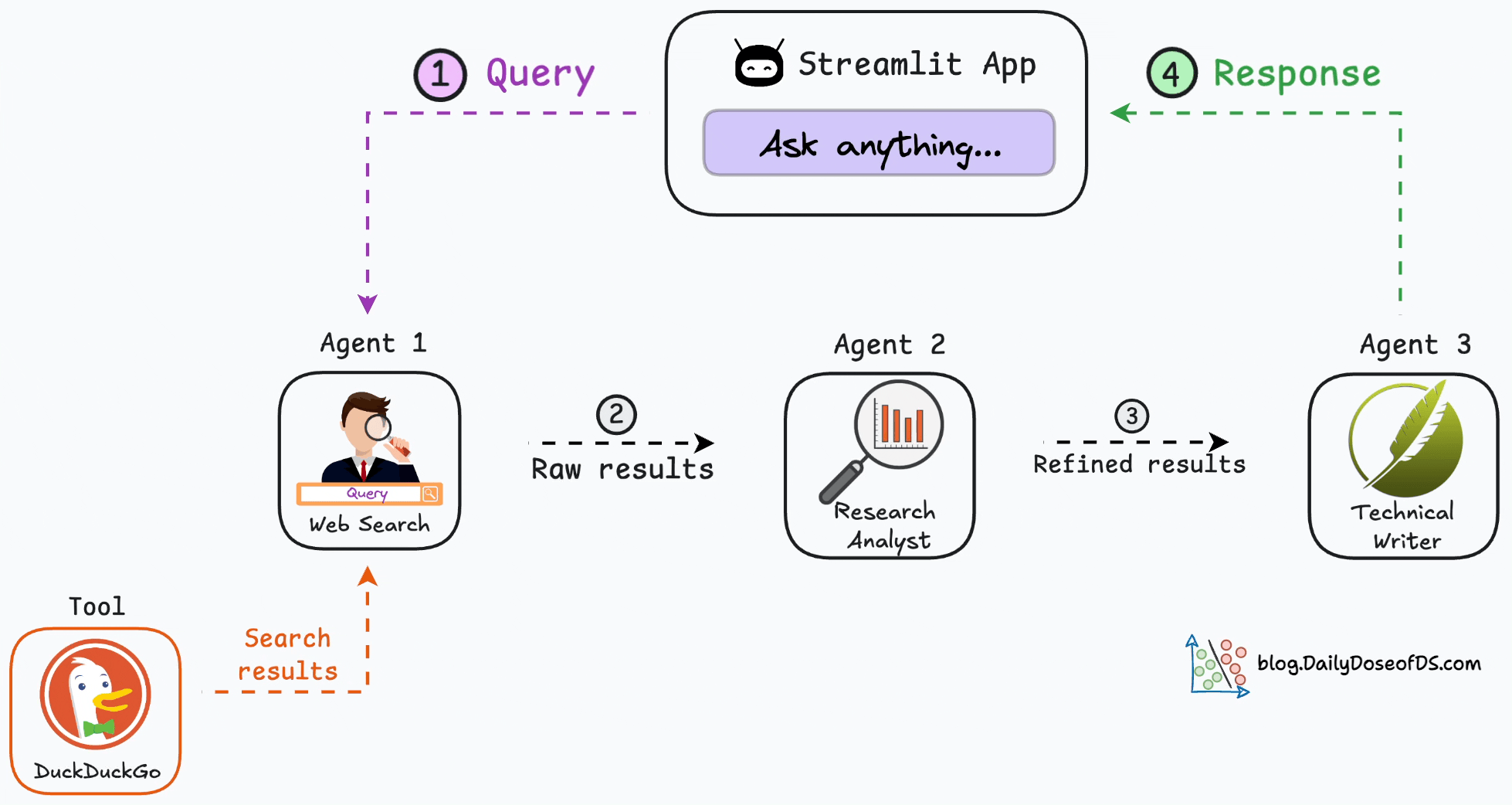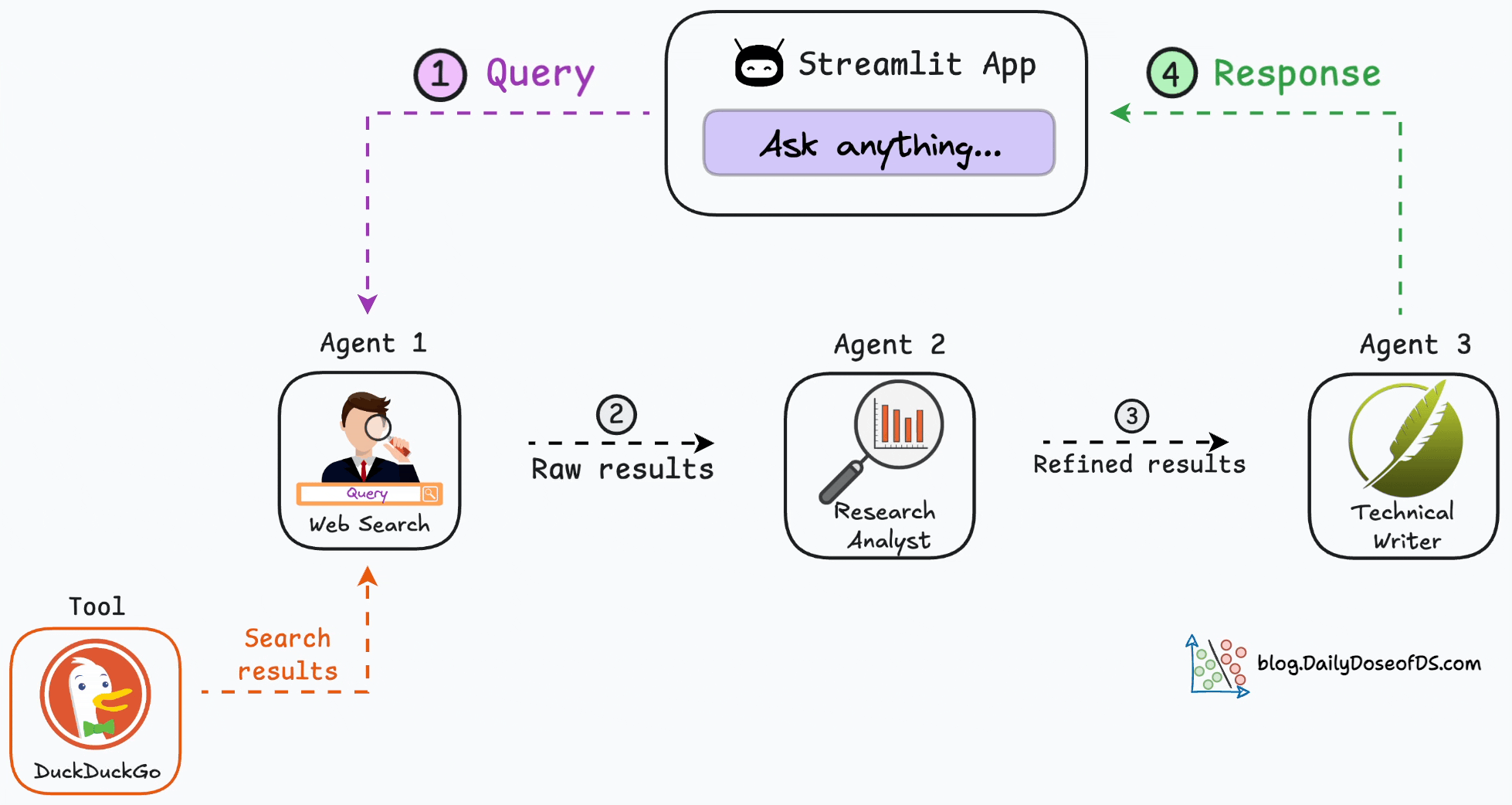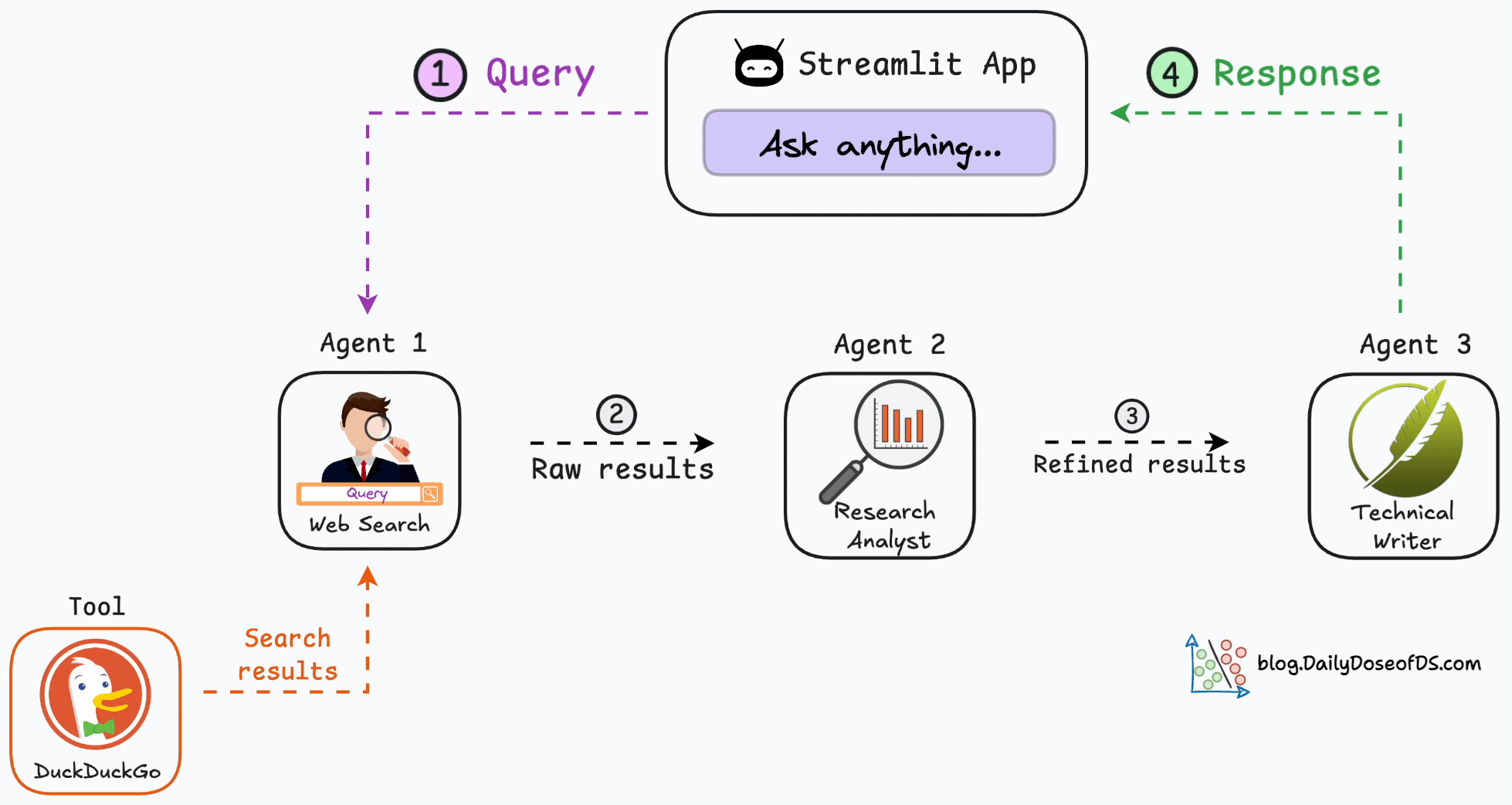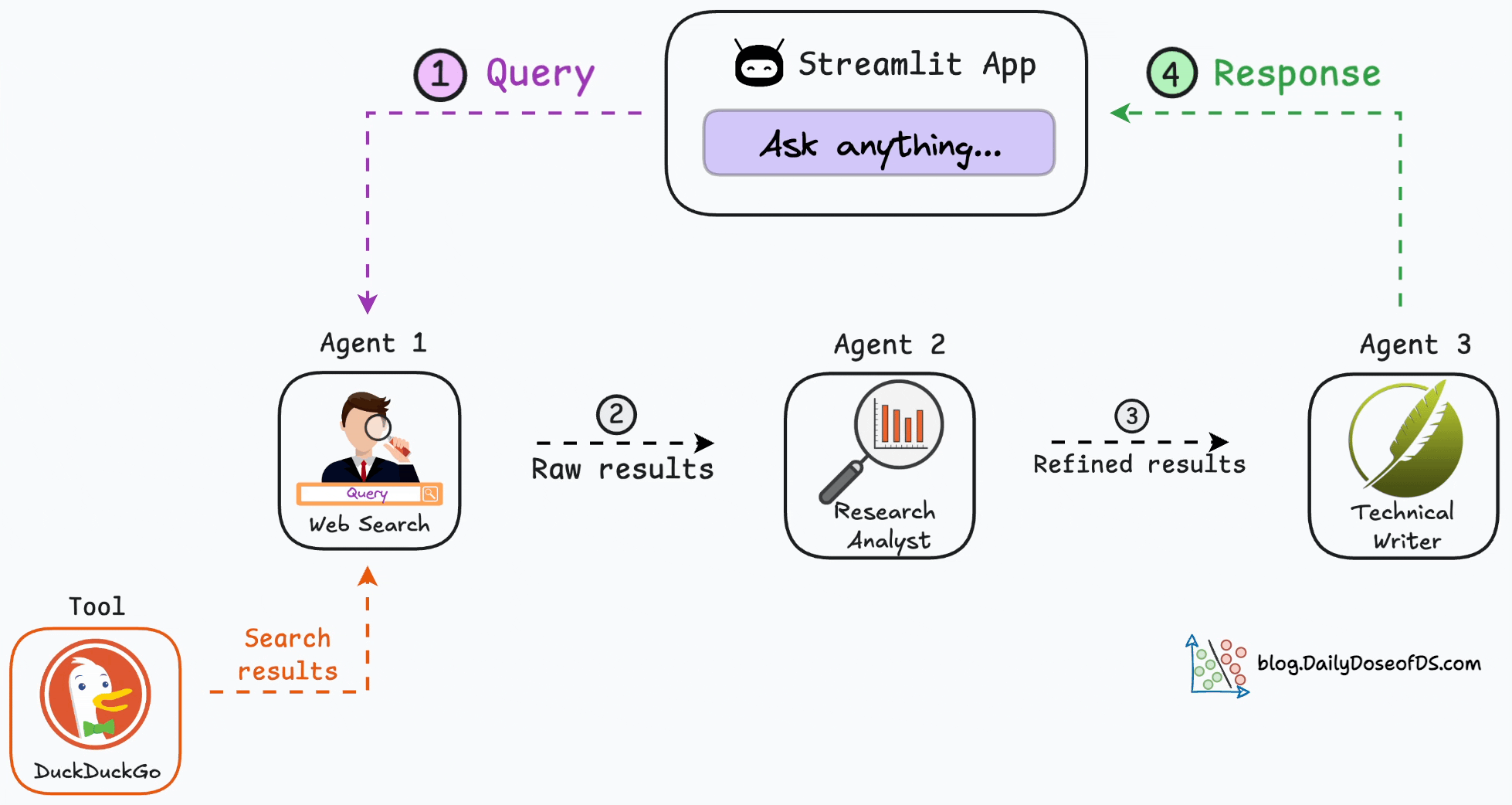
As depicted above, we have three agents:
Agent 1 → Accepts the user query and searches the web.
Agent 2 → Accepts the web results from Agent 1 and refines them.
Agent 3 → A technical writing agent that accepts the refined results, drafts an article, and sends it back to the user.
You can find the entire code in this GitHub repository: AI Engineering Hub.
Let’s build this application!
Imports
First, we begin with some standard imports:

We use Swarm from OpenAI to build our multi-agent app.
We use duckduckgo_search to search the web.
Next, we define the MODEL name, and initialize swarm client and search client:

Agent 1
This agent must accept the user’s query, search the web, and return the raw web results.

To build this, we first implement a function that accepts the query and returns the raw results.

Line 7: Search the web.
Line 9-16: Collect all the web results (title + URL + Body) in a single string and return it.
Next, we define our web search agent that will utilize the above function, and we also specify the instructions for this agent below:

Line 1: We specify the role.
Line 6-11: We define an object of Agent class (from OpenAI Swarm), specify the above function, the instructions, and the LLM.
Agent 2
The results returned by Agent 1 will be pretty messy and may have a ton of irrelevant information. We need another agent to filter the appropriate information.

Like Agent 1, we define another object of the Agent class and pass the instructions:

Agent 3
Finally, we build another agent that accepts the above-filtered results and drafts an article:

Stitch them together
While we have defined the three agents above, the multi-agent app does not know the order in which these agents must run and whose output must be passed to the next agent.
Thus, we need to stitch them together in a workflow function.
Let’s do it step by step for simplicity.
First, we pass the user query to the web search agent, which generates raw responses:

Next, we pass the raw responses to the web filter agent:
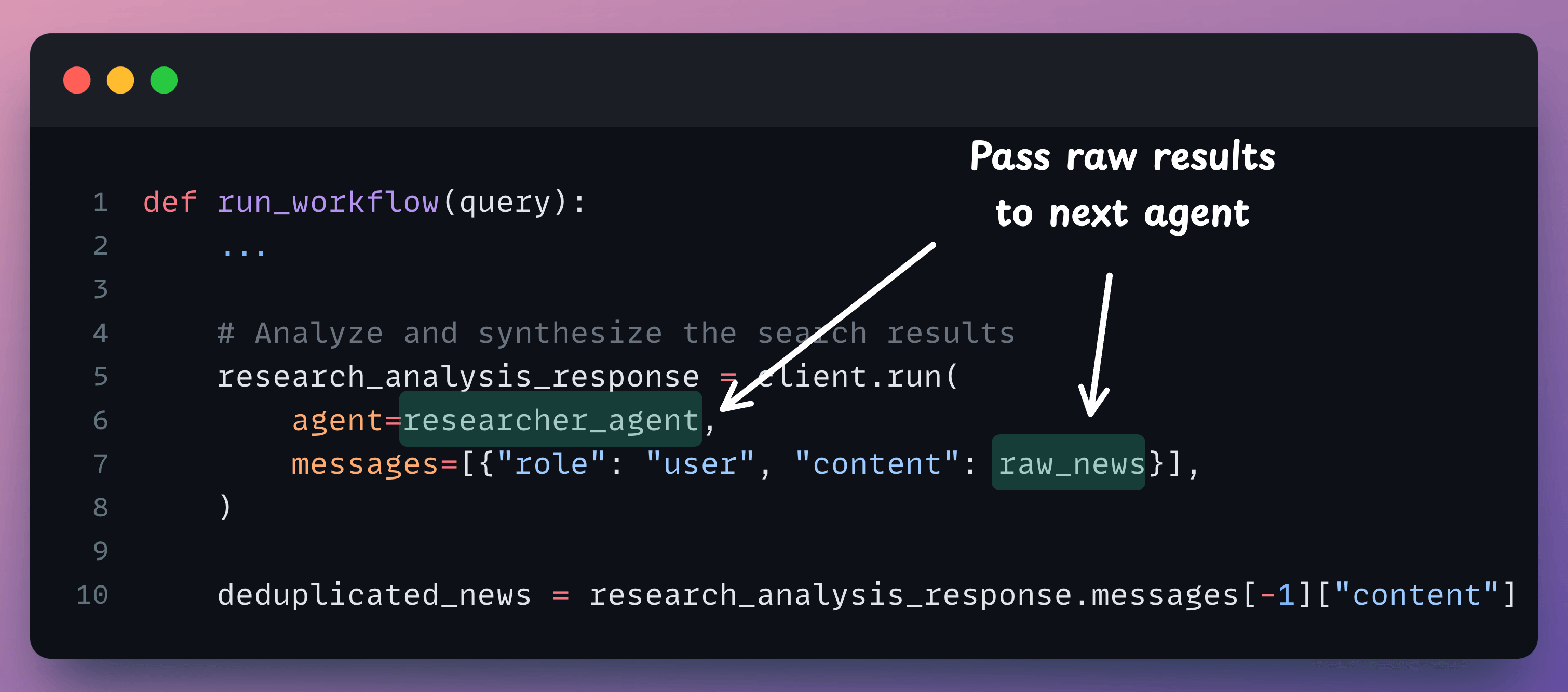
Finally, we pass the filtered results to the writing agent:

Done!
This is the entire code for the run_workflow method:
Executing the run_workflow method generates the desired output, as depicted below (and in the video at the top of this newsletter:

Of course, we did not cover the Streamlit part in this tutorial.
But you can find the entire code in this GitHub repository: AI Engineering Hub.
We launched this repo today, wherein we’ll publish the code for such hands-on AI engineering newsletter issues.
This repository will be dedicated to:
In-depth tutorials on LLMs and RAGs.
Real-world AI agent applications.
Examples to implement, adapt, and scale in your projects.
Find it here: AI Engineering Hub.
👉 Over to you: What other topics would you like to learn about?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 105,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
