
The Data Science Glossary Chart
75 key terms all data scientists should know.

Data science has a pretty diverse glossary.
I once prepared the following glossary sheet, which lists the 75 most common and important terms data scientists use frequently in their day-to-day work. Thus, being aware of them is extremely crucial.
Wherever possible, I have linked my reference resources that explain these terms in detail.
How many terms do you know?

Let’s discuss them in brief one by one:
A:
Accuracy: Measure of the correct predictions divided by the total predictions.
Area Under Curve: Metric representing the area under the Receiver Operating Characteristic (ROC) curve, used to evaluate classification models.
ARIMA: Autoregressive Integrated Moving Average, a time series forecasting method.
B:
Bias: The difference between the true value and the predicted value in a statistical model.
Bayes Theorem: Probability formula that calculates the likelihood of an event based on prior knowledge.
Binomial Distribution: Probability distribution that models the number of successes in a fixed number of independent Bernoulli trials.
C:
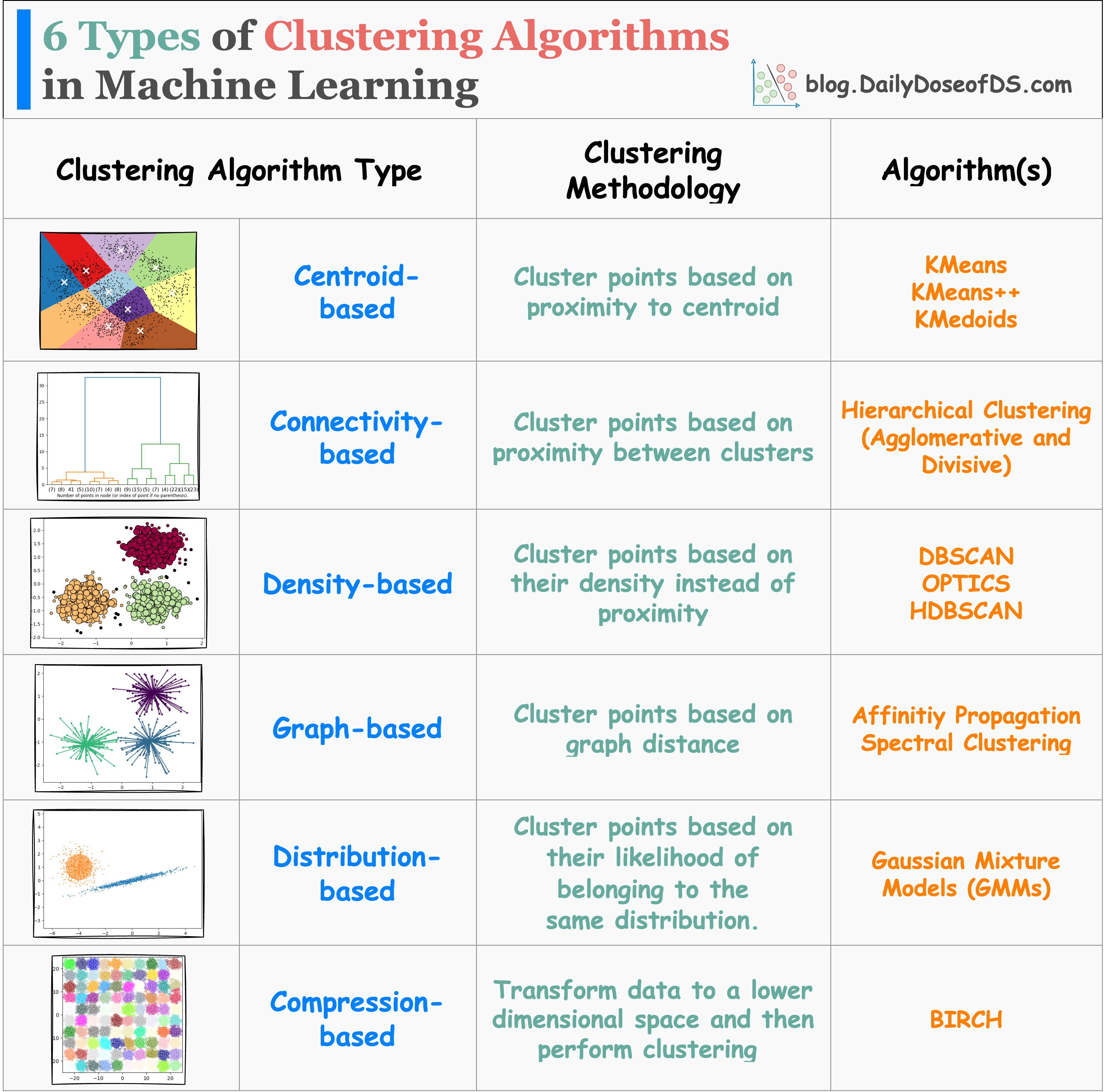
Clustering: Grouping data points based on similarities. Read the newsletter issue on 6 types of clustering algorithms here: The Categorization of Clustering Algorithms in Machine Learning
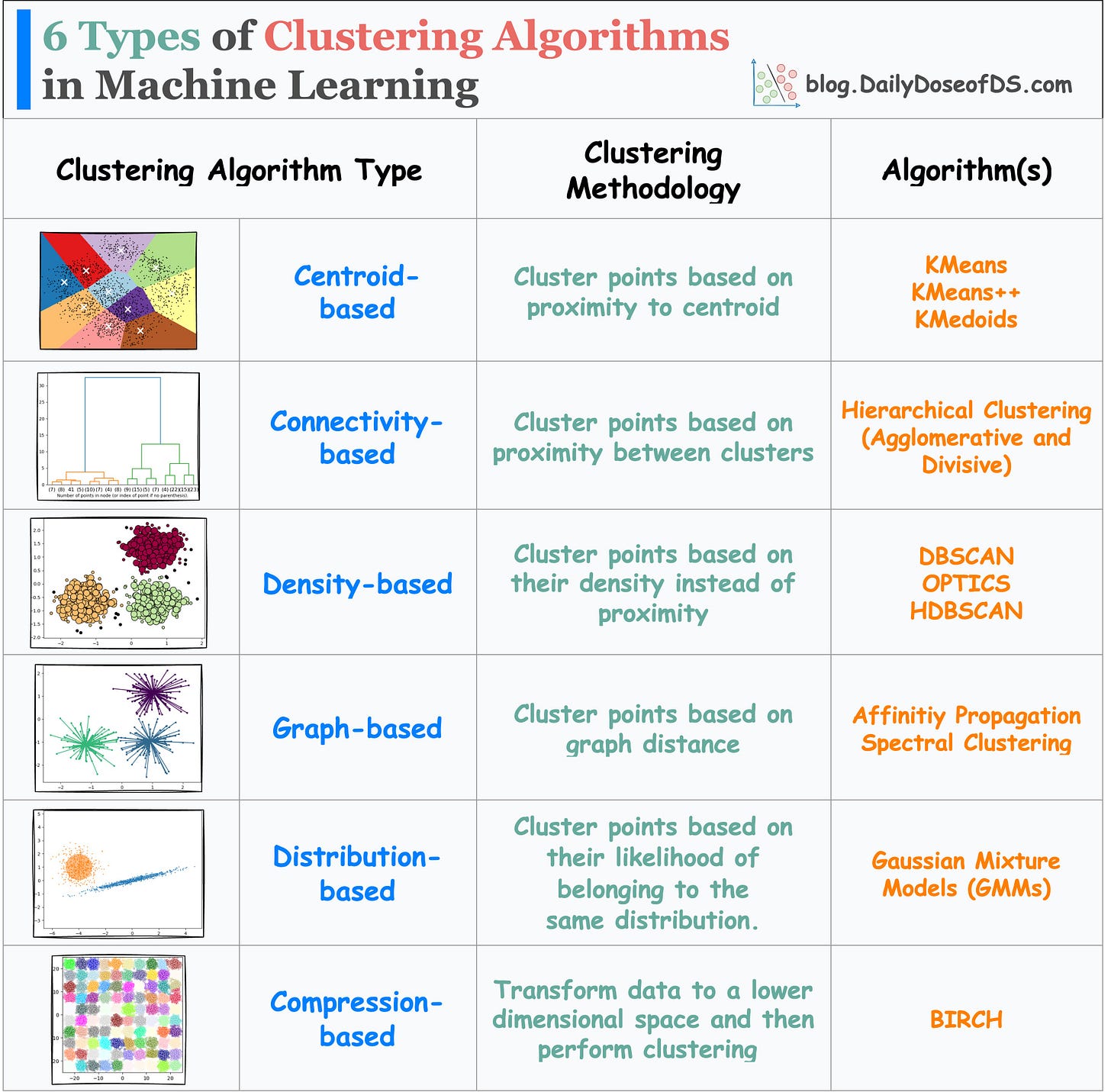
Confusion Matrix: Table used to evaluate the performance of a classification model.
Cross-validation: Technique to assess model performance by dividing data into subsets for training and testing. Read about 5 must-know cross-validation techniques here.
Here are three more terms that come to my mind:
Calibration: A crash course on calibration.
Conformal prediction: Conformal Predictions: Build Confidence in Your ML Model's Predictions
D:
Decision Trees: A tree-like model used for classification and regression tasks.
Dimensionality Reduction: Process of reducing the number of features in a dataset while preserving important information.
Discriminative Models: Models that learn the boundary between different classes. Read about discriminative models in this issue and how they differ from generative models in this issue.
E:
Ensemble Learning: Technique that combines multiple models to improve predictive performance.
EDA (Exploratory Data Analysis): Process of analyzing and visualizing data to understand its patterns and properties. Learn about 8 automated EDA tools in this issue.
Entropy: Measure of uncertainty or randomness in information.
F:
Feature Engineering: Process of creating new features from existing data to improve model performance.
F-score: Metric that balances precision and recall for binary classification.
Feature Extraction: Process of automatically extracting meaningful features from data.
G:
Gradient Descent: Optimization algorithm used to minimize a function by adjusting parameters iteratively.
Gaussian Distribution: Normal distribution with a bell-shaped probability density function.
Gradient Boosting: Ensemble learning method that builds multiple weak learners sequentially. Adaboost is a popular gradient-boosting algorithm. Learn how it works in this newsletter issue.
Graphs is another term that comes to my mind, which we covered here: A Crash Course on Graph Neural Networks (Implementation Included)
H:
Hypothesis: Testable statement or assumption in statistical inference.
Hierarchical Clustering: Clustering method that organizes data into a tree-like structure.
Heteroscedasticity: Unequal variance of errors in a regression model.
I:
Information Gain: Measure used in decision trees to determine the importance of a feature.
Independent Variable: Variable that is manipulated in an experiment to observe its effect on the dependent variable.
Imbalance: Situation where the distribution of classes in a dataset is not equal.
J:
Jupyter: Interactive computing environment used for data analysis and machine learning.
Joint Probability: Probability of two or more events occurring together.
Jaccard Index: Measure of similarity between two sets.
K:
Kernel Density Estimation: Non-parametric method to estimate the probability density function of a continuous random variable.
KS Test (Kolmogorov-Smirnov Test): Non-parametric test to compare two probability distributions. Read about it in this newsletter issue.

KMeans Clustering: Partitioning data into K clusters based on similarity.
L:
Likelihood: Chance of observing the data given a specific model. Understand the difference between likelihood and probability in this newsletter issue.
Linear Regression: Statistical method for modeling the relationship between dependent and independent variables.
L1/L2 Regularization: Techniques to prevent overfitting by adding penalty terms to the model’s loss function. Ever wondered where did the regularization term originated from? Read this article to understand everything about it: The Probabilistic Origin of Regularization.
M:
Maximum Likelihood Estimation: Method to estimate the parameters of a statistical model. Here’s an intuitive explanation to maximum likelihood estimation (MLE) in machine learning.
Multicollinearity: A situation where two or more independent variables are highly correlated in a regression model.
Mutual Information: Measure of the amount of information shared between two variables.
N:
Naive Bayes: Probabilistic classifier based on Bayes Theorem with the assumption of feature independence.
Normalization: Scaling data to have a mean of 0 and std-dev of 1.
Null Hypothesis: Hypothesis of no significant difference or effect in statistical testing.
O:
Overfitting: When a model performs well on training data but poorly on new, unseen data.
Outliers: Data points that significantly differ from other data points in a dataset.
One-hot encoding: Process of converting categorical variables into binary vectors. Here’s an issue on the most overlooked problem with one-hot encoding.
P:
PCA (Principal Component Analysis): Dimensionality reduction technique to transform data into orthogonal components. I have a full deep dive on PCA, which you can read here: Formulating the Principal Component Analysis (PCA) Algorithm From Scratch.
Precision: Proportion of true positive predictions among all positive predictions in a classification model. If you struggle to interpret precision and recall, this issue will solve it for you forever.
p-value: Probability of observing a result at least as extreme as the one obtained if the null hypothesis is true.
Q:
QQ-plot (Quantile-Quantile Plot): Graphical tool to compare the distribution of two datasets. Here’s a visual and intuitive guide to the QQ plot that will teach you how this plot is created and how to interpret it.
QR decomposition: Factorization of a matrix into an orthogonal and an upper triangular matrix.
Quantization: Converting the precision of numbers (mainly parameters) used in our model from a higher precision, like a 32-bit floating point number, to a lower precision, like 4-bit integers. We covered it here: Quantization: Optimize ML Models to Run Them on Tiny Hardware
R:
Random Forest: Ensemble learning method that uses multiple decision trees to make predictions with the help of bagging. Understand why bagging is so ridiculously effective at variance reduction here.
Recall: Proportion of true positive predictions among all actual positive instances in a classification model.
ROC Curve (Receiver Operating Characteristic Curve): Graph showing the performance of a binary classifier at different thresholds.
S:
SVM (Support Vector Machine): Supervised machine learning algorithm used for classification and regression.
Standardisation: Scaling data to have a mean of 0 and a standard deviation of 1.
Sampling: Process of selecting a subset of data points from a larger dataset.
T:
t-SNE (t-Distributed Stochastic Neighbor Embedding): Dimensionality reduction technique for visualizing high-dimensional data in lower dimensions. I have a full deep dive on t-SNE, which you can read here: Formulating and Implementing the t-SNE Algorithm From Scratch.
t-distribution: Probability distribution used in hypothesis testing when the sample size is small. The above t-SNE guide will also clear what t-distribution is.
Type I/II Error: Type I error is a false positive, and Type II error is a false negative in hypothesis testing.
U:
Underfitting: When a model is too simple to capture the underlying patterns in the data.
UMAP (Uniform Manifold Approximation and Projection): Dimensionality reduction technique for visualizing high-dimensional data.
Uniform Distribution: Probability distribution where all outcomes are equally likely.
V:
Variance: Measure of the spread of data points around the mean.
Validation Curve: Graph showing how model performance changes with different hyperparameter values.
Vanishing Gradient: Issue in deep neural networks when gradients become very small during training.
W:
Word embedding: Representation of words as dense vectors in natural language processing. If you want to learn about the history of embeddings, you should not miss this insightful issue: A Pivotal Moment in NLP Research Which Made Static Embeddings (Almost) Obsolete.
Word cloud: Visualization of text data where word frequency is represented through the size of the word.
Weights: Parameters that are learned by a machine learning model during training.
X:
XGBoost: Extreme Gradient Boosting, a popular gradient boosting library. We formulated and implemented XGBoost from scratch here.
XLNet: Generalized Autoregressive Pretraining of Transformers, a language model.
Y:
YOLO (You Only Look Once): Real-time object detection system.
Yellowbrick: Python library for machine learning visualization and diagnostic tools.
Z:
Z-score: Standardized value representing how many standard deviations a data point is from the mean.
Z-test: Statistical test used to compare a sample mean to a known population mean.
Zero-shot learning: Machine learning method where a model can recognize new classes without seeing explicit examples during training.

👉 Over to you: Of course, a lot has been left out here. As an exercise, can you add more terms to this?
For those who want to build a career in DS/ML on core expertise, not fleeting trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 88,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.