
The Best of DailyDoseofDS
2024 Recap.

As we come to the end of 2024, today, we thought of doing a quick recap by sharing some of the best newsletter issues released in 2024.
For simplicity, we have classified them into three categories.
Before we begin: We are always seeking critical feedback to improve this newsletter, which in turn, helps you grow.
If you have any critical feedback to share with us, please reply to this email. We would GREATLY appreciate that.
Category #1: LLMs, RAGs, and Agents
1) What exactly is temperature in LLMs? Learn about it here →
2) It's easier to run an open-source LLM locally than most people think. Here is a step-by-step, hands-on guide on running LLMs locally with Ollama →
3) Consider this:
GPT-3.5-turbo had a context window of 4,096 tokens.
Later, GPT-4 took that to 8,192 tokens.
Claude 2 reached 100,000 tokens.
Llama 3.1 → 128,000 tokens.
Gemini → 1M+ tokens.
Two techniques that help us extend the context length of LLMs →
4) Using traditional fine-tuning for LLMs is infeasible.
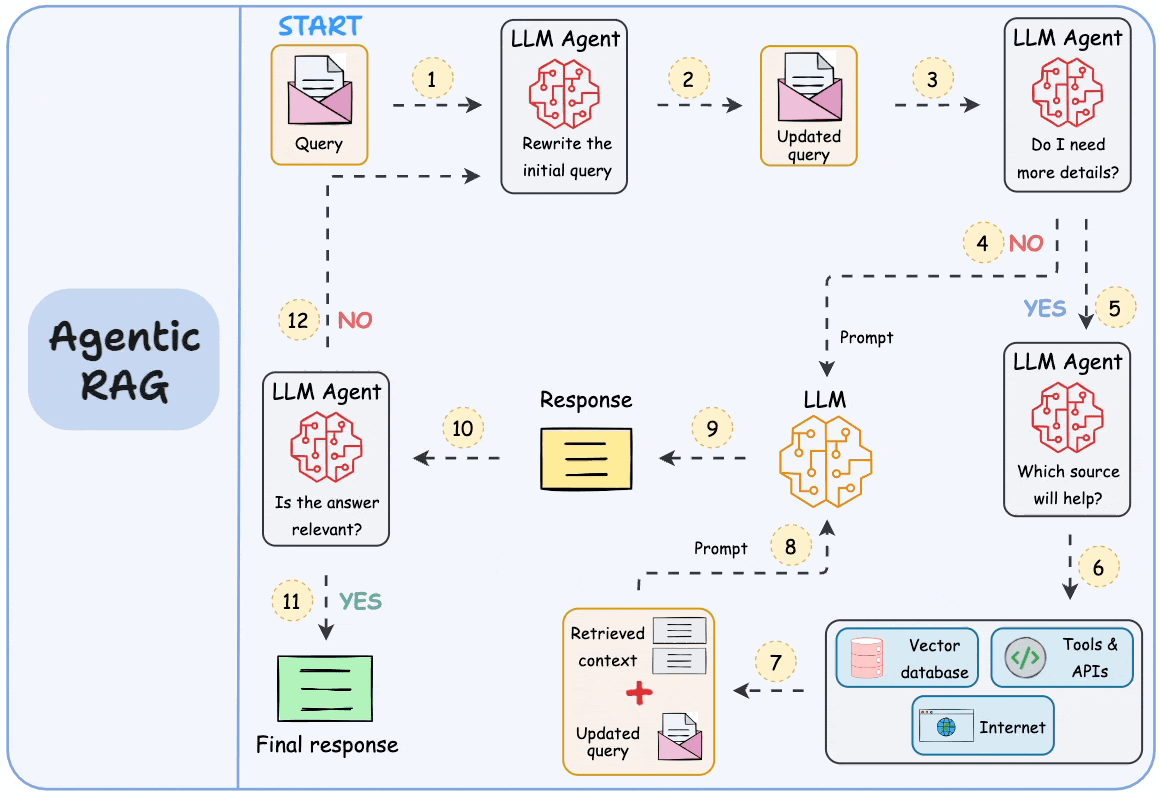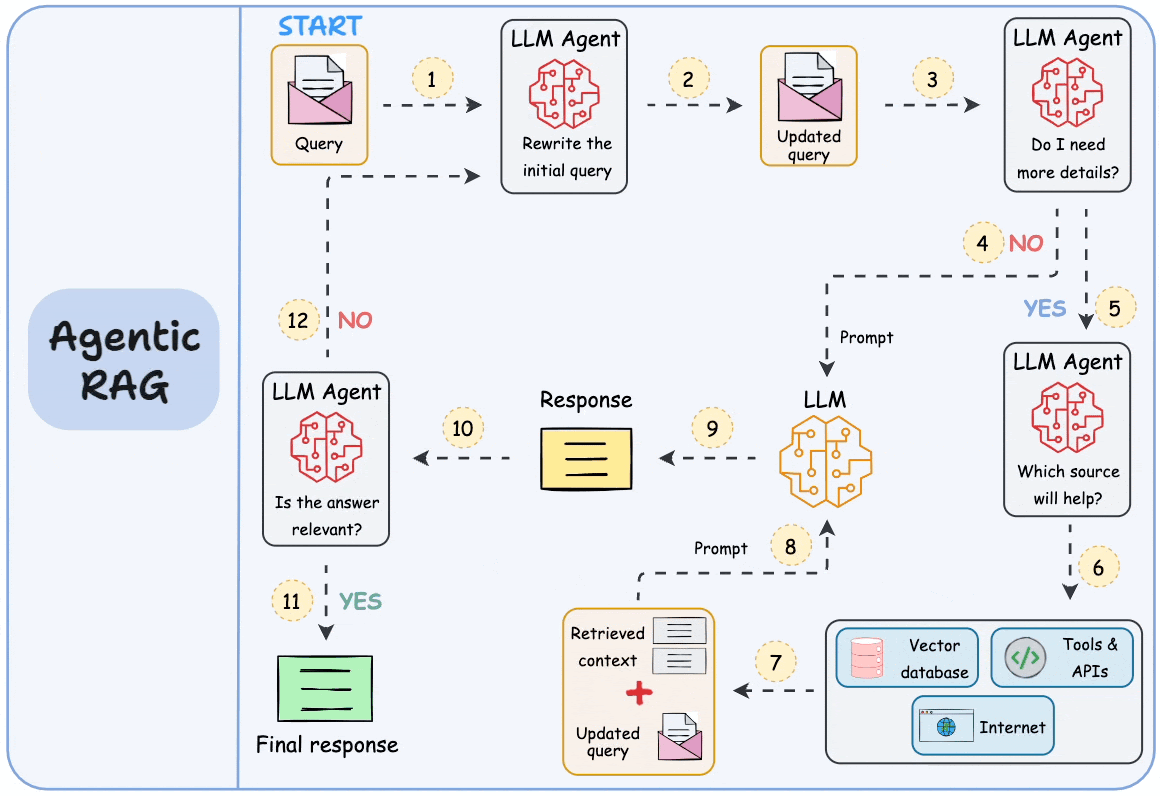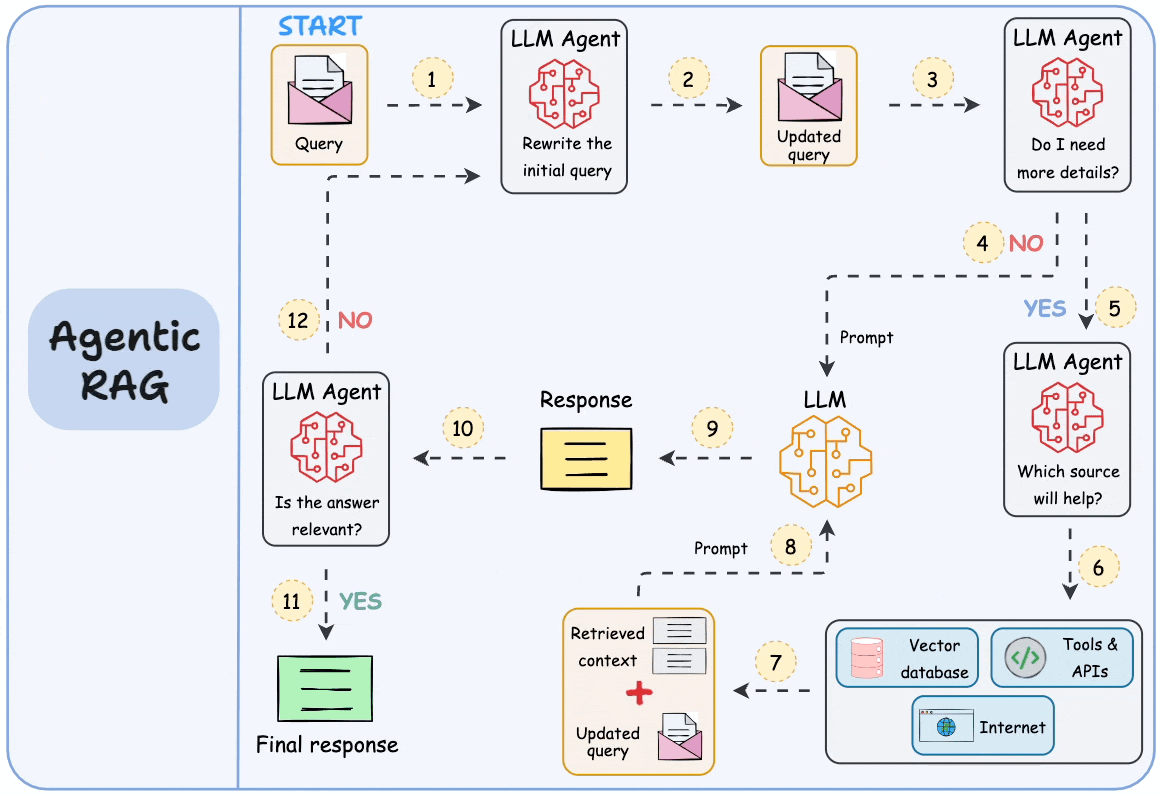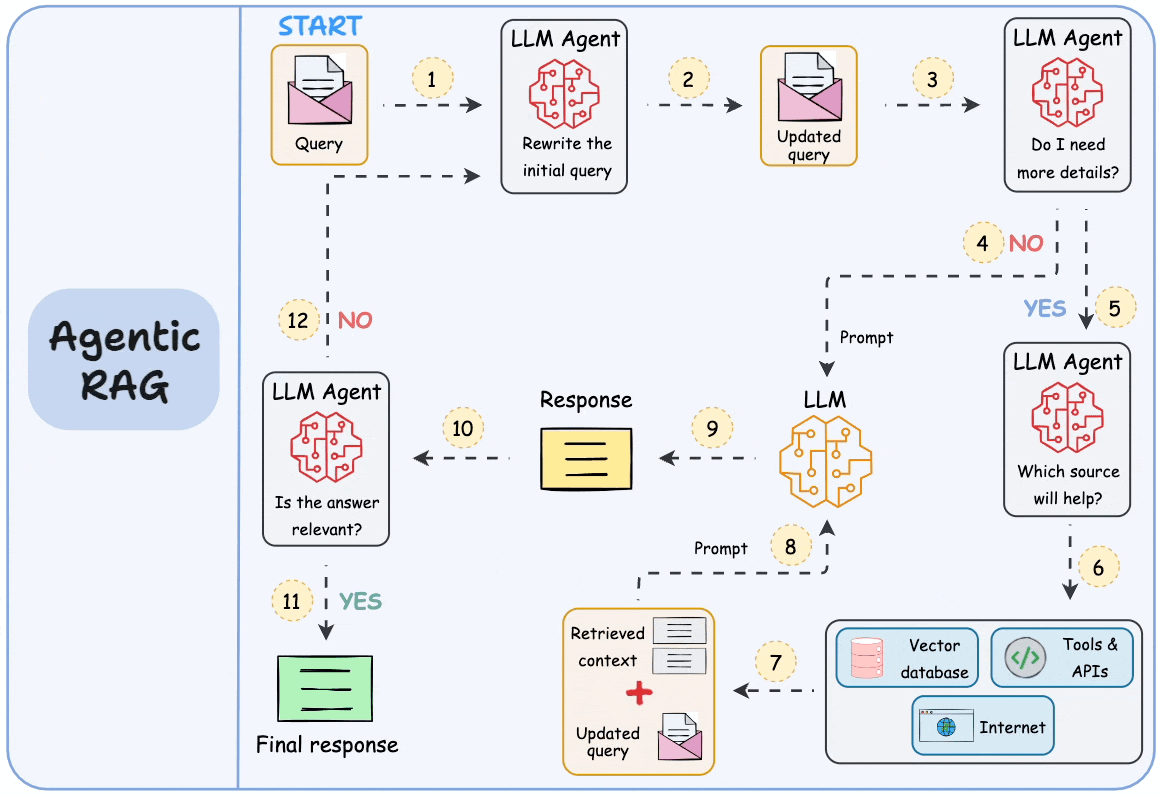
5) “Retrieve once and generate once” is a big problem with traditional RAG. Agentic RAG solves this, which we covered here →
6) Before embedding documents for RAG, we need to chunk them into manageable pieces. We covered five chunking strategies here →

7) When generating text, like in RAG systems, the LLM may need to invoke external tools or APIs to perform specific tasks beyond their built-in capabilities. Tool calling solves this, which we covered here →
8) If you are building real-world LLM-based apps, it is unlikely you can start using the model right away without adjustments. To maintain high utility, you either need, prompt engineering, fine-tuning, RAG, or a hybrid approach (RAG + fine-tuning). Learn about this here →

9) One can barely train a 3GB GPT-2 model on a single GPU with 32GB of memory. Where does the GPU memory go? Learn here →
10) Some demos for hands-on learning:
Category #2: Classical ML and Deep Learning
1) Contrastive learning is now at the core of training several machine learning systems. Learn how they are used in building Siamese Networks here →
2) Consider GraphML:
Google Maps uses graph ML for ETA prediction.
Pinterest uses graph ML (PingSage) for recommendations.
Netflix uses graph ML (SemanticGNN) for recommendations.
Spotify uses graph ML (HGNNs) for audiobook recommendations.
Uber Eats uses graph ML (a GraphSAGE variant) to suggest dishes, restaurants, etc.
Here are 6 Graph Feature Engineering Techniques →
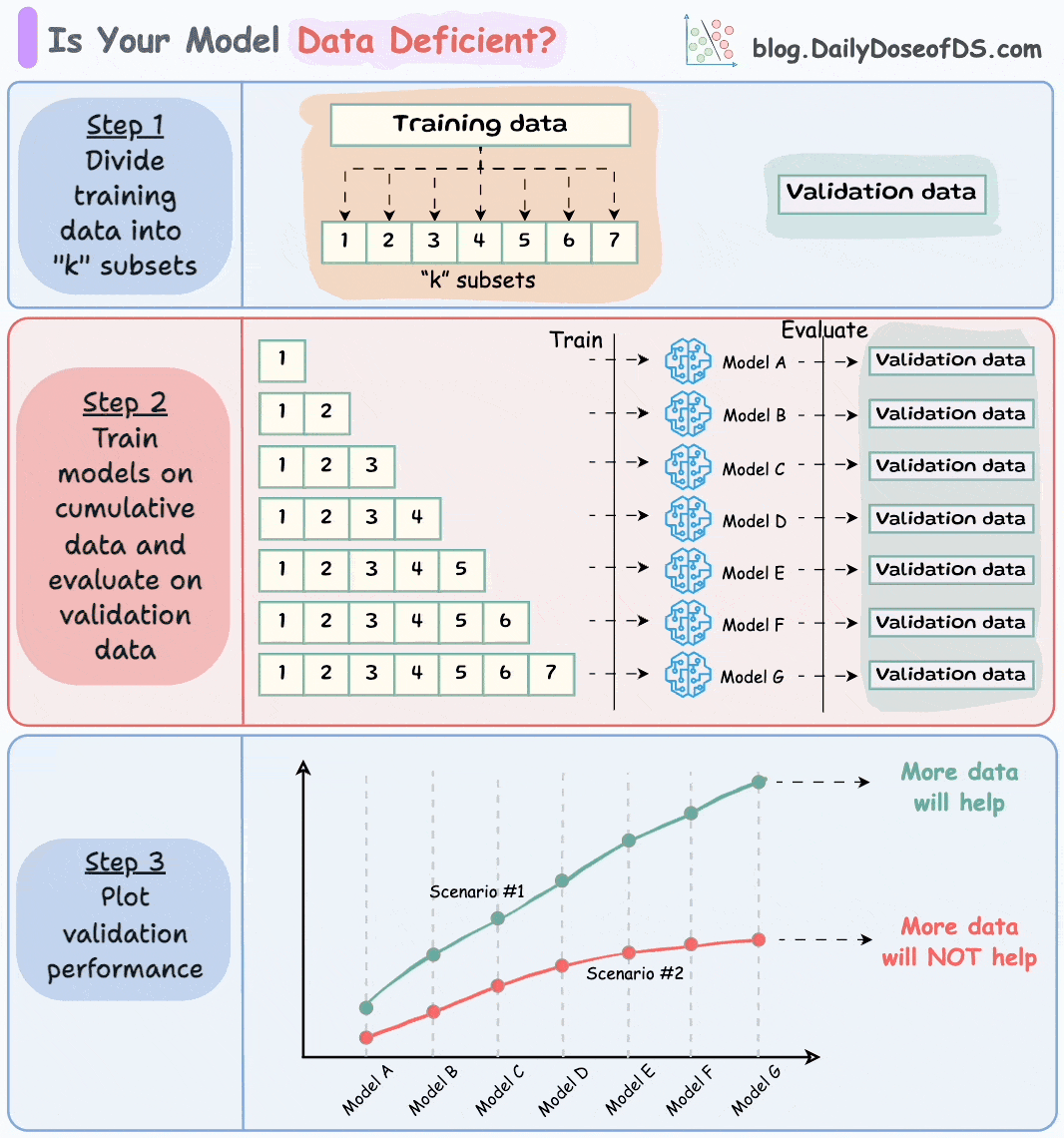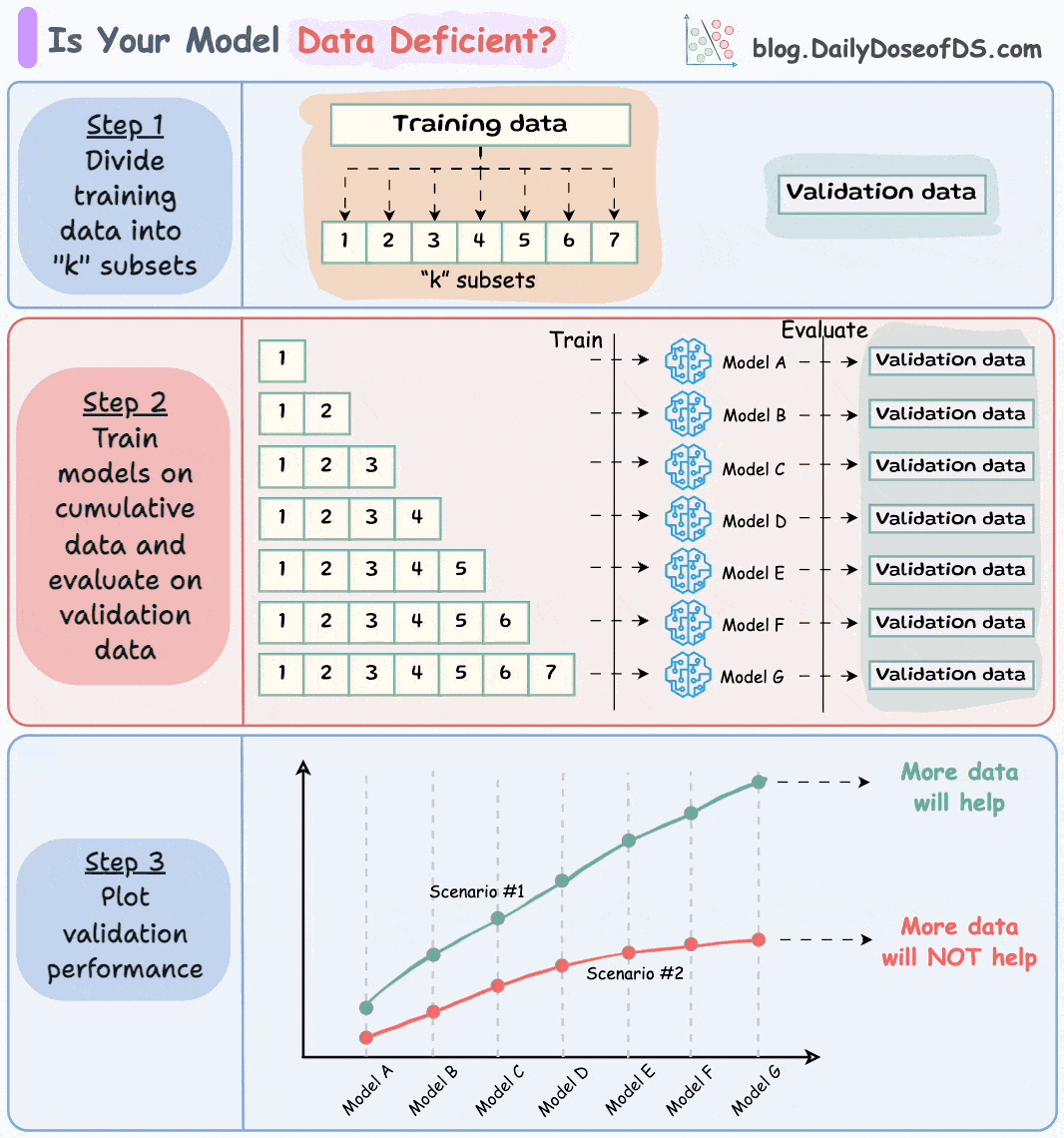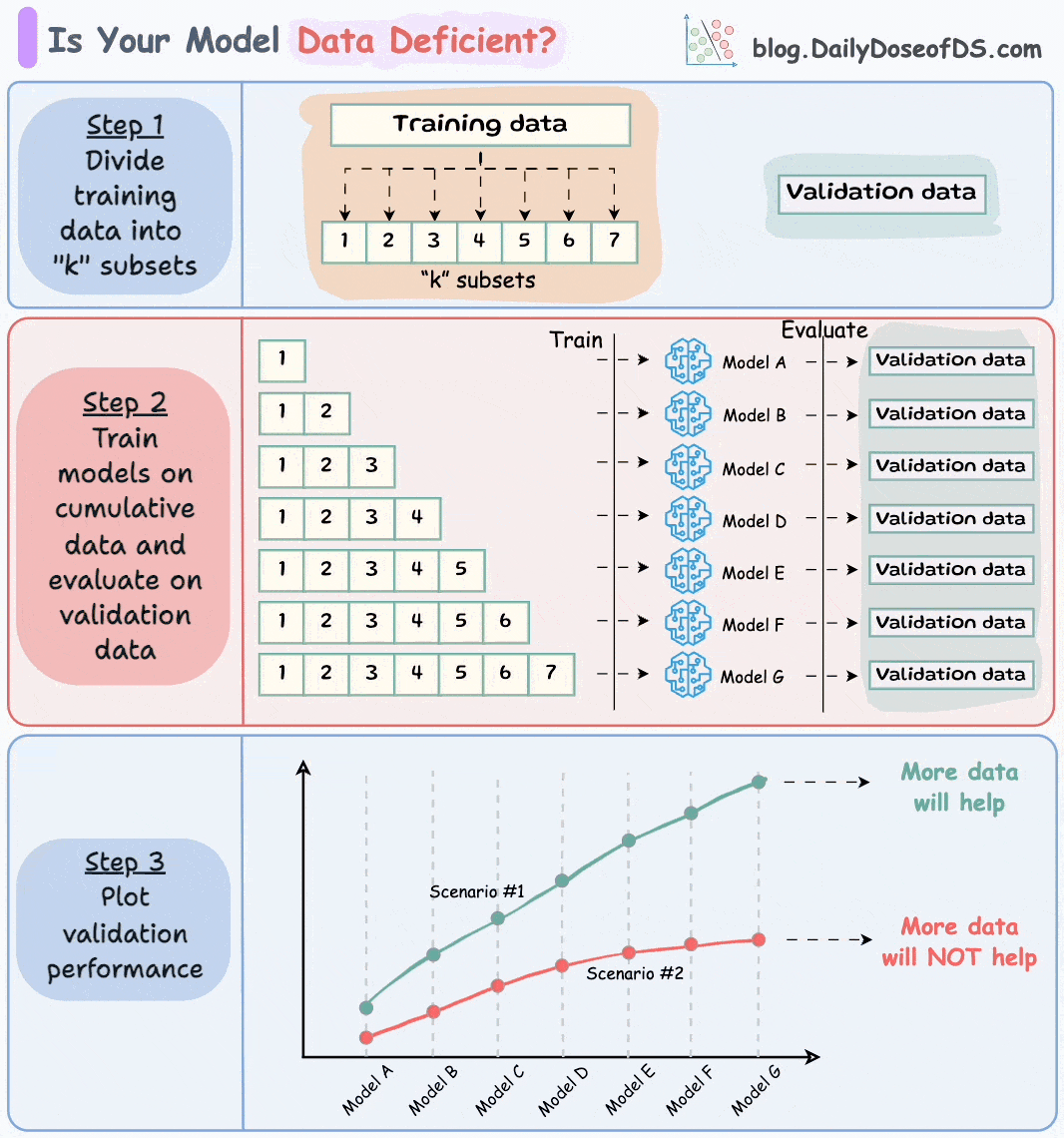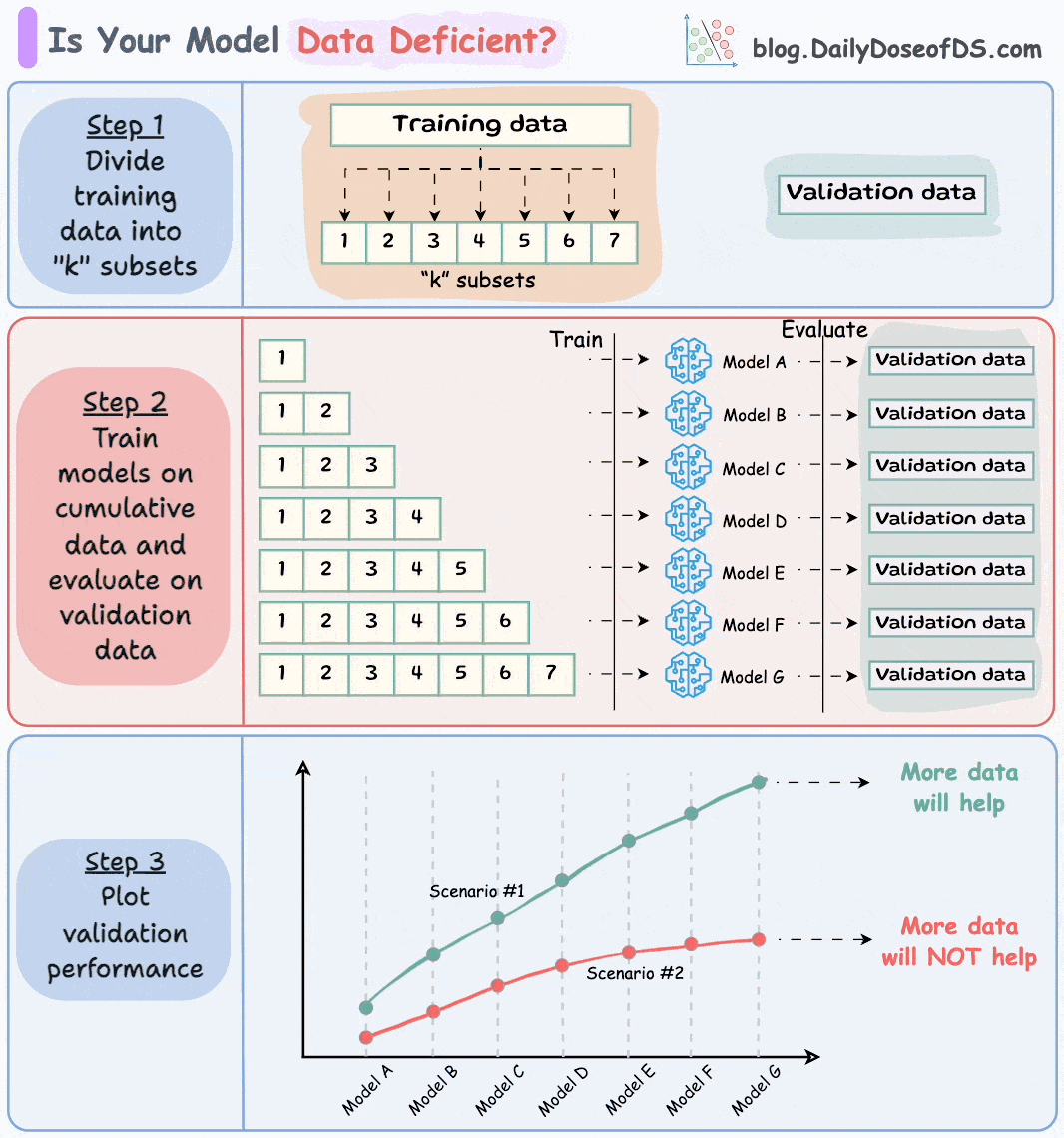
3) If you think you don't have enough data, use this technique before you start gathering more data →
4) Kernel PCA vs. PCA? Learn the difference here →
5) Sparse Random Projections can be an alternative to PCA for HIGHLY dimensional datasets. Learn how they can help here →
6) Regression models typically generate a point estimate, which, in many cases, isn’t entirely useful. Learn about Quantile Regression →

7) Active Learning is a powerful technique that lets you build the model with active human feedback on examples it is struggling with. Learn here →
8) Two techniques to use kNN on imbalanced datasets →
9) You may have heard about the kernel trick, but what is the Mathematics Behind it? Learn here →
10) Label smoothing is a lesser-known technique to regularize neural networks. Learn about it here →
Category #3: Optimization
1) 15 techniques to optimize neural network training →
2) tSNE is commonly used to visualize highly dimensional datasets, but it is slow. Here's a technique to accelerate tSNE with GPUs →
3) By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available. Here are 4 strategies for multi-GPU training →
4) Imagine representing the 32-bit model parameters using lower-bit representations, such as 16-bit, 8-bit, 4-bit, or even 1-bit, while preserving or retaining most of the information. Quantization does this →
5) Normalizing data after transferring it to GPU can be better. Here's why →
6) FireDucks is a heavily optimized alternative to Pandas with precisely the same API as Pandas. Learn how to accelerate Pandas using FireDucks →
7) Knowledge distillation is quite commonly used to compress large ML models after training. Another method, which uses a “Teacher Assistant” improves it. Learn about it here →
That’s a wrap!
A quick REMINDER
This is another reminder that lifetime access to Daily Dose of Data Science is available at 30% off.
The offer ends in 1.5 days. Join here: Lifetime membership.
The offer ends in 3 days. Join here: Lifetime membership.
It gives you lifetime access to the no-fluff, industry-relevant, and practical DS and ML resources that help you succeed and stay relevant in these roles:
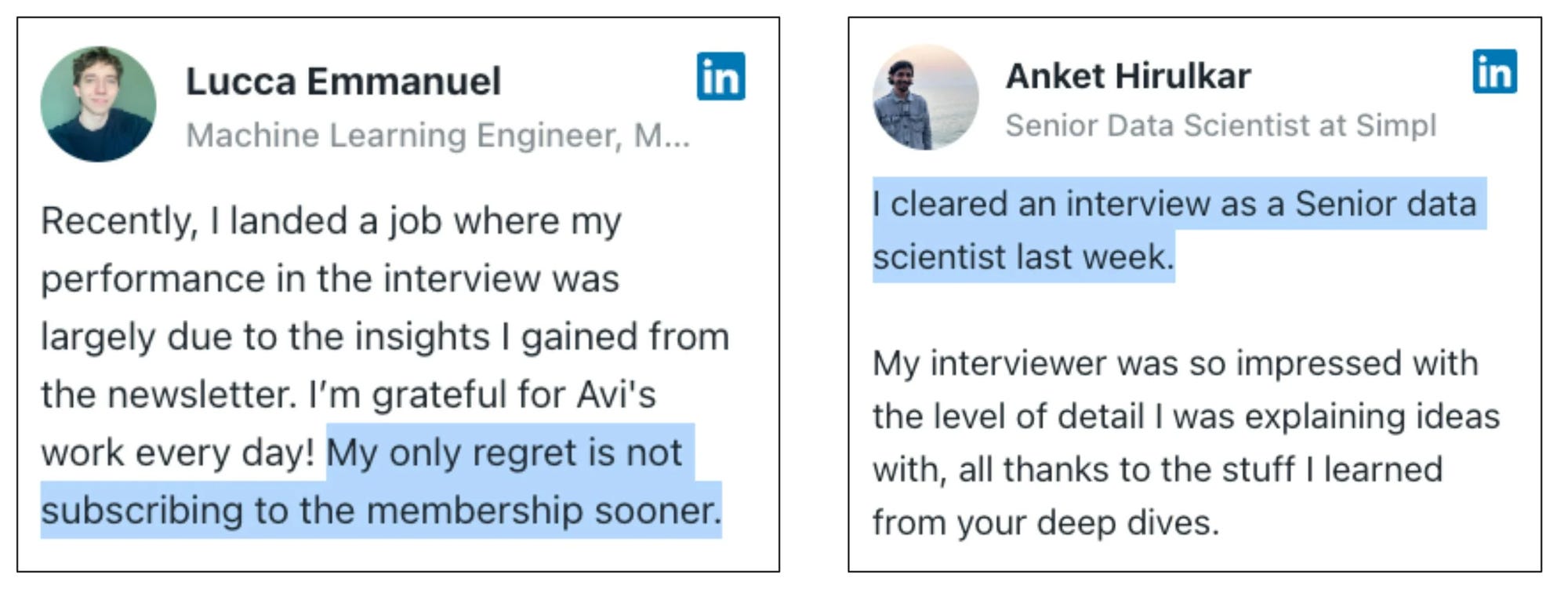
Our recent 7-part crash course on building RAG systems.
LLM fine-tuning techniques and implementations.
Our crash courses on graph neural networks, PySpark, model interpretability, model calibration, causal inference, and more.
Scaling ML models with implementations.
Building privacy-preserving ML systems.
Mathematical deep dives on core DS topics, clustering, etc.
From-scratch implementations of several core ML algorithms.
Building 100% reproducible ML projects.
50+ more existing industry-relevant topics (usually over 20 mins read covering several details).
Also, all weekly deep dives that we will publish in the future are included.
Join below at 30% off: Lifetime membership.

Our next price drop will not happen any sooner than 8-9 months. If you find value in this work, it is a great time to upgrade to a lifetime experience.
P.S. If you are an existing monthly or yearly member and wish to upgrade to lifetime, please reply to this email.