

We learned about multi-agent Agentic design patterns yesterday:
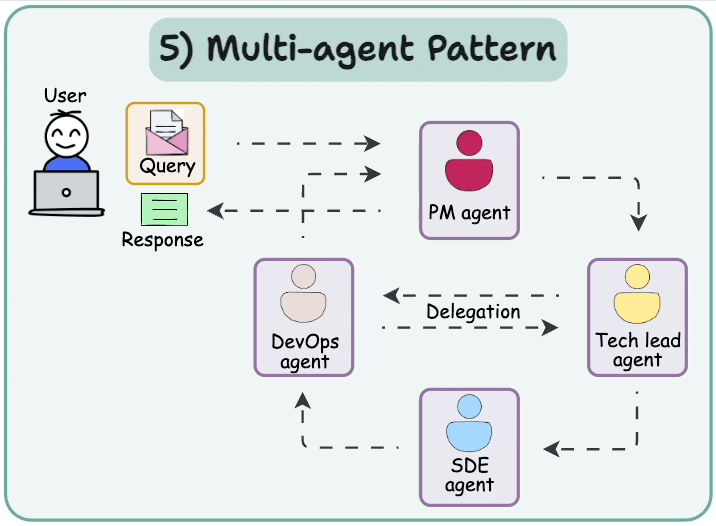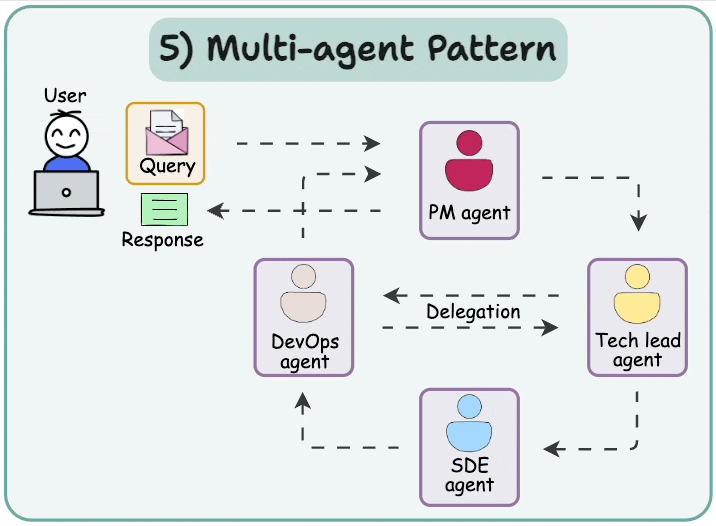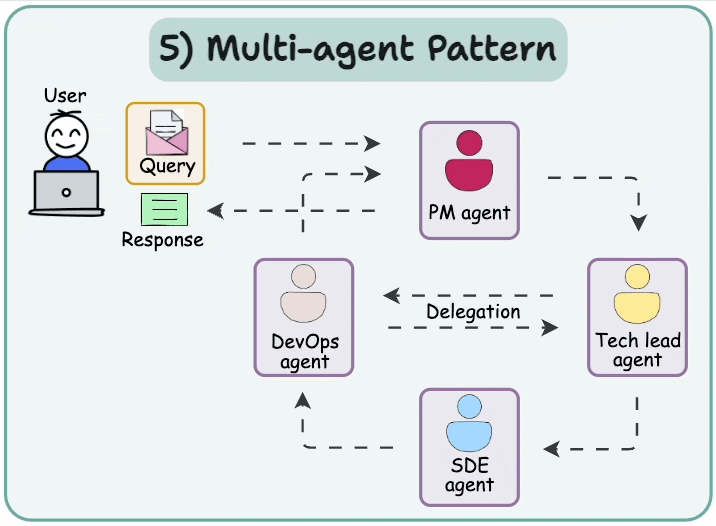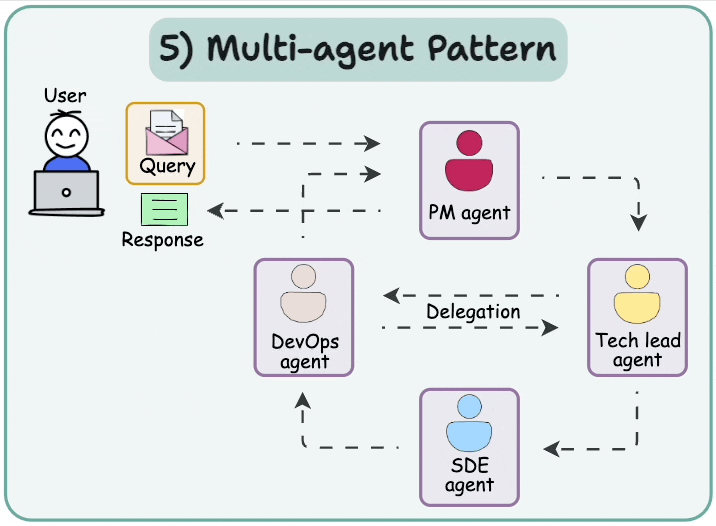
Today, let’s do a demo of this.
We’ll build an end-to-end workflow that:
Scrapes videos from multiple YouTube channels.
Employes a multi-agent system to report trends & insights.
Here’s our tech stack:
CrewAI for multi-agent orchestration.
Bright Data for reliable web-scraping at scale.
Streamlit for the UI.
Here’s the architectural overview highlighting the key components and their interactions (the code is available towards the end of the issue).
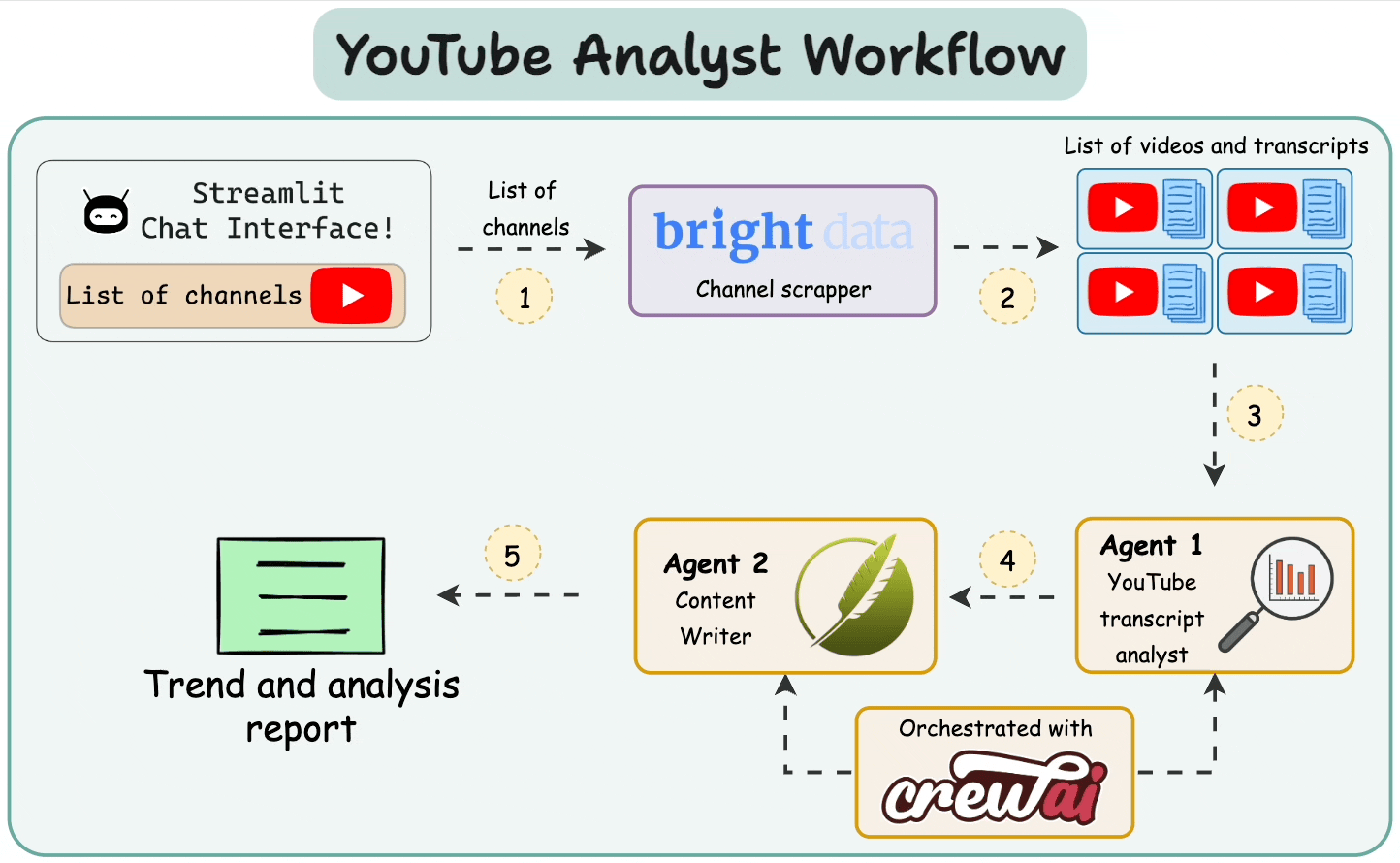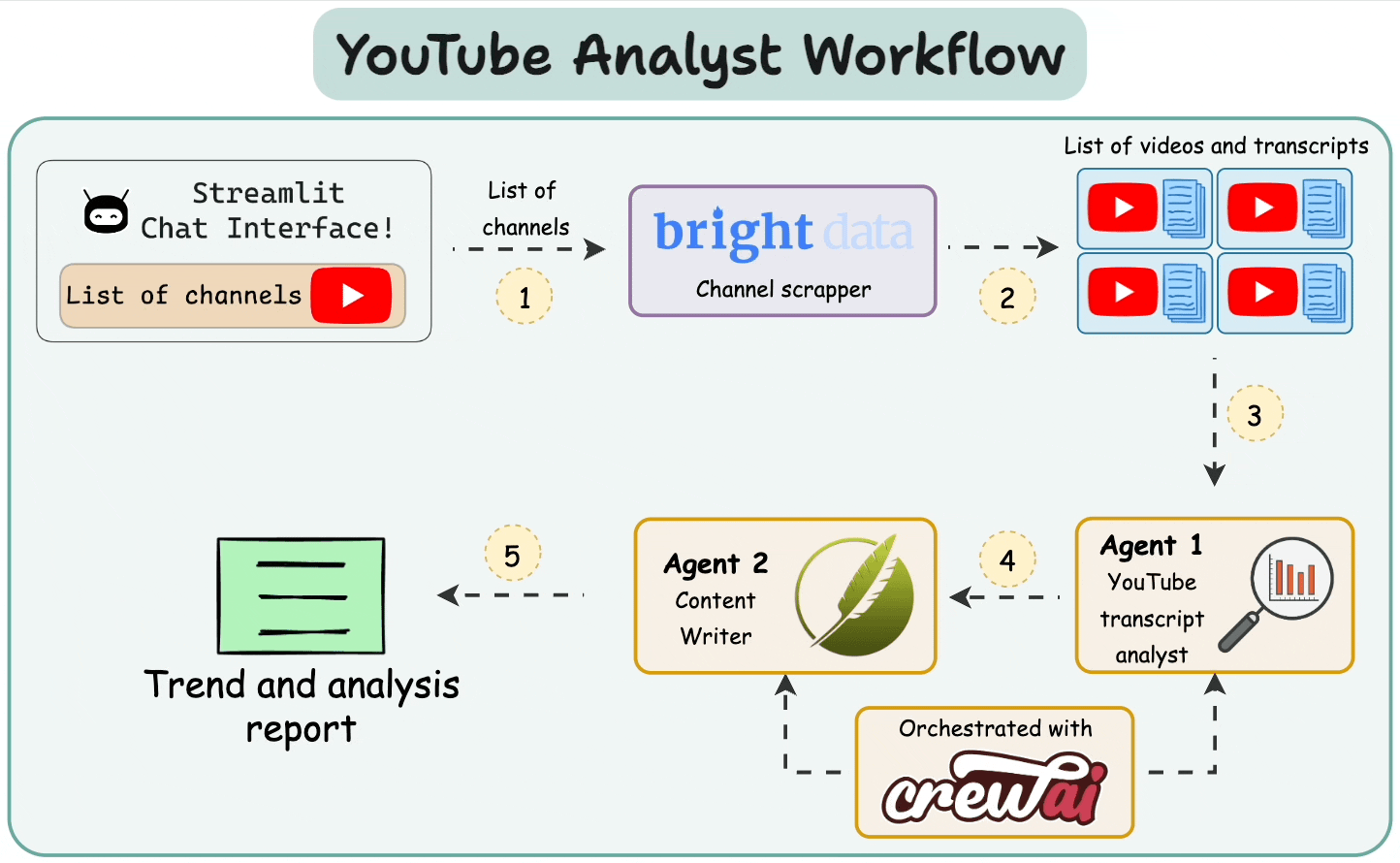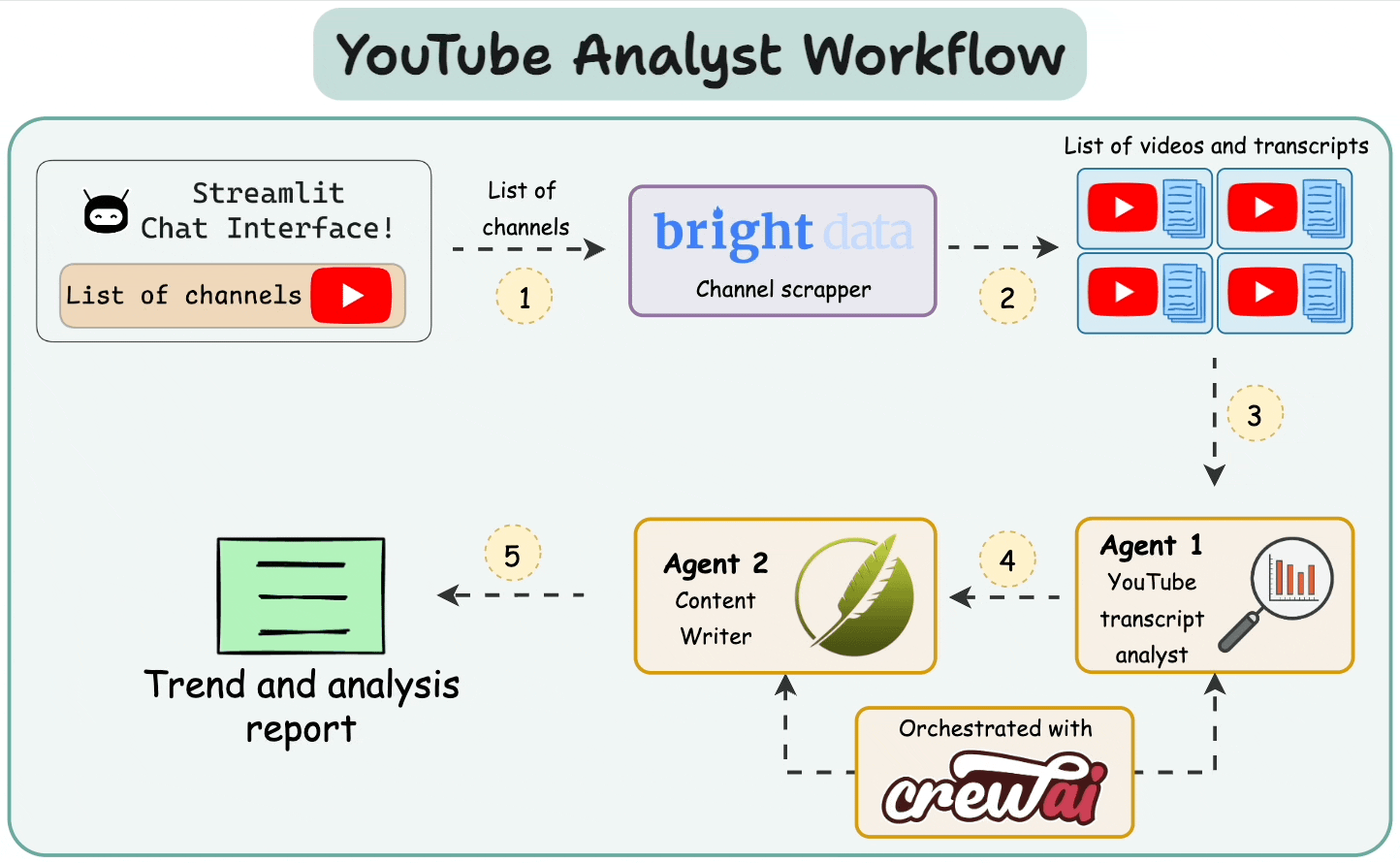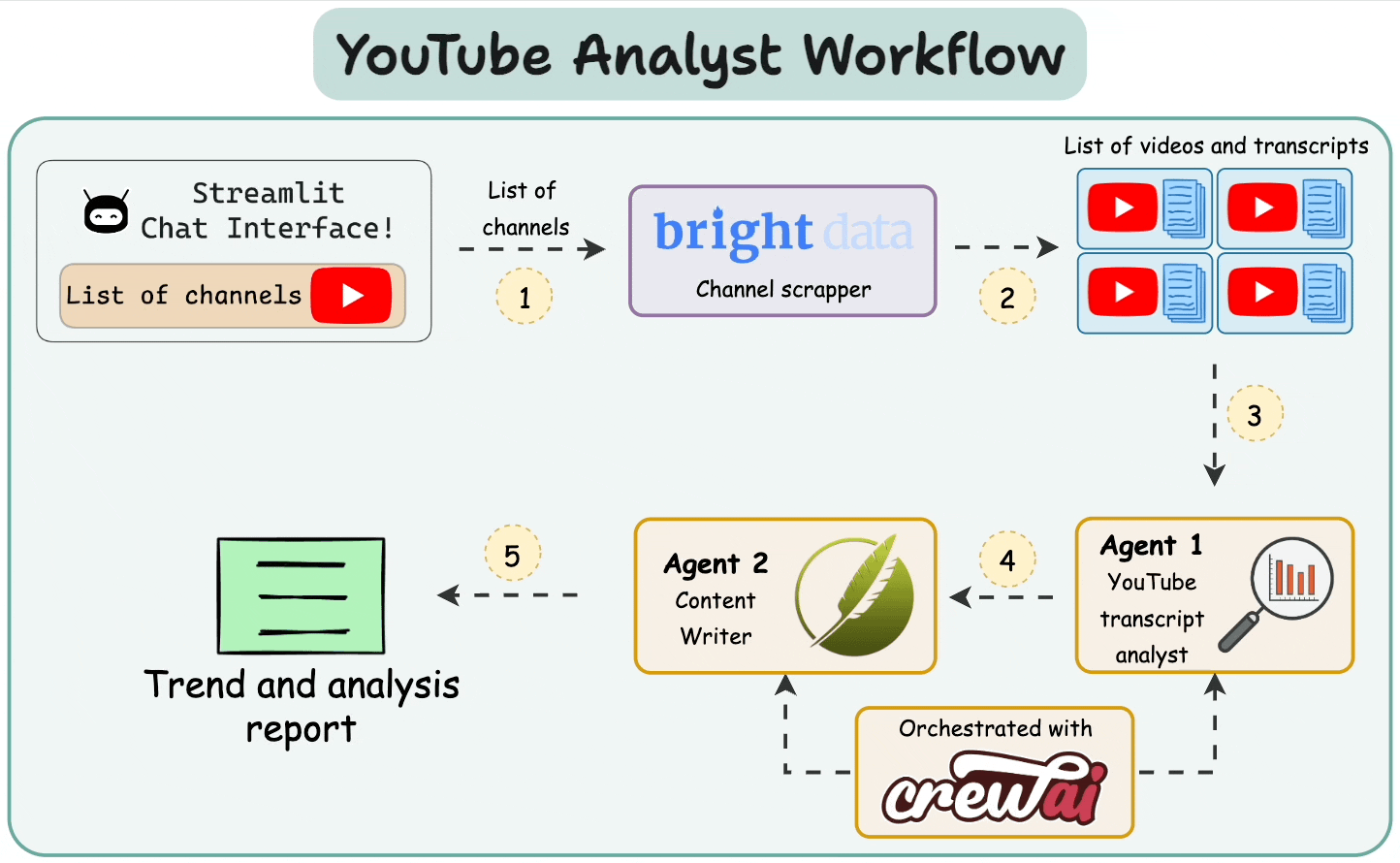
Let’s implement this workflow!
Setup
Create a .env file and add your Bright Data API key.

This will provide the complete infra to handle data extraction, user simulation, and real-time interactions for our AI app across the web.
Scrape videos
This code uses the Bright Data API to scrape YouTube videos from the specified channels released from (start_date, end_date).

We also specify the country we want to scrape our data from.
This returns a snapshot_id to check the status of the request and retrieve results once scrapping is done.
Once the request has been processed, we return a list of YouTube videos scraped by Bright Data:

Setup the LLM
CrewAI nicely integrates with all the popular LLMs and providers out there!
Here's how you set up and use a local DeepSeek-R1 with Ollama (:

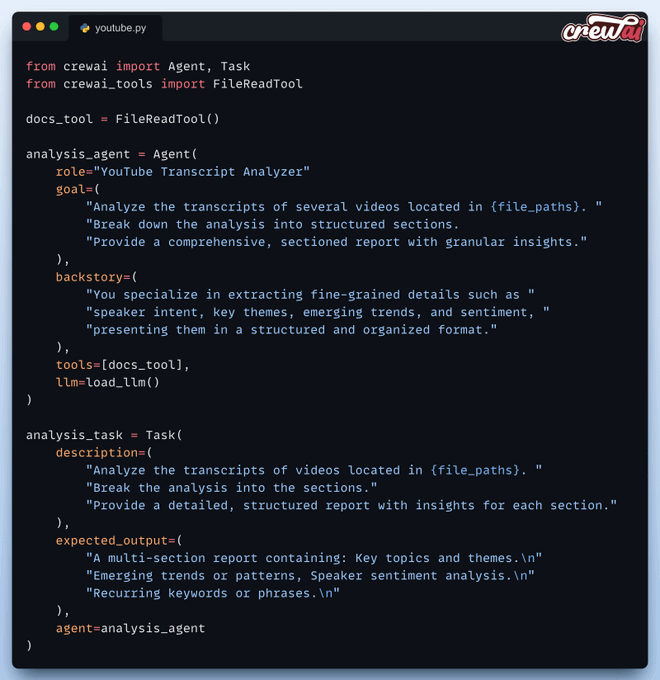
ollama and run “ollama pull deepseek-r1” in the command line.Agent 1) Transcript Analyst
The analyst agent analyzes the transcripts fetched through Bright Data and extracts key insights. It is also assigned a task to do so:
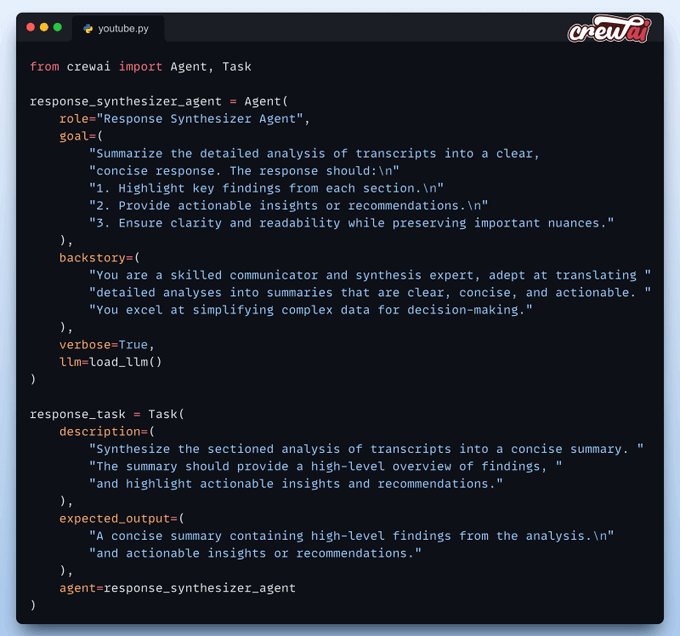
Agent 2) Response Gen
The Response Gen Agent takes the output of the analyst agent and generates a coherent response for the user.
Setup Crew
Once we have defined the agents and their tasks, we put them in a crew orchestrated using CrewAI.

Kickoff and results
Finally, we provide the transcript path obtained from Bright Data and kickoff the crew!

That was simple, wasn’t it?
A note about Bright Data
Building AI apps capable of interacting with real-time web data can feel impossible. Here are the challenges:
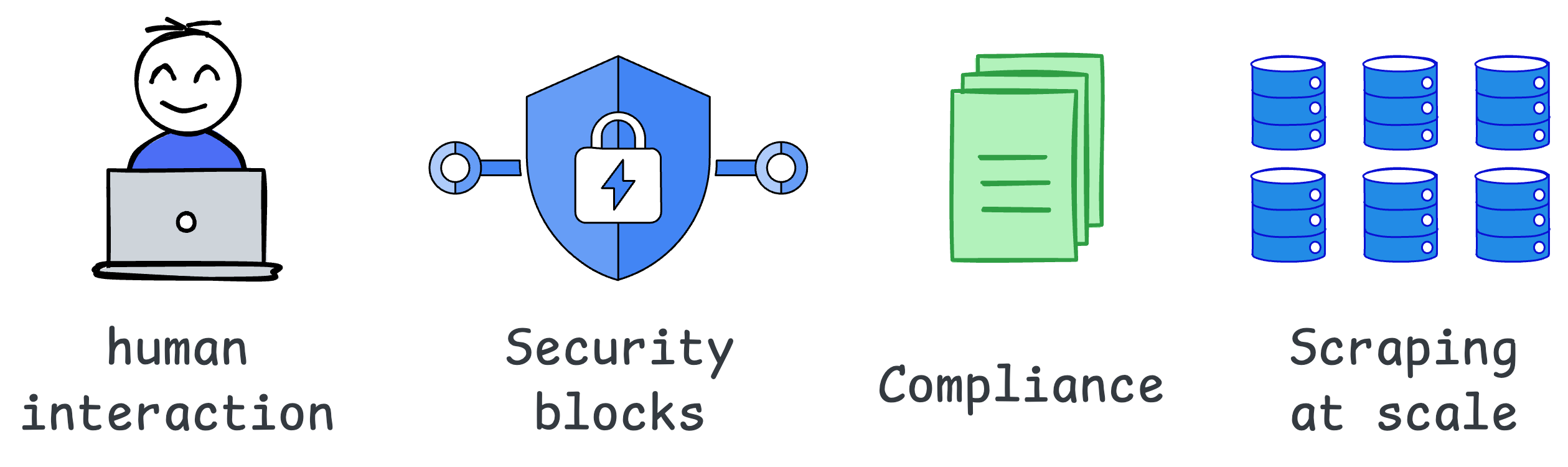
You must simulate human-like interactions.
You must overcome site blocks and captchas.
You must scrape accurate and clean data at scale.
You must ensure compliance with all legal standards.
Bright Data provides the complete infrastructure to handle data extraction, user simulation, and real-time interactions for your AI apps across the web.
With Bright Data, you can:
Access clean data from any public website with ease.
Simulate user behaviors at scale using advanced browser-based tools.
Enable AI models to retrieve real-time insights with a seamless Search API.
Thanks to Bright Data for letting us use their scrapping infra and partnering with us on this demo.
You can find the code here: YouTube multi-agent analyst.
👉 Over to you: What are some other challenges with traditional scrapping tools?
Thanks for reading!
