

100% open-source serverless AI workflow orchestration

Julep AI is a serverless platform designed to help data and ML teams build intelligent workflows without the need to manage infrastructure.
Star the repo on GitHub (~5000 stars): GitHub repo.
Think of it as your control tower for orchestrating complex AI tasks—managing memory, state, parallel execution, and tool integration.
You just focus on creating smarter solutions and Julep does the heavy lifting.
Key features:
Smart memory: remembers context across interactions.
Workflow Engine: multi-step tasks with branching.
Parallel tasks: run operations simultaneously.
Seamlessly connects to external APIs.
Python & Node.js SDKs.
Real-time monitoring.
Reliable and secure.
Check it out below:
Thanks to Julep for partnering today!
[Hands-on] Corrective RAG Agentic Workflow
Corrective RAG (CRAG) is a common technique to improve RAG systems. It introduces a self-assessment step of the retrieved documents, which helps in retaining the relevance of generated responses.
Here’s an overview of how it works:
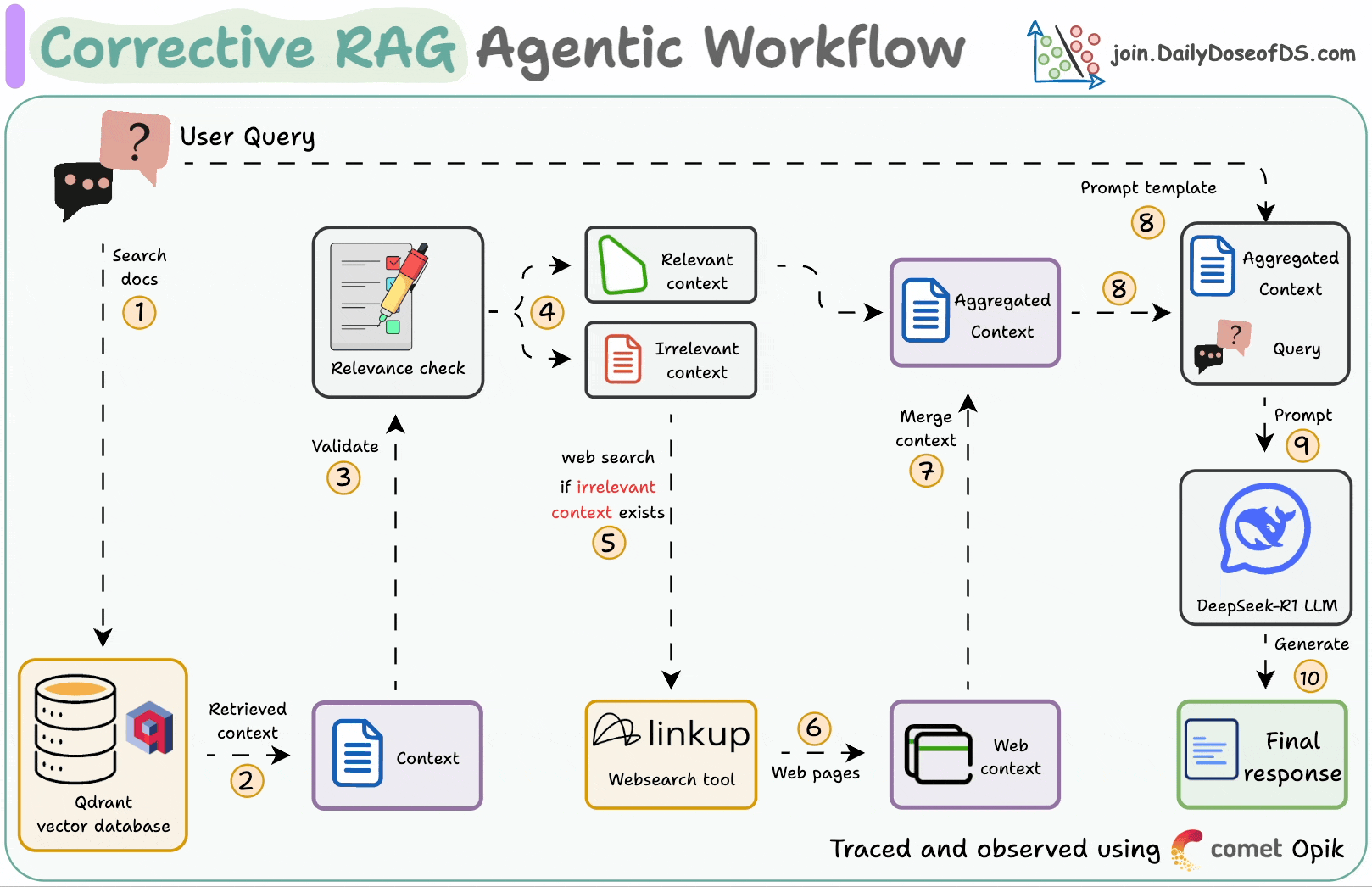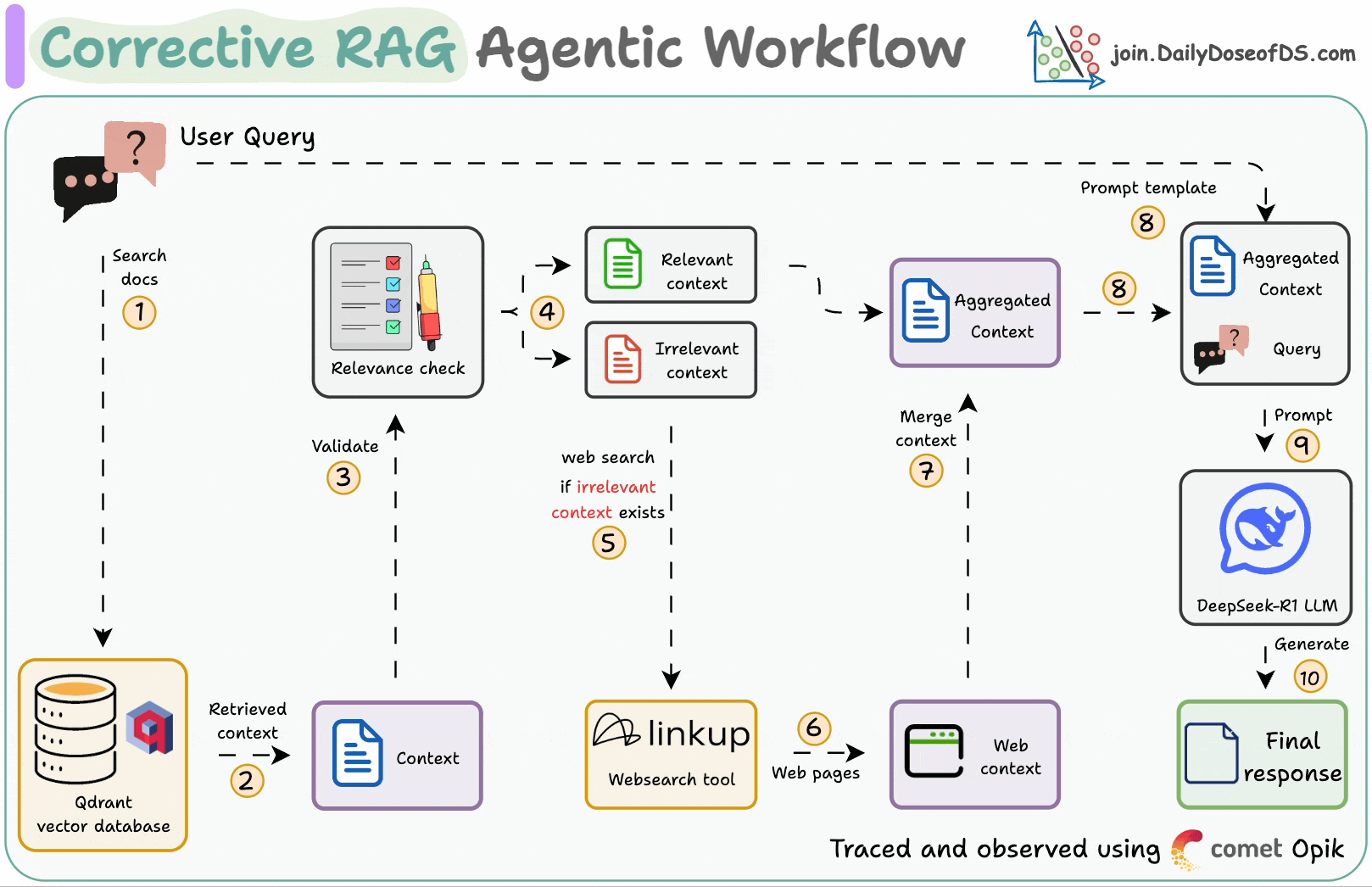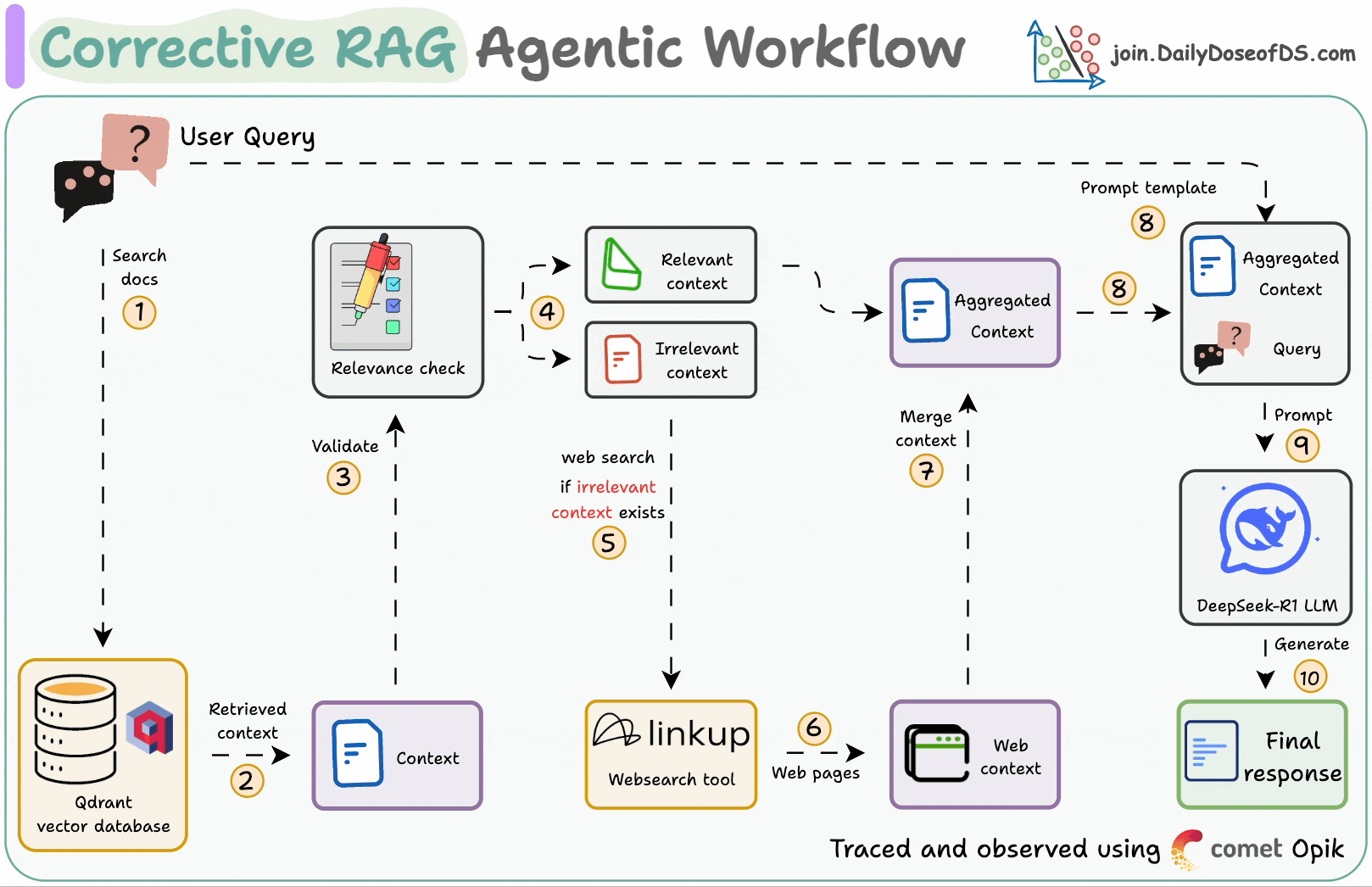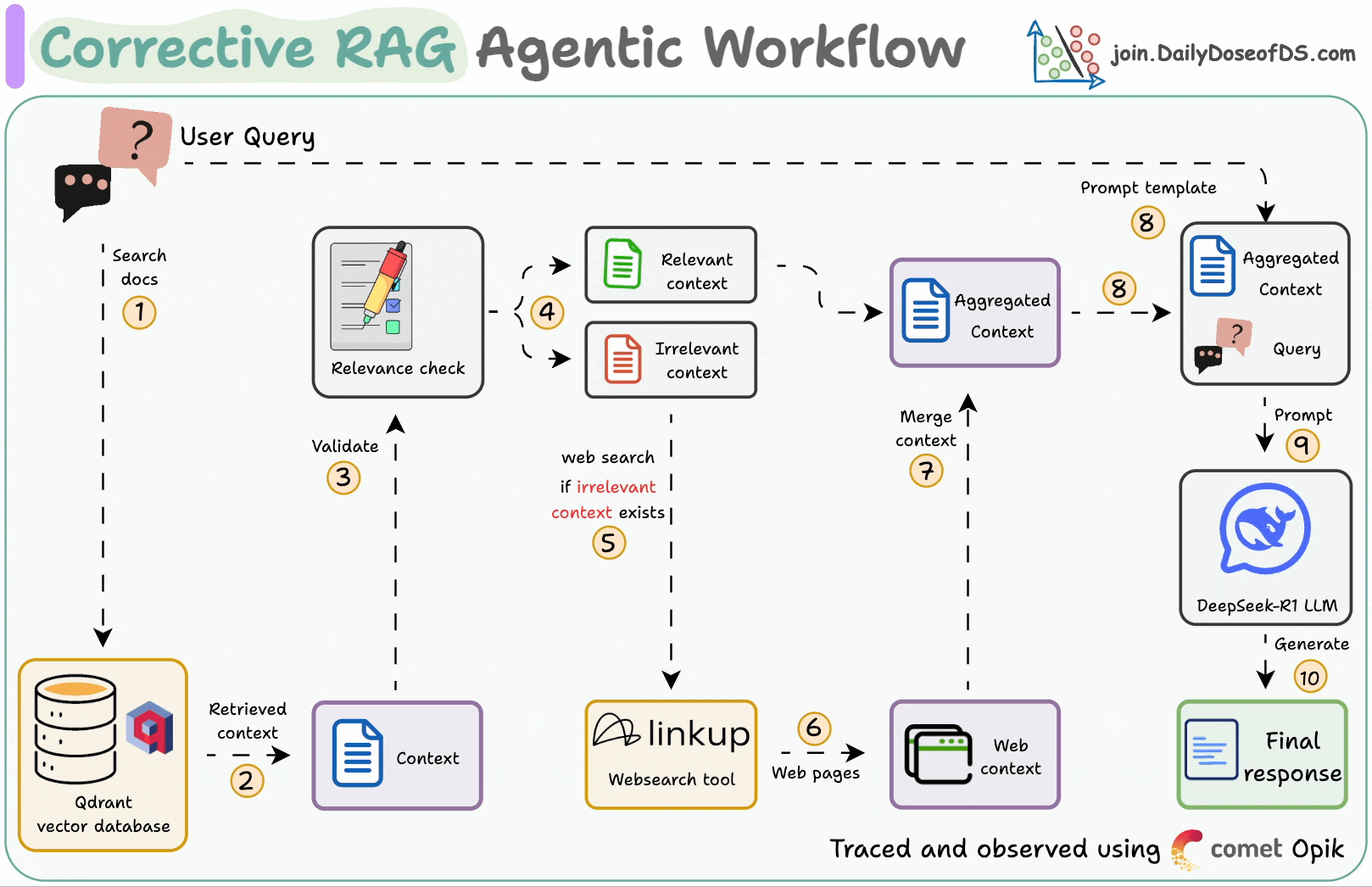
First search the docs with user query.
Evaluate if the retrieved context is relevant using LLM.
Only keep the relevant context.
Do web search if needed.
Aggregate the context & generate response.
The video at the top shows how it works!
Here’s our tech stack for this demo:
LlamaIndex workflows for orchestration
Linkup for deep web search
Cometml’s Opik to trace and monitor
Qdrant to self-host vectorDB.
The code is available in this Studio: Corrective RAG with DeepSeek-R1. You can run it without any installations by reproducing our environment below:

Let’s implement this today!
Setup LLM
We will use DeepSeek-R1 as LLM, locally served using Ollama.

Setup vectorDB
Our primary source of knowledge is the user documents that we index and store in a Qdrant vectorDB collection.

Set up web search tool
To equip our system with web search capabilities, we will use Linkup's state-of-the-art deep web search features. It also offers seamless integration with LlamaIndex.

Tracing and Observability
LlamaIndex also offers a seamless integration with CometML’s Opik. You can use this to trace every LLM call, monitor, and evaluate your LLM application.

Create the workflow
Now that we have everything set up, it's time to create the event-driven agentic workflow that orchestrates our application.

We pass in the LLM, vector index, and web search tool to initialise the workflow.
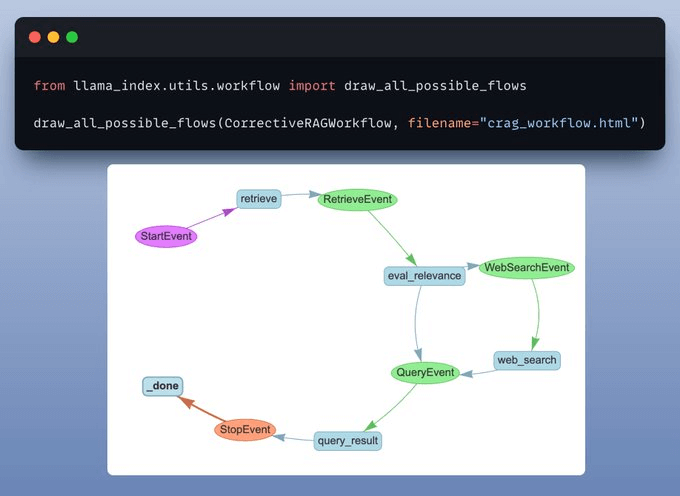
Visualize the workflow
You can also plot and visualize the workflow, which is really helpful for documentation and understanding how the app works.
Kickoff the workflow
Finally, when we have everything ready, we kick off our workflow.
Check this out👇

Here’s something interesting. While the vector database holds information about some research papers, it is still able to answer completely unrelated questions—thanks to the web search (which provides additional context when needed):

The code is available in this Studio: Corrective RAG with DeepSeek-R1. You can run it without any installations by reproducing our environment below:
If you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
👉 Over to you: What other RAG demos would you like to see?
Thanks for reading!
